分区
1.在MR中partitioner将Mapper产生的中间结果进行分区,然后将同一组数据提交给一个Reducer中处理
2.partitioner默认调用的是Hashpartitioner,用它来把数据分组然后发送给不同的reducer
3.计算公式:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks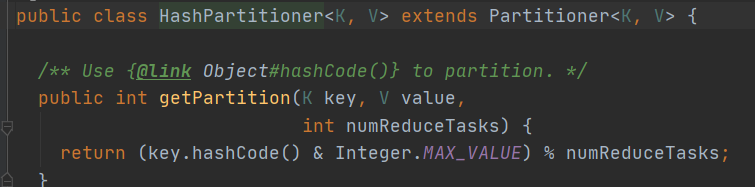
实现分区:
1.继承Partitioner<key, value>,泛型为mapper输出的key和value,
重写getPartition方法,返回的就是分区号
2.在Driver类中指定partition类
3.在Driver类中指定reducetask个数
总结
1. 默认的reducetask数量为1,分区号从0递增
2. 如果分区数量小于设置的reducetask数量(reducetask数量>1),那么会产生多余的空文件
3. 如果分区数量大于设置的reducetask数量(reducetask数量>1),可能会有部分分区找不到reduce提交数据,出现异常
4. 如果reducetask 数量不指定(默认为1),或者数量指定为1(job.setNumReduceTasks(1)),这两种情况都不会执行分区规则
排序:
MR中分区后
key默认的行为有两个:
1.具有序列化反序列化
2.排序
默认是字典顺序,使用快排
而value只需要有序列化和反序列化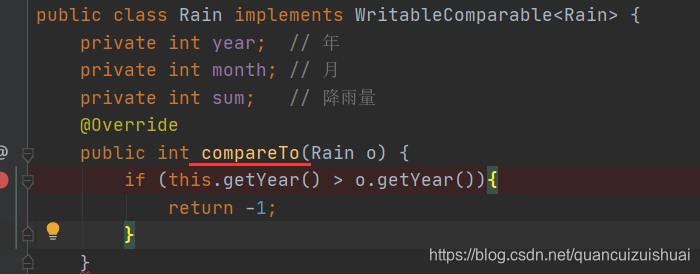
对象实现自定义排序的两种方法:
1.实现WritableComparable<>接口,重写compareTo()方法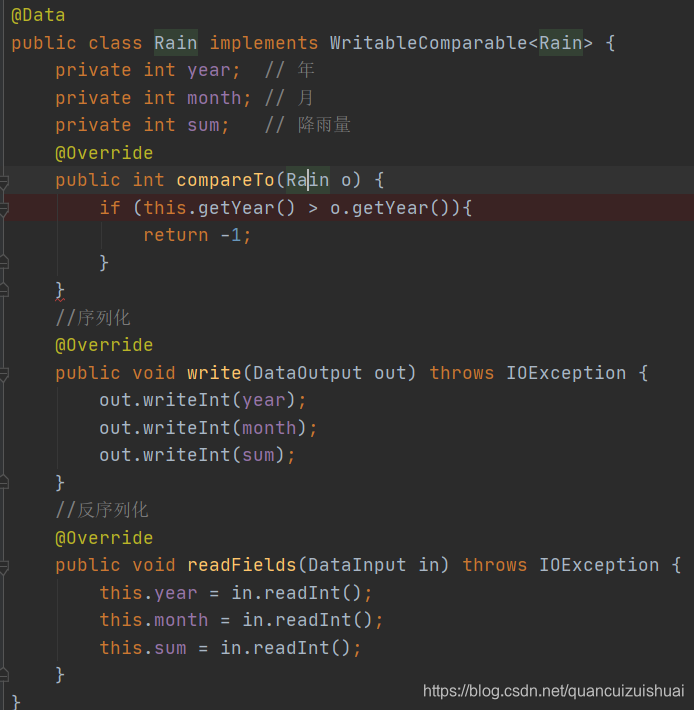
2.自定义比较器继承WritableComparator类,父类构造方法需要增加比较的对象,重写compare()方法
并且需要在Driver中指定job.setSortComparatorClass(比较器类)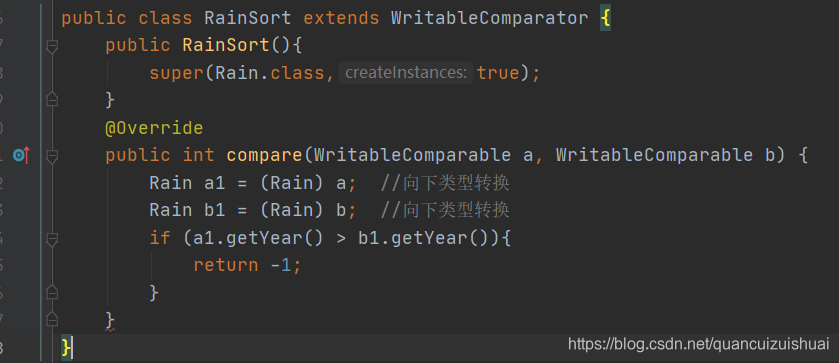
总结:
1.如果对象实现自定义排序,必须实现WritableComparable<>接口(或者说把自定义类当作mapper输出的key来使用,必须重写这个接口)
2.如果自定义比较器并且指定比较器类但是没有重写compare方法,默认还是调用对象中的compareTo()方法
3.如果自定义比较器并且指定比较器类和重写compare方法,就不会调用对象中的compareTo()方法了
对于总结的一些的解释
通过debug模式发现会优先调用 compare方法(在WritableComparator类中)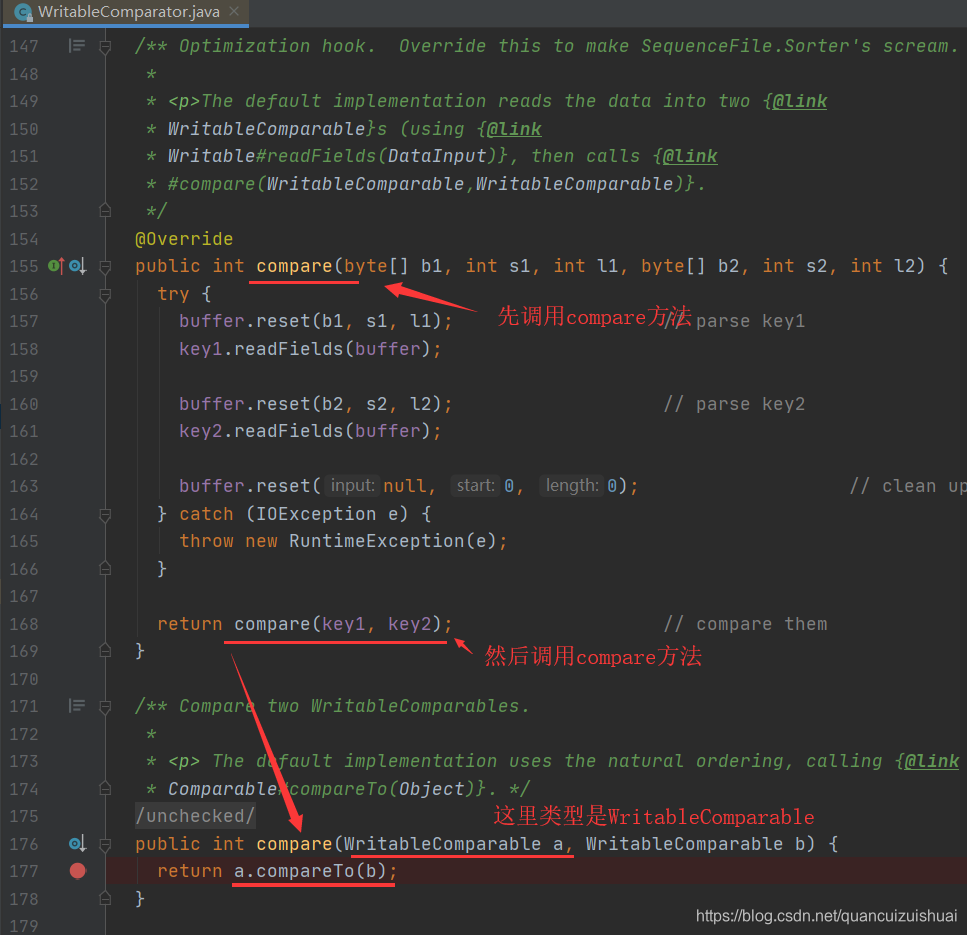
