关注公众号,发现CV技术之美
▊ 写在前面
在本文中,作者将传统的视频字幕任务转换为一个新的范式,即开放式视频字幕,它在视频内容相关句子的提示下生成描述,而不限于视频本身。
为了解决开放式视频字幕问题,作者提出了一种新的基于“检索-复制-生成”的网络,构建了可插入的视频-文本检索器(pluggable video-to-text retriever) ,有效地从训练语料库中检索句子,并引入了基于复制机制的生成器(copy-mechanism generator) ,动态地从检索的句子中生成描述。
这两个模块可以进行端到端或者单独的训练。本文的框架将传统的基于检索的方法与Encoder-Decoder方法进行协调,不仅可以利用检索句子中的不同表达,还可以生成自然准确的视频内容。在几个基准数据集上进行的大量实验表明,本文所提出的方法超过了以前的SOTA性能,证明了本文所提出的范式在视频字幕任务中的有效性和前景。
▊ 1. 论文和代码地址

Open-book Video Captioning with Retrieve-Copy-Generate Network
论文地址:https://arxiv.org/abs/2103.05284
代码地址:尚未开源
▊ 2. Motivation
视频字幕(Video Captioning)的任务需求是根据视频中的视觉内容自动描述出视频中发生了什么。目前解决这一任务的方法主要集中于学习视频的时空表示,充分利用视觉信息,设计新的解码器,来实现视觉-文本对齐或可控的解码。总的来说,大多数现有的工作都存在几个缺点:
1)首先,由于视频内容是唯一的输入源,因此生成过程缺乏适当的引导,导致产生非常泛化的句子而非有辨别性的句子。
2)其次,模型的知识领域在训练后是固定的,如果不再次训练,就不能扩展到新的知识中。
为了解决这些问题,作者提出了一个开放式的视频字幕范式 。为了更好地说明,作者首先比较了两个跨模任务:视频文本检索(VTR)和视频字幕(VC)。VTR是一项鉴别的任务,可以始终访问视觉和文本模态的所有信息;VC是一项生成的任务,只能基于当前生成的单词和视觉信息生成单词。
作者在本文中没有直接执行VC任务,而是将其转换为两个阶段:首先执行VTR,从文本语料库中搜索与给定视频相关的句子;然后,利用检索句子作为额外的提示来生成标题 。在推理过程中,生成器可以根据视频内容生成单词,或直接从检索到的句子中复制合适的单词。灵活的VTR和可变的语料库为模型的扩展和修改提供了可能性。
这种机制从本质上扩展了仅从标注的数据中学习到模型的知识领域。标注数据是极其费力和费时的;而本文的模型通过学习收集相关的reference,区分有用的提示,从外部弱标注或未标注的文档中总结有用的信息,打破了标记数据的局限性。
与传统的半监督学习直接使用固定的弱标注或无标注的样本进行训练不同,本文提出的范式使模型学习直接从可变的弱标注或无标注语料库中提取有用的信息进行推断。
