一、链表
链表是线性的,不是顺序存储的,每个节点封装成一个Node对象,Node包含两部分。

1. 节点的创建
# 链表中节点的创建
class Node(object):
def __init__(self,item):
self.item=item
self.next=None
node1=Node(1)
node2=Node(2)
node3=Node(3)
node1.next=node2
node2.next=node3
print(node1.item)
print(node1.next.item)
print(node1.next.next.item)2. 链表的创建和遍历
头插法:插到链表头部,先将节点3 和 节点2 连接,再head指向 节点3。(倒序的)

尾插法:插到尾部,先将 节点2 指向 节点3 ,再将 tail 指向 节点3。(正序的)

代码实现:
# 链表中节点的创建
class Node(object):
def __init__(self,item):
self.item=item
self.next=None
# 链表的创建:头插法——倒序
def create_linklist_head(li): # 将列表li转化为一个链表
head = Node(li[0]) # 创建节点:一开始要知道 链表的头
for element in li[1:]: # 依次遍历列表li中的数,将其插到链表中
node = Node(element) # 再创建一个节点,节点的值为element
node.next = head
head = node
return head # 将列表 转化为 链表 后,返回链表的头
# 链表的创建:尾插法——正序
def create_linklist_tail(li):
head = Node(li[0]) # 一开始要知道链表的 head 和 tail
tail = head
for element in li[1:]:
node = Node(element)
tail.next = node
tail = node
return head # 现在只能输出head,head才有 .next()
# 链表的遍历函数
def print_linklist(lk):
while lk: # 只要链表lk不是None,就可以输出数据item,并且看他的下一个节点
print(lk.item,end=' ')
lk = lk.next
# 链表的遍历
list1 = [1,2,3,4]
lk_head = create_linklist_head(list1) # 创建链表
print(lk_head.item) # 4: 返回的是链表的头head
print(lk_head.next.item) #3: 返回的是head.next
#或者
print_linklist(lk_head)
list2=[10,20,30,40]
lk_tail = create_linklist_tail(list2)
print_linklist(lk_tail)
>>> 4
>>> 3
>>> 4 3 2 1 10 20 30 40 3. 链表节点的插入和删除
列表的插入:
insert()是时间复杂度:O(n);append() 在末尾插是:O(1)
链表的节点插入:


链表的节点删除:


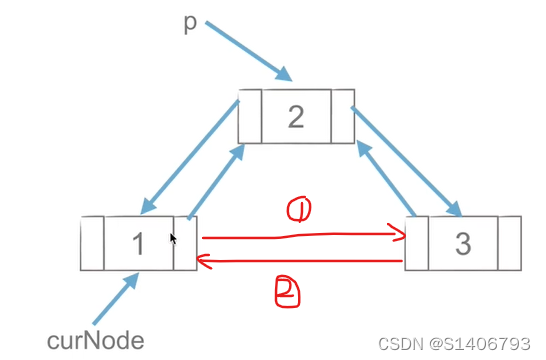
4. 双链表
双链表的每个节点有两个指针:一个指向后一个节点,一个指向前一个节点。
(1)节点的创建

(2)如何创建一个双链表 
(3)双链表节点的插入


(4)双链表节点的删除

5. 链表的总结
顺序表(列表/数组)与链表
- 按元素值查找: 时间复杂度都是 O(n)
- 按下标查找: 顺序表快,O(1); 链表是O(n)
- 在某元素后插入: 顺序表是O(n),后边的值要挪地方 ;链表是O(1)
- 删除某元素: 顺序表是O(n);链表是O(1)
- 链表在插入和删除某元素的操作上明显快于列表
- 链表的内存可以更加灵活的分配,试着用链表实现栈和队列---双链表存一个头节点、尾节点,然后进行操作。
- 链表这种 链式存储的数据结构 对 图和树 的结构有很大启发性
二、哈希表
python的字典、集合都是它实现的。
哈希表是一个通过哈希函数来 计算数据存储位置的数据结构,操作如下:
- insert(key, value):插入键值对(key,value)
- get( key ) :如果存在键为key的键值对,则返回value,否则返回None
- delete(key):删除键为key的键值对
1、 直接寻址表