实际上这里最后调用的compareTo方法是在实体类中实现WritableComparable<>接口,重写的compareTo()方法(如果实体类不继承WritableComparable<>接口,运行到这里就会出现类型转换异常)
但如果满足第三条就不会调用上图的compare方法,而是调用重写过的compare方法,这时,如果实体类(对象类)继承的不是WritableComparable<>,这里super调用父类方法会出错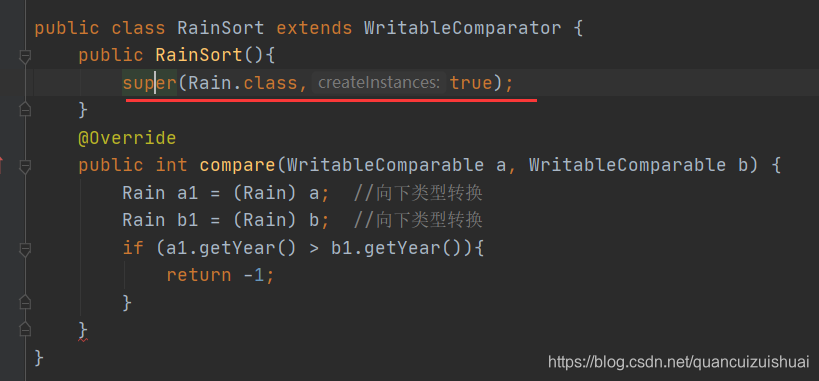
我们进入到super中
更改下实体类实现的接口就会发现类型不匹配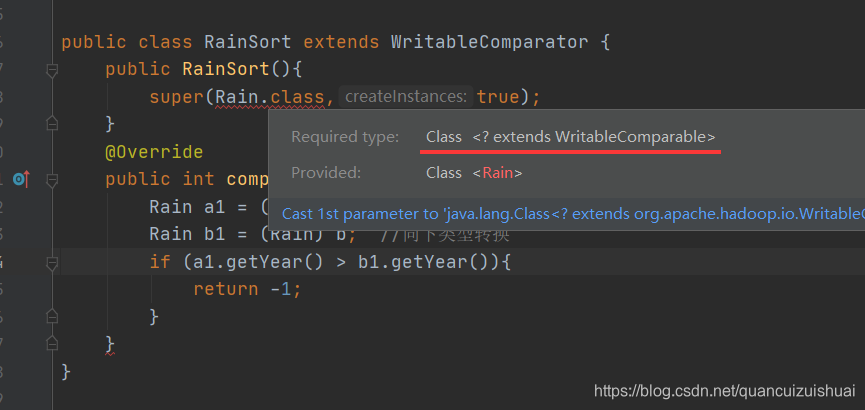
所以:
如果把自定义类当作mapper输出的key来使用,必须实现WritableComparable<>接口
分组
在最后一个归并排序后进行的分组,也就是在提交给reduce之前进行的
自定义分组和排序相似:
都是继承WritableComparator类
构造函数中指定分组的类型
重写compare方法
1.分组不会改变数据结构
2.分组决定了哪些数据一起进入迭代器
默认的分组是以mapper输出的key相同的为一组的value传给reduce,而自定义分组是以我们指定的规则为一组的 value传给reduce
TopN
实际上就是利用自定义排序和自定义分组然后取前N个数据
下面是一个温度案例:
找出每个月温度最高的两天并根据月份分别写到不同的文件中
源数据如下:
date time temperature
2012-9-14 14:37:12 25C
2019-12-8 14:37:12 24C
2017-3-10 14:37:12 32C
然后对其进行分析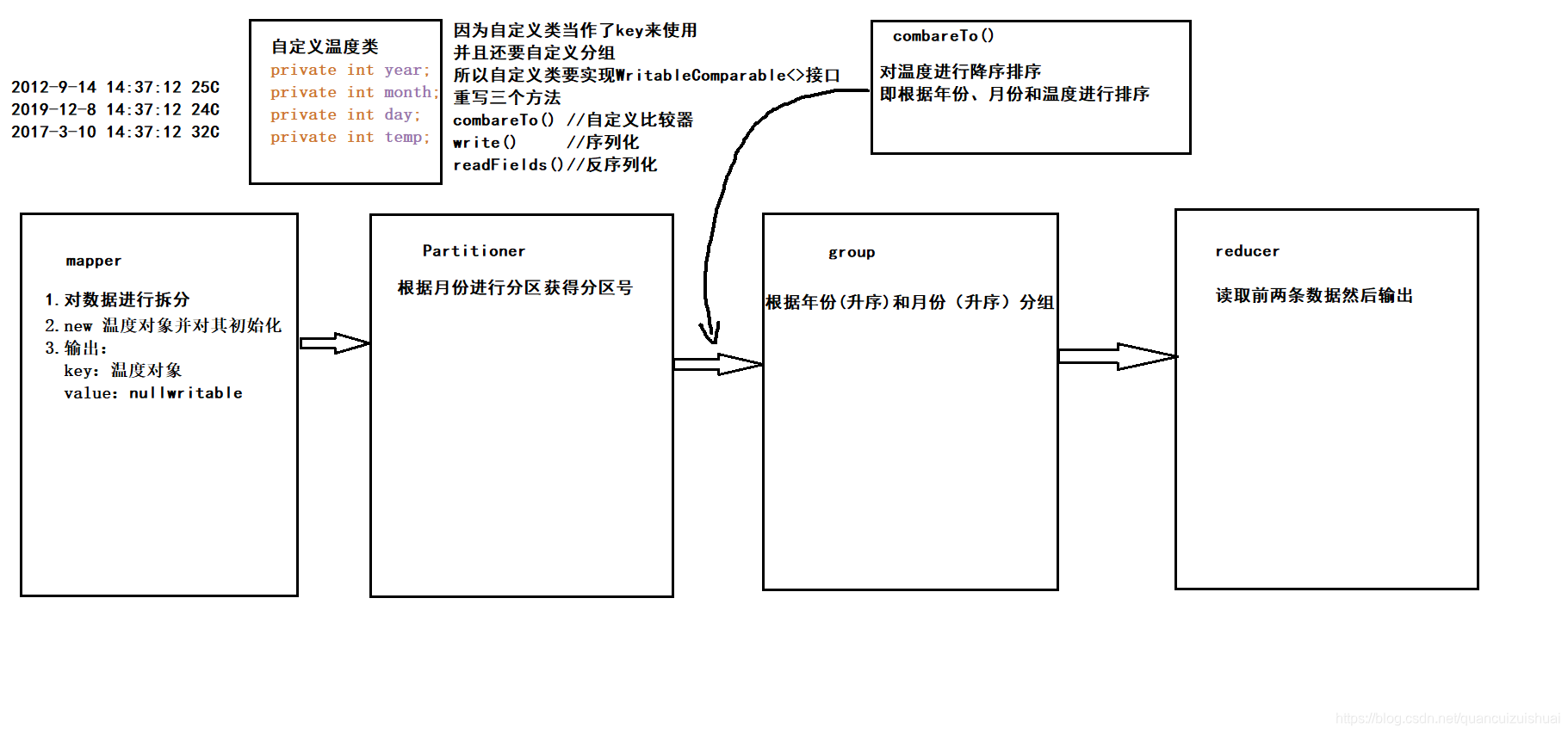
下面是具体代码
Temperatrue类
package com.bd2001.partition_sort_group;
import lombok.Data;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Data
public class Temperature implements WritableComparable<Temperature> {
//2019-10-1 12:23:22 33c
private int year;
private int month;
private int day;
private int temp;
public String toString(){
return year+"-"+month+"-"+day+"\t"+temp+"C";
}
/**
* 根据年份与月份按照升序排列、以温度降序排列
* @param o
* @return
*/
@Override
public int compareTo(Temperature o) {
if(this.getYear() == o.getYear()){
