?大家好,我是CuddleSabe,目前大四在读,深圳准入职算法工程师,研究主要方向为多模态(VQA、ImageCaptioning等),欢迎各位佬来讨论!
?我最近在有序地计划整理CV入门实战系列及NLP入门实战系列。在这两个专栏中,我将会带领大家一步步进行经典网络算法的实现,欢迎各位读者(da lao)订阅?
Decoder
在上一节中,我们学习了Encoder的结果及实现代码:
Transformer中的Encoder详解:Multi-Head-Attention及Feed-Forward
在这一节中,我们将学习Transformer剩余的部分:Decoder
Decoder结构
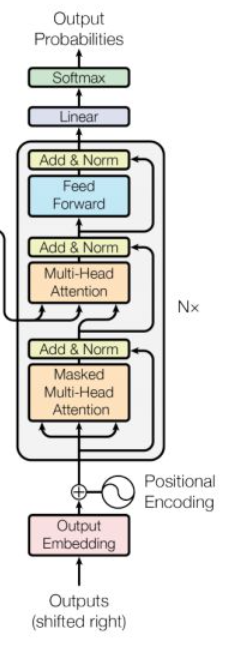
D e c o d e r DecoderDecoder的结构和E n c o d e r EncoderEncoder类似,但是相较于E n c o d e r EncoderEncoder,增加了一个S u b l a y e r SublayerSublayer。
值得注意的是,增加的这层S u b l a y e r SublayerSublayer并不是S e l f − A t t e n t i o n Self-AttentionSelf−Attention,因为这层l a y e r layerlayer的输入包含了E n c o d e r EncoderEncoder的输出和上一步D e c o d e r DecoderDecoder的输出。
Masked
可以观察到,D e c o d e r DecoderDecoder的A t t e n t i o n AttentionAttention叫做M a s k e d − M u l t i − H e a d − A t t e n t i o n Masked-Multi-Head-AttentionMasked−Multi−Head−Attention,其原因在于加了M a s k MaskMask掩码。原因在于:
防止D e c o d e r DecoderDecoder在训练时接触到未来信息,原因详见下一条。
训练与推断
因为D e c o d e r DecoderDecoder的输入是上一层的O u t p u t OutputOutput和E n c o d e r EncoderEncoder的编码,所以在训练时如果采用训练时的输出,则有可能会造成预测越来越偏差g r o u n d − T r u t h ground-Truthground−Truth的情况:因为偏差会慢慢累积。
所以,在训练时,D e c o d e r DecoderDecoder的输入是g r o u n d − T r u t h ground-Truthground−Truth和E n c o d e r EncoderEncoder的编码,这样所有的g r o u n d − T r u t h ground-Truthground−Truth可以同时送进D e c o d e r DecoderDecoder进行训练。
在推断时,D e c o d e r DecoderDecoder的输入是上一层D e c o d e r DecoderDecoder的输出和E n c o d e r EncoderEncoder的编码,需要一个个依次送入。
在训练时,注意要M a s k MaskMask掉未来的信息.
实现代码
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
a = MultiHeadedAttention(8, 1024)
x = self.sublayer[0](x, lambda x: a(x, mask=tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, mask=src_mask))
return self.sublayer[2](x, self.feed_forward)
# Decoder
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)