全域U:所有键key 可能出现的集合,例如身份证号是18位,那个T就是18个元素,需要一个2^18的列表。
在 T 中插入、查找、删除:
- 插入、查找:如果给插入 (K=5,value=a) ,则给T的下标5 赋值即可;查找也就是直接在T中找对应下标。
- 删除:T中对应位置置成None

| 1. U很大,例如U有18位数,那么就需要2^18的列表,内存太大。 |
| 2. U是1~1000的数,但是实际能出现的Key很少,T中斜杠(None)很多 |
| 3. Key不是数字,是字符串的时候,不能用。 |
2、 哈希
直接寻址表: key为k的元素放到k的位置上
改进直接寻址表:哈希(hashing)
- 构建大小为m的寻址表 T
- key为k的元素放到 h(k) 的位置上
- h(k) 是一个函数,其将域U 映射到表 T[ 0,1,......,m-1 ]
- h(k) 的范围就是 0到 m-1
1. 哈希表(Hash Table,又称为散列表)
是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。
- 哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。

但是如果下标0处已经存储到一个值,我们还能再存储吗?这时候就得提到 哈希冲突的概念。

![]()
2. 解决哈希冲突——开放寻址法、拉链法
(1)开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置 i 被占用,则探查i+1 , i+2 , ...... 。直至找到这个值,或者找到空位,找到空位说明这个值不存在。这三个方法都不太好,了解即可。
(2)拉链法
哈希表中的每个位置不是存储一个值,是存储一个链表。当冲突发生时,冲突的元素将被加到该位置链表的最后。
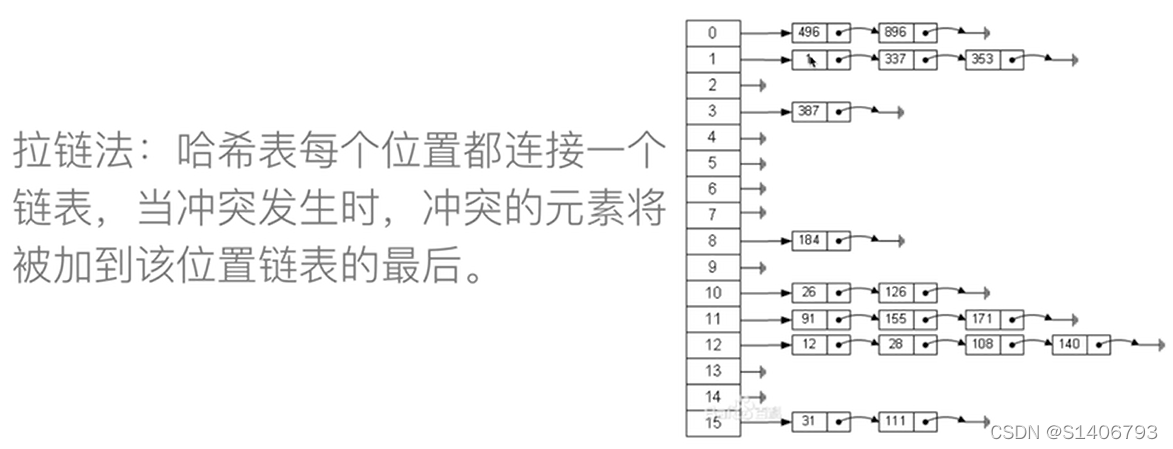
插入: 如果对应位置空直接插入;如果有值,采用头插法、尾插法 将值插在链表头部或者尾部
查找:找到对应的链表,对其进行遍历
删除:先找到再删除,O(1)
查找速度:没有直接寻址表快,但是浪费空间小。
3. 常见哈希函数
| 除法哈希法 | h(k) = k % m |
| 乘法哈希法 | h(k) = floor( m *( A * key % 1 ) ) A是一个小数,对1取余数是指取小数部分;floor是向下取整。 |
| 全域哈希法 |
3、 哈希表的实现
哈希表要使用拉链法,所以我们先封装一个链表,可以实现 插入、查找、迭代打印。链表的插入和查找。
# 封装一个链表:可以插入append/extend、查找find
class LinkList:
class Node:
def __init__(self,item=None):
self.item = item
self.next = None
# 创建一个迭代器类:支持__next__
class LinkListIterator:
def __init__(self,node): # 传入了头节点self.head
self.node = node
def __next__(self):
if self.node: # 如果node不是空: 即传入了self.head
cur_node = self.node # 把self.node先保存在cur_node中
self.node = cur_node.next # 更新node,self.node指向下一个节点
return cur_node.item # 输出前一个node的值,即传入的head值
else: # 如果传入的head(node)是空
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None): # iterable 是一个列表
self.head = None