if(this.getMonth() == o.getMonth()){
return -Integer.compare(this.getTemp(),o.getTemp());
}else{
return Integer.compare(this.getMonth(),o.getMonth());
}
}else{
return Integer.compare(this.getYear(),o.getYear());
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(year);
out.writeInt(month);
out.writeInt(day);
out.writeInt(temp);
}
@Override
public void readFields(DataInput in) throws IOException {
this.year = in.readInt();
this.month = in.readInt();
this.day = in.readInt();
this.temp = in.readInt();
}
}
mapper
package com.bd2001.partition_sort_group;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class TemperatureMapper extends Mapper<LongWritable, Text,Temperature, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取每一行数据进行分割并写到对象中输出出去
//2019-10-1 12:23:22 33c
Temperature temperature = new Temperature();
String[] str = value.toString().split("\t");
String[] date = str[0].split("-");
String temp = str[2].substring(0,str[2].length()-1);
temperature.setYear(Integer.parseInt(date[0]));
temperature.setMonth(Integer.parseInt(date[1]));
temperature.setDay(Integer.parseInt(date[2]));
temperature.setTemp(Integer.parseInt(temp));
System.out.println(temperature);
context.write(temperature,NullWritable.get());
}
}
partition
package com.bd2001.partition_sort_group;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class TemperaturePartitioner extends Partitioner<Temperature, NullWritable> {
@Override
public int getPartition(Temperature temperature, NullWritable nullWritable, int numPartitions) {
//按照月份分区
//0区-1月
//1区-2月
//。。。
//11区-12月
return (temperature.getMonth()-1)%12;
}
}
group
package com.bd2001.partition_sort_group;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class TemperatureGroup extends WritableComparator {
public TemperatureGroup (){
super(Temperature.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//根据年份与月份分组
Temperature t1 = (Temperature) a;
Temperature t2 = (Temperature) b;
//if(t1.getYear() == t2.getYear()){
//return Integer.compare(t1.getMonth(),t2.getMonth());
// }else{
return Integer.compare(t1.getYear(),t2.getYear());
// }
}
}
reducer
package com.bd2001.partition_sort_group;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class TemperatureReducer extends Reducer<Temperature, NullWritable,Temperature,NullWritable> {
@Override
protected void reduce(Temperature key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//读取按照年份和月份分组之后的同月中温度最高的前两天
int flag = 0;
Temperature t1 = key;
Temperature temperature = new Temperature();
try {
for (NullWritable value : values) { //因为已经排序好,直接提取前两个数据
