基于多头注意力机制的模型层融合维度情感识别
论文介绍
原著:
《基于多头注意力机制的模型层融合维度情感识别方法》
2021 Journal of Signal Processing
研究问题
多模态下情感识别,需要解决多种模态怎么进行融合。常用的有三种方式,特征层融合、决策层融合、模型层融合。
目前研究大部分采用的是前两种融合方式(决策方式用得更多),但这两种方式都存在较大弊端。
特征层:只是对各个模态的情感特征进行简单拼接,并没有考虑到模态之间的信息交互。
决策层:虽然解决了不同模态之间的时序不同步问题,但是没有考虑到不同模态的情感特征信息的关联。
第三种方式解决了不同模态时序不同步的问题,同时考虑了不同模态的情感特征信息之间的关联性。
【多头注意力机制】:具有多个头部,而且每个头部都可以产生不同的注意力分布,解决的是信息中的长时依赖性(位置A与B学习的时间间隔长、但只要他们之间有关系,两者可保持依赖)
【注意力机制】是为了更好的关注有效特征。
本文就是在多模态下,提出多种注意力机制来研究模型层融合下的情感识别。
研究方法
评价指标:CCC(一致性相关系数)
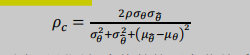

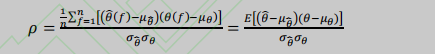
(PCC:皮尔逊相关系数)
数据集:AVEC2017 数据集(SEW A 数据集的子集)
【结果】:视频情感特征的性能强于音频情感特征的性能
技术介绍
BLSTM(双向长短时记忆网络)
输出
- 多模态下的各模态处理(用到了哪些特征模型及各特征模型的适用场景)
- IS2010 特征集作为短时音频特征、BoAW 特征集作为长时音频特征在长短时记忆网络中学习效果较好
- BoVW (词袋特征集),适合在长时的情感识别建模中使用,VGGFace(人脸超分辨率序列特征集)适于短时的情感识别模型中
- 不同注意力机制(长时序的多头)
- 评价指标(RMSE、PCC、CCC)
版权声明:本文为lfb637原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。