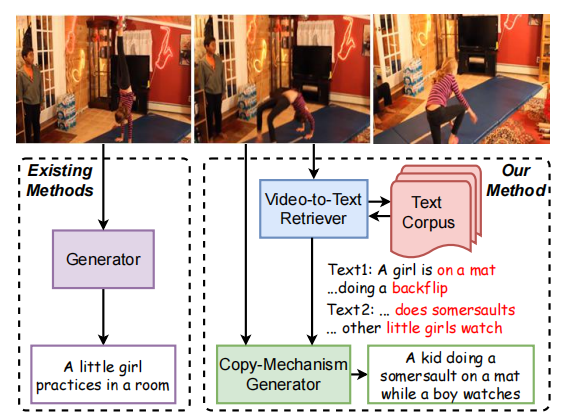
为了实现上述的开放式视频字幕,作者引入了一种**“检索-复制-生成”(Retrieve-Copy-Generate,RCG)** 网络。在本文中,检索器遵循Bi-encoders的结构,并利用视频的动作和外观特征来搜索所需的句子。(如上图所示,检索到的句子中的 “on a mat”, “does somersaults”和 “someone watches”能够准确的描述视频的内容,所以这些单词就不需要重新生成了。 )
然后,将检索到的句子和视觉特征输入到生成器。这是一个复制机制生成器(copy-mechanism generator),它能动态地决定是直接从检索到的句子中复制表示的单词,还是根据视频内容来生成新词。
该模型结合了来自视频内容的信息和从检索中复制的单词,因此生成了最终的标题“A kid doing a somersault on a mat while a boy watches”,这比一般模型生成的标题“A little girl practices in a room”要好得多。
▊ 3. 方法
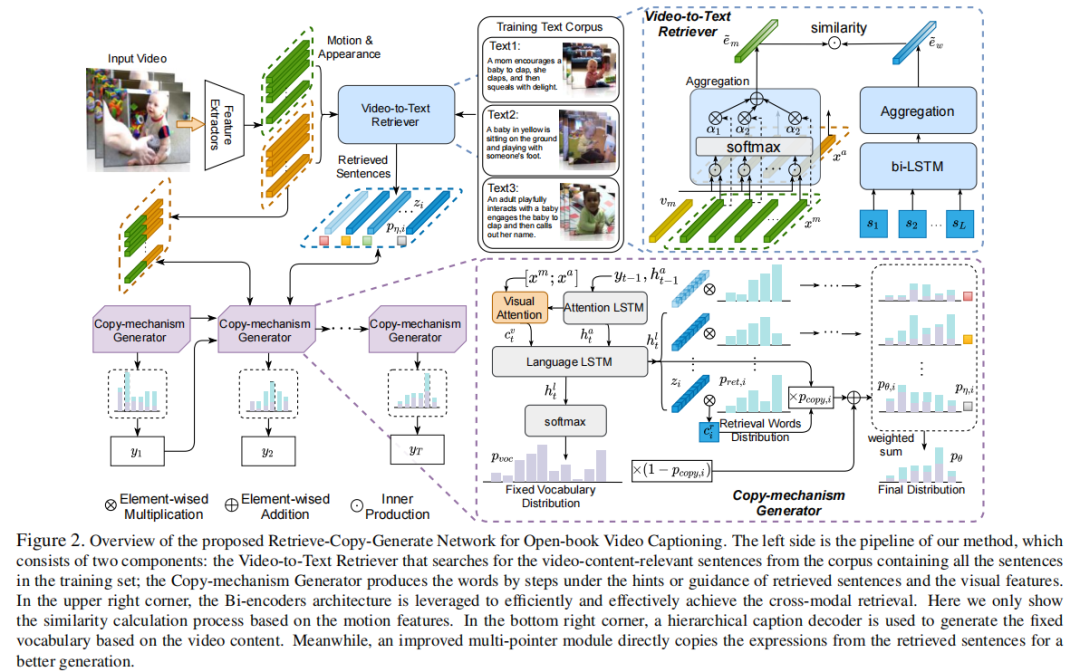
上图展示了本文提出了检索-复制-生成(RCG)的框架,主要分为两部分:
1)从视频到文本的检索器,用于根据视频x检索top-k个语义相似的句子z;
2)基于复制机制的生成器,它利用上述检索到的句子z、原始视觉信息x和之前的生成的t−1个token来生成当前的目标token 。在形式上,RCG方法产生视频字幕的条件概率定义如下:
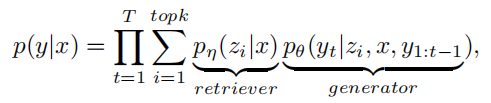
其中,y是带有N个token的目标句子。
因为一个数据集通常包含在语义上相似的视频,这些句子具有相似的表示。因此,检索到的top-k句子z可以提供与视频内容x相关的信息,以帮助生成器更准确地生成句子。同时,可以被视为一个阈值,代表生成器是否可以直接从检索句子中复制单词的置信度。
3.1. Effective Video-to-Text Retriever
检索器的主要功能是在一个大型检索语料库Z中找到给定视频x的最相似的句子z。|Z|需要足够大,可以理想地覆盖所有的视频内容(本文中语料库包含近30万个句子),而k通常很小,比如1∼30。
视频到文本检索器采用双编码器(Bi-encoders)架构:文本编码器将语料库Z中的所有句子映射到d维向量中,构建一个候选数据集;视觉编码器视频x映射一个d维向量作为query。整个检索模型通过度量学习进行训练,它将视觉和文本模式嵌入到一个联合的高维语义空间中。将视频与文本之间的相似性定义为其embedding向量的点积:
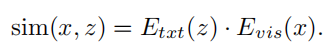
通过将相似度进行排序,与输入视频最接近top-k个句子就被检索器得到了。
3.1.1. Textual Encoder.
给定一个句子,每个单词首先被输入到一个bi-LSTM,以生成一个d维上下文感知的单词embedding序列,:
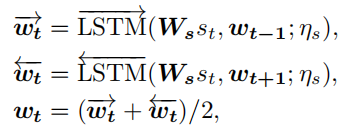
其中是一个可学习的单词embedding矩阵,表示LSTM的参数。
然后,所有的embedding都被聚合到单个向量中,作为整体表示。我们将聚合函数表示为,它利用乘法注意机制,其中参数可以被视为一个可学习的核心,给予更区别的特征更高的权重。
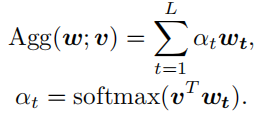
因此,单词embeddings通过将其聚合到单个向量中,其中是单词聚合函数的参数。
3.1.2. Visual Encoder.
作者假设外观特征和动作特征共同构成了视频x的表示。每个特征都是通过线性变换为d维的特征。
对于视觉编码器,作者根据不同时刻的重要性直接聚合这些特征,动作特征用于辨别视频中的顺序信息,而外观特征用于区分视频中的对象。
作者通过聚合运动embedding,并通过)聚合外观embedding,其中是两种模态的聚合函数的参数。
将外观、动作和文本相似度的平均值作为最终的视频-文本相似性(这里采用的是余弦相似度):
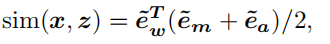
是L2标准化的操作。
3.1.3. Pre-training and Retrieval.
跨模态检索器的训练遵循对比学习,其中每个正对(x+,z+)应该比任何其他负对(x+,z−)和(x−,z+)更接近,损失函数如下:
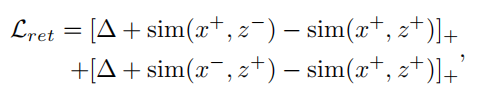
其中,和为松弛系数。小批量中属于其他视频的句子都是本视频的负样本,反之亦然。
由于双编码器的独立结构,文本embedding可以提前离线计算,保存到本地,以进行高效的评估。
给定视频x作为query,检索到top-k个匹配的句子之后,每个句子的概率估计为:
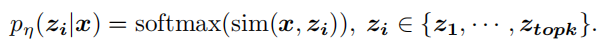
3.2. Copy-mechanism Caption Generator
为了基于视频内容和检索到的句子生成字幕,作者设计了一种基于复制机制字幕生成器( copy-mechanism caption generator),它由层次标题解码器(Hierarchical Caption Decoder)和动态多指针模块(Dynamic Multi-pointers Module)组成。
3.2.1. Hierarchical Caption Decoder
层次标题解码器(Hierarchical Caption Decoder)由注意力LSTM和语言-LSTM组成。
注意力LSTM根据当前隐藏状态来关注不同的视觉特征,以获取视觉上下文,其中是特征维度中两组特征的concat操作。注意力LSTM的当前隐藏状态取决于之前的隐藏状态和生成的单词:
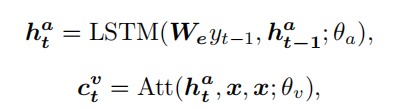
其中表示参数为θ的标准加法注意模块;是单词embedding矩阵。
然后,语言LSTM聚合当前状态和视觉上下文,来生成每个时间步的词汇表的概率分布:
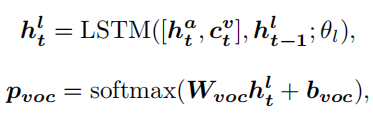
3.2.2. Dynamic Multi-pointers Module
在前面,我们已经得到了与给定视频最相似的top-k个句子。作者利用将这些检索到的句子编码为。每个检索到的句子都包含一组单词及其embedding。
为了利用多个检索到的句子中的表达,作者提出了多指针模块。在每个解码步骤t中,多指针模块分别作用于每个检索到的句子,使用隐藏状态作为query来参attend到L个单词,并生成相应句子的单词概率分布
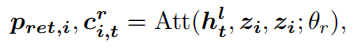
其中,是加法注意模块;表示检索到的句子的上下文,即用对的加权总和。由于检索到的句子中,不是所有单词都是有效的,因此模型需要决定是复制单词还是生成新的单词。从每个检索到的句子中复制单词的概率由检索到的句子的语义上下文和解码器的隐藏状态共同决定:
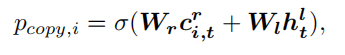
最后,生成概率分布计算如下(也就是在生成单词和复制单词的概率分布前面分别在乘上一个概率后求和):
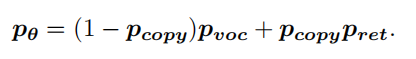
3.3. Training
目标词的最终概率是由检索到的句子的相似性和与复制机制的生成概率共同预测的,本文的目标函数是最小化每个目标词的负对数可能性:
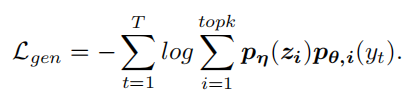
这两个组成部分可以单独进行训练。如果给定了一个现成的检索器,模型可以直接使用检索结果进行生成。在这种情况下,我们保持检索器的固定,只微调生成器。这为替换更好的检索器或适应不同的数据集提供了方便。
此外,检索器和生成器可以以迭代的方式进行端到端联合训练,以获得更好的性能。然而,在训练过程中直接更新检索器可能会大大降低其性能,因为生成器一开始就没有经过良好的训练。如果想获得一个稳定的训练,损失函数可以替换为:
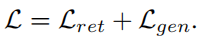
▊ 4.实验
4.1. Quantitative Analysis
4.1.1. 检索器的性能是否会影响结果?
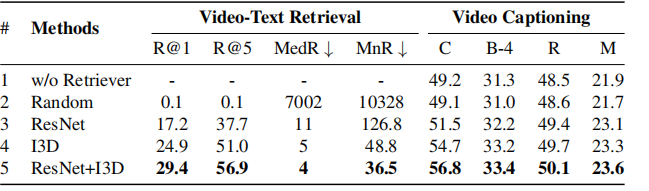
我们可以看到,性能更好的检索器可以显著提高生成效果。
4.1.2. 检索到的句子的数量是否会影响到结果?
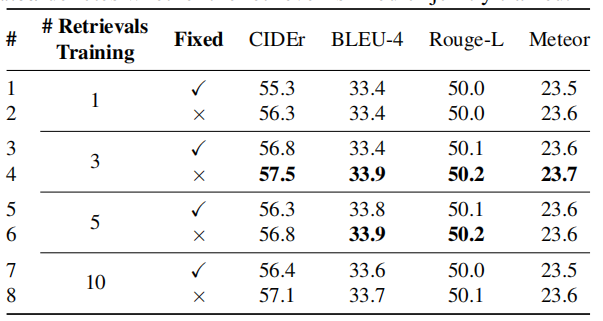
我们发现,中等数量的检索句子在训练期间有助于生成好的句子。
4.1.3. 检索语料库的质量是否会影响结果?
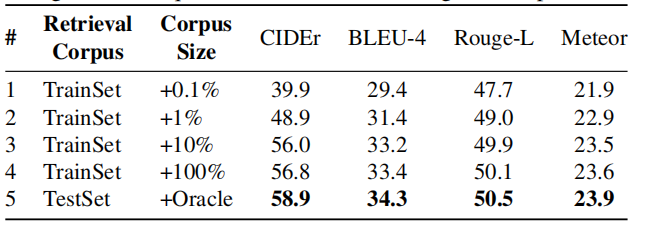
上表说明了大规模的检索语料库对于生成更好的描述是有益的。
4.1.4. 哪一种是更好的,固定的或联合训练的检索器?
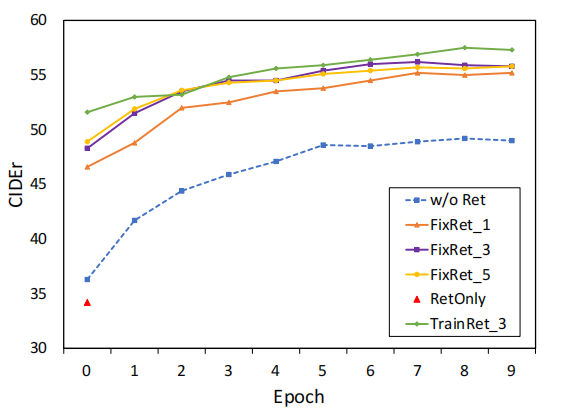
FixRet和TrainRet分别表示固定的检索器和联合训练的检索器。可以看出,联合训练的检索器在精度方面比固定的要好。
4.1.5. 跨数据集视频的模型如何泛化?
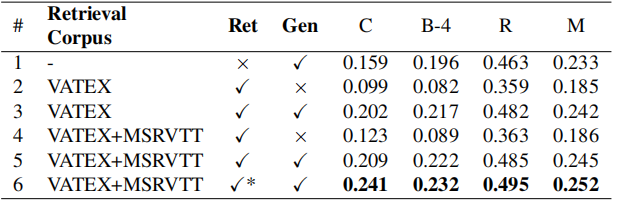
在实际应用中,输入的视频分布不一定与训练数据相同。RCG可以通过改变不同的检索器和检索语料库进行扩展。
4.2. Comparison to State-of-the-Arts
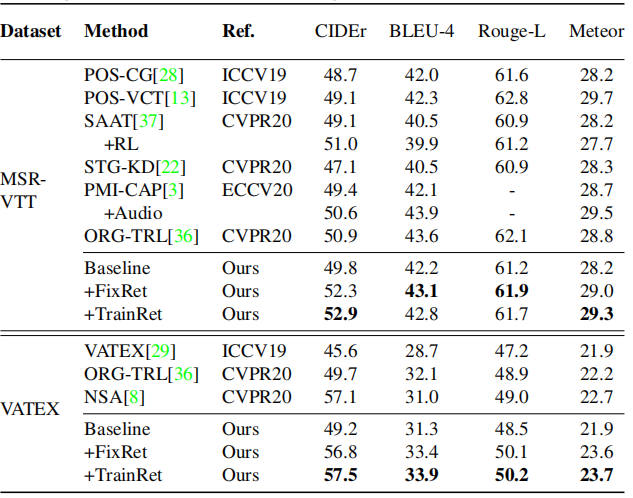
与Baseline相比,RCG取得了显著的性能提升,证明了该方法的有效性。
4.3. Qualitative Analysis

上图可视化了视频文本检索过程中检索到句子的注意权重。
▊ 5. 总结
在本文中,作者提出了用于开放式视频字幕的RCG模型。RCG通过跨模态检索器有效地从文本语料库中检索与视频内容相关的句子,联合从多个检索到的相关句子,并通过基于复制机制的标题生成器生成描述,能以单独或端到端的方式进行优化。
作者在两个大规模视频字幕数据集上进行了实验,优越的结果证明了该方法的有效性。本文的研究结果表明,复制不限于检索句子的知识,如视频字幕、视频文本和语音文本等,都能进行全面的信息获取以达到更好的生成效果。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV
END,入群????备注:Caption