BeanUtils.copyProperties(temperature,key);
if(flag == 1 && key.getTemp() == temperature.getTemp()){
continue;
}
context.write(temperature,NullWritable.get());
flag ++;
if(flag > 2){
break;
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
驱动类Driver
package com.bd2001.partition_sort_group;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TemperatureDriver {
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration,"Temp_test");
//设置驱动类
job.setJarByClass(TemperatureDriver.class);
//设置map类
job.setMapperClass(TemperatureMapper.class);
//开启map压缩
configuration.setBoolean(job.MAP_OUTPUT_COMPRESS,true);
//指定压缩类型
configuration.setClass(job.MAP_OUTPUT_COMPRESS_CODEC, GzipCodec.class, CompressionCodec.class);
//设置reduce类
job.setReducerClass(TemperatureReducer.class);
//设置partition类
job.setPartitionerClass(TemperaturePartitioner.class);
//设置输出
job.setMapOutputKeyClass(Temperature.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Temperature.class);
job.setOutputValueClass(NullWritable.class);
//设置group类
job.setGroupingComparatorClass(TemperatureGroup.class);
//设置reducetask个数
job.setNumReduceTasks(12);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("D:/temp_in"));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path("D:/temp_out"));
//提交任务
job.waitForCompletion(true);
}
}