self.tail = None
if iterable: # 给一个非空列表iterable,就调用extend函数:循环插入节点
self.extend(iterable)
#链表的插入(插入某个节点,列表中的某个值)
def append(self, obj): # obj是要插入的对象
s = LinkList.Node(obj) # 创建一个节点,节点的值是obj
if not self.head: # 一开始链表的head是空,所以他的head和tail都是新节点s
self.head = s
self.tail = s
else: # 如果一开始链表中不空,尾插法,在tail后面插入新节点s
self.tail.next = s
self.tail = s
# 链表后插入多个节点(一个列表)
def extend(self, iterable): # extend就是往链表后接一个列表iterable,那么就是循环调用qppend即可
for obj in iterable:
self.append(obj)
# 链表中查找某个节点
def find(self, obj): # 查找,哈希表中:在链表里查找-for循环
for n in self: # self表示创建的实例对象,self 本来是迭代的,所以可以用for循环
if n == obj:
return True
else:
return False
def __iter__(self): # __iter__用来写迭代器的,列表支持for循环,但是链表不支持。
return self.LinkListIterator(self.head) # 调用迭代器类,传入头节点head
# 有了__iter__函数和LinkListIterable类,相当于一个可迭代对象
def __repr__(self): # 打印的时候,装化成字符串,直接打印
return "<<" + ",".join(map(str, self)) +">>" # self是迭代的,并且是一个整数,不是字符串
链表封装好之后,我们正式开始哈希表的实现:在哈希表中查找和插入某个值;
class LinkLinst:... # 链表类
# 在哈希表中实现 插入和查找。 哈希表是一个类似于集合的结构
class HashTable:
def __init__(self,size=101):
self.size = size
# 给出列表T,T的每个位置保存一个链表,用LinkList创建一个链表对象
self.T = [LinkList() for i in range(self.size)]
def h(self,k): # 哈希函数
return k % self.size
# 哈希表的插入功能:插入k值
def insert(self,k):
i = self.h(k)
if self.find(k): # 如果在T[i]链表里找到k
print('Duplicated Insert.')
else:
self.T[i].append(k)
# 哈希表的查找功能:查找值k 是否在T的对应链表里,如果已经存在就不再插入。
def find(self,k):
i =self.h(k)
return self.T[i].find(k) # T[i]是一个链表,链表有 查找 的功能
ht = HashTable()
ht.insert(0)
ht.insert(1)
ht.insert(3)
ht.insert(102)
ht.insert(508)
print(",".join(map(str,ht.T)))
print(ht.find(203))
>>> <<0>>,<<1,102>>,<<>>,<<3,508>>,<<>>,<<>>, ....
>>> False4. 哈希表的应用——python中字典和集合的实现
使用哈希表存储字典,通过哈希函数将字典的键映射为下标:



