基本概念
- 内核
内核主要的职责有,进程调度,内存管理,提供文件系统,创建和终止进程,对外部设备的访问,联网和供系统调用API。内核态和用户态,执行硬件指令可以使CPU在两种状态间来回切换,虚拟内存也划分成,用户空间部分和内核空间部分。在用户态运行,CPU只能访问用户空间部分,访问内核空间会引发硬件异常。运行在内核态既能访问用户空间也能访问内核空间。某些特定的操作如关机,访问内存管理硬件等等。也只能在核心态才能运行。
- 用户和组
系统会对每个用户的唯一身份做标识,用户可以隶属于多个组。
- 当前工作目录
每个进程都有一个当前工作目录,也是进程解释相对路径的参照点。进程的当前工作目录继承自其父进程。getcwd()函数可以获取当前工作目录。chdir()系统调用可以改变进程的当前工作目录。
- 文件的所有权和权限
每个文件都有一个与之相关的用户ID和组ID,分别定义文件的属主和属组。为了访问文件,系统把用户分为3类,文件的属主,与文件组ID相匹配的属组成员用户和其他用户。可以为以上3种用户分别设置3种权限(共计9种权限位)读权限,写权限,执行权限。
文件I/O
- open()
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags, ... /*mode_t mode */);
//Returns file descriptor on success or -1 on error
open 既可以打开一个已存在文件也可以创建并打开一个文件。如果调用成功返回文件描述符,失败返回-1,并将errno置为相应错误标识。如果调用open成功,其返回为进程未使用文件描述符中数值最小者。flags参数表示打开文件所采用的操作,我们需要注意的是必须指定以下三个常量的一种,且只允许指定一个
| 访问模式 | 描述 |
|---|---|
| O_RDONLY | 以只读方式打开文件 |
| O_WRONLY | 以只写方式打开文件 |
| O_RDWR | 以读写方式打开文件 |
以下的常量是选用的,这些选项是用来和上面的必选项进行按位或起来作为flags参数
| 访问模式 | 描述 |
|---|---|
| O_APPEND | 表示追加,如果原来文件里面有内容,则这次写入会写在文件的最末尾 |
| O_CREAT | 表示如果指定文件不存在,则创建这个文件 |
| O_EXCL | 表示如果要创建的文件已存在,则出错,同时返回 -1,并且修改 errno 的值 |
| O_TRUNC | 表示截断,如果文件存在,并且以只写、读写方式打开,则将其长度截断为0 |
| O_NOCTTY | 如果路径名指向终端设备,不要把这个设备用作控制终端 |
| O_NONBLOCK | 如果路径名指向 FIFO/块文件/字符文件,则把文件的打开和后继 I/O设置为非阻塞模式(nonblocking mode) |
以下三个常量同样是选用的,它们用于同步输入输出
| 访问模式 | 描述 |
|---|---|
| O_DSYNC | 等待物理 I/O 结束后再 write。在不影响读取新写入的数据的前提下,不等待文件属性更新 |
| O_RSYNC | read 等待所有写入同一区域的写操作完成后再进行 |
| O_SYNC | 等待物理 I/O 结束后再 write,包括更新文件属性的 I/O |
当调用open()创建文件时,位掩码参数mode指定了文件的访问权限。三个参数是在第二个参数中有O_CREAT时才作用,如果没有,则第三个参数可以忽略。open函数与fopen函数区别,open函数是Unix下系统调用函数,操作成功返回的是文件描述符,操作失败返回的是-1,fopen是ANSIC标准中C语言库函数,所以在不同的系统中调用不同的内核的API,返回的是一个指向文件结构的指针。同时open函数没有缓冲,fopen函数有缓冲,open函数一般和write配合使用,fopen函数一般和fwrite配合使用。
- read()
#include <unistd.h>
ssize_t read(int fd, void* buffer, size_t count);
//Return number of bytes read, 0 on EOF, or -1 on error
count参数指定最多能读取的字节数,buffer参数提供用来存放输入数据的内存缓冲区地址。缓冲区至少应有count个字节。如果read()调用成功,将返回实际读取的字节数,如果遇到文件结尾(EOF)则返回0,如果出错返回-1。一次read所读取的字节数小于请求字节数。对于普通文件而言,有可能读取位置靠近文件末尾。当读其它文件类型,比如管道,FIFO, socket或终端,在不同的环境下也会出现read调用返回的字节数小于请求的字节数。例如默认情况下从终端读取字符,一遇到换行符(\n),read调用就会结束
- write()
#include <unistd.h>
ssize_t write(int fd, void* buffer, size_t count);
//Retuen number of bytes written,or -1 on error
write()调用参数和read()调用相似。
- close()
#include <unistd.h>
int close(int fd);
//Return 0 on success, or -1 on error
close()系统调用关闭一个打开的文件描述符。
- lseek()
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
//Return new file offset if successful,or -1 on error
offset参数指定了一个以字节为单位的数值,whence参数表明应该参照哪个基点来解释offset参数。应为下列其中之一。
| whence | 说明 |
|---|---|
| SEEK_SET | 将文件偏移量设置为从文件头部开始的offset个字节 |
| SEEK_CUR | 相对于当前文件偏移量,将文件偏移量调整offset个字节 |
| SEEK_END | 将文件偏移量设置为起始于文件尾部的offset个字节 |
如果whence参数设置为SEEK_CUR或SEEK_END,offset参数可以为正数也可以为负数,如果whence为SEEK_SET,offset必须为非负数。
- 文件空洞
如果文件的偏移量已然跨越了文件结尾,然后在执行I/O操作,将会发生什么情况?read()调用返回0,表示文件结尾,wirte()函数可以在文件结尾后的任意位置写入数据。从文件结尾后到新写入数据的这段空间被称为文件空洞。文件空洞不占用任何磁盘空间。直到在文件空洞中写入了数据,文件系统才会为之分配磁盘块。核心转储文件(core dump)是包含空洞文件的常见例子。
- fcntl()
#include <fcntl.h>
int fcntl(int fd, int cmd, ...);
//Return on success depends on cmd, or -1 on error;
fcntl()系统调用对一个打开的文件描述符执行一系列控制操作。
- 文件描述符和打开文件之间的关系
inode
每个文件系统会为其上的所有文件建立一个i-node表,inode包含文件的元信息,具体有文件的字节数,文件拥有者ID,组ID,文件的权限,文件的时间戳,链接数即多少个文件名指向这个inode,文件数据block的位置。stat命令可以查看某个文件inode信息。
$ stat 文件名
除了文件名以外的所有信息都存在inode之中。inode也会消耗磁盘空间,在硬盘格式化的时候操作系统将硬盘分成两个区域。一个是数据区,存放文件数据,另一个是inode区(inode table),存放inode所包含的信息。
$ df -i
df命令可以查看硬盘分区的inode的总数和已经使用的数量。由于每个文件都必须有一个inode,有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。使用ls -i命令,可以看到文件名对应的inode号码
$ ls -i 文件名
目录文件
在Linux系统中,目录也是一种文件,打开目录实际上就是打开目录文件。目录文件就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
硬链接
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Linux系统允许,多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
软链接
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的软链接或符号链接。文件A依赖于文件B而存在,如果删除了文件B打开文件A就会报错。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
系统级打开文件表(open file table)
内核对所有打开的文件维护一个系统级的描述表格,并将表中各条目称为打开文件句柄。一个打开文件句柄存储了与一个打开文件相关的全部信息,如下所示。
- 当前文件偏移量(调用read()和write()时更新,或使用lseek()直接修改。
- 打开文件时所用使用的状态标志
- 文件访问模式
- 对该文件inode对象引用
- 等等
进程级的文件描述符表
对于每个进程,内核为其维护打开文件的描述符表,该表的每一条目都记录了单个文件描述符的相关信息,如下所示。
- 控制文件描述符操作的一组标志。
- 对打开文件句柄的引用。
如果两个文件描述符,指向同一个打开文件句柄,将共享同一文件偏移量。
- 复制文件描述符
#include <unistd.h>
int dup(int oldfd);
//Return file descriptor on success, or -1 on error
dup()调用复制一个打开的文件描述符oldfd, 并返回一个新描述符,二者都指向同一打开的文件句柄。系统会保证新描述符一定是编号值最低的未使用文件描述符。
#include <unistd.h>
int dup2(int oldfd, int newfd);
//Return new file descriptor on success, or -1 on error
dup2()系统调用会为oldfd参数所指定的文件描述符创建副本,其编号由newfd参数指定。如果newfd参数所指定编号的文件描述符之前已经打开,那么dup2()会首先将其关闭。并会忽略newfd关闭期间出现的任何错误。
- 在文件特定偏移量处的I/O,pread()和pwrite()
系统调用pread()和pwrite(), 会在offset参数所指定的位置进行文件I/O操作,且它们不会改变文件的当前偏移量。
#include <unistd.h>
ssize_t pread(int fd, void* buf, size_t count, off_t offset);
//Return numbers of bytes read, 0 on EOF, or -1 on error
ssize_t pwrite(int fd, void* buf, size_t count, off_t offset);
//Return number of bytes written, or -1 on error
pread()调用等于将如下调用纳入同一原子操作:
off_t orig;
orig = lseek(fd, 0, SEEK_CUR);
lseek(fd, offset, SEEK_SET);
s = read(fd,buf, len);
lseek(fd, orig, SEEK_SET);
pwrite()类似
- 文件I/O的内核缓冲
read()和write()系统调用在操作磁盘文件时不会直接发起磁盘访问,而是仅仅在用户空间缓冲区与内核缓冲区高速缓存之间复杂数据。调用write()将数据从用户空间内存传递到内核空间的缓冲区,write随即返回,在后续的某个时刻,内核会将其缓冲区中的数据写入磁盘。同理,对于read(),内核从磁盘中读取数据并存储到内核缓冲区中,read调用将从该缓冲区读取数据,直至把缓冲区中的数据取完,这时,内核会将文件的下一段内容读入缓冲区。
- stdio库的缓冲
当操作磁盘文件时,缓冲大块数据以减少系统调用,C语言库函数的I/O函数(如,fprintf,fscanf,fgets,fputs,等)正是这么做的。因此,使用stdio库可以使编程者免于自行处理读数据的缓冲。
设置stdio流的缓冲模式
#include <stdio.h>
int setvbuf(FILE* stream, char* buf, int mode, size_t size);
setvbuf()函数,可以控制stdio库使用缓冲的形式。stream参数标识将要修改的文件流,打开流后,必须在调用任何其他stdio函数之前先调用setvbuf。参数buf和size指定stream要使用的缓冲区。参数mode指定了缓冲类型,有下列值之一。
_IONBF 不对I/O进行缓冲,每个stdio库函数将立即调用write()或者read(),并且忽略buf和size参数。
_IOLBF 采用行缓冲I/O。终端设备的流默认属于这一类型。对于输出流,在输出一个换行符(除非缓冲区已经填满)前将缓冲数据。对于输入流,每次读取一行数据。
_IOFBF 采用全缓冲I/O。单次读,写数据的大小与缓冲区相同。刷新stdio缓冲区
无论当前采用何种缓冲区模式,在任何时候,都可以使用fflush()库函数强制将stdio输出流中的数据刷新到内核缓冲区中。当关闭相应流时,将自动刷新其stdio缓冲区。
#include <stdio.h>
int fflush(FILE* stream);
- 控制文件I/O的内核缓冲
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
//Return 0 on success, or -1 on error
void sync(void);
fsync()系统调用将使缓冲数据和与打开文件描述符fd相关的所有元数据都刷新到磁盘上。仅在对磁盘设备的传递完成后,fsync()调用才会返回。fdatasync()可能会减少对磁盘操作的次数,由fsync调用请求的两次变为一次。fdatasync只是强制进行了数据更新(诸如最近修改时间戳之类的元数据发生了变化,是无需传递到磁盘的),而fsync调用会强制将元数据传递到磁盘上。
使所有写入同步:O_SYNC,在调用open()函数是如指定O_SYNC标志,则会使后续输出同步,每个write调用会自动将文件数据和元数据刷新到磁盘上。
采用O_SYNC标志(或者频繁调用fsync,fdatasync,sync) 对性能的影响极大。
- 绕过缓冲区:直接I/O
从用户空间直接将数据传递到文件或磁盘设备。有时也称为直接I/O。要执行直接I/O,需要在调用open()打开文件或设备时指定O_DIRECT标志。直接I/O的对齐限制。
- 混合使用库函数和系统调用进行文件I/O
#include <stdio.h>
int fileno(FILE* stream);
//Return file descriptor on success, or -1 on error
FILE* fdopen(int fd, const char* mode);
//Return file pointer on success, or NULL on error
给定一个文件流,fileno()函数将返回相应的文件描述符。fdopen()函数与fileno()功能相反,mode参数与fopen()函数中mode参数含义相同。fdopen()函数对非常规文件描述符特别有用,创建套接字和管道的系统调用总是返回文件描述符。为了在这些文件类型上使用stdio库函数,必须使用fdopen()函数来创建相应的文件流。
文件系统
监控文件事件
C++中文件操作
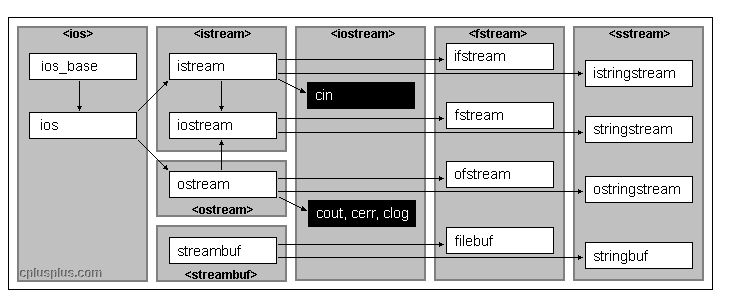
- fstream
ofstream 文件写操作,内存写入存储设备。ifstream 文件读操作,存储设备读到内存中。fstream 对打开的文件进行读写操作。
- 打开文件
文件流通过构造函数或者调用open()与文件进行关联
void open ( const char * filename,
ios_base::openmode mode = ios_base::in | ios_base::out );
参数filename 操作文件名,mode文件的打开方式。打开方式在ios类中定义,有如下几种方式:
| 方式 | 描述 |
|---|---|
| ios::in | 为输入(读)而打开文件 |
| ios::out | 为输出(写)而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 所有输出附加在文件末尾 |
| ios::trunc | 如果文件已存在则先删除该文件 |
| ios::binary | 二进制方式 |
这些方式是能够进行组合使用,以或运算(|)的方式。
- 关闭文件
当文件读写操作完成之后,我们必须将文件关闭以使文件重新变为可访问的。成员函数close(),它负责将缓存中的数据排放出来并关闭文件。这个函数一旦被调用,原先的流对象就可以被用来打开其它的文件了,这个文件也就可以重新被其它的进程所访问了。为防止流对象被销毁时还联系着打开的文件,析构函数将会自动调用关闭函数close。
- 文本文件的读写
// writing on a text file
#include <fstream.h>
int main () {
ofstream out("out.txt");
if (out.is_open())
{
out << "This is a line.\n";
out << "This is another line.\n";
out.close();
}
return 0;
}
//结果: 在out.txt中写入:
This is a line.
This is another line
// reading a text file
#include <iostream.h>
#include <fstream.h>
#include <stdlib.h>
int main () {
char buffer[256];
ifstream in("test.txt");
if (! in.is_open())
{ cout << "Error opening file"; exit (1); }
while (!in.eof() )
{
in.getline (buffer,100);
cout << buffer << endl;
}
return 0;
}
//结果 在屏幕上输出
This is a line.
This is another line
上面的例子读入一个文本文件的内容,然后将它打印到屏幕上。注意我们使用了一个新的成员函数叫做eof ,它是ifstream 从类 ios 中继承过来的,当到达文件末尾时返回true。
除了eof()以外,还有一些验证流的状态的成员函数(所有都返回bool型返回值):
bad():如果在读写过程中出错,返回 true 。例如:当我们要对一个不是打开为写状态的文件进行写入时,或者我们要写入的设备没有剩余空间的时候。
fail():除了与bad() 同样的情况下会返回 true 以外,加上格式错误时也返回true ,例如当想要读入一个整数,而获得了一个字母的时候。
eof():如果读文件到达文件末尾,返回true。
good():这是最通用的:如果调用以上任何一个函数返回true 的话,此函数返回 false 。
要想重置以上成员函数所检查的状态标志,你可以使用成员函数clear(),没有参数。
- 获取和设置流指针
所有输入/输出流对象(i/o streams objects)都有至少一个流指针:
ifstream, 类似istream, 有一个被称为get pointer的指针,指向下一个将被读取的元素。ofstream, 类似 ostream, 有一个指针 put pointer ,指向写入下一个元素的位置。fstream, 类似 iostream, 同时继承了get 和 put。我们可以通过使用以下成员函数来读出或配置这些指向流中读写位置的流指针:
tellg() 和 tellp() 这两个成员函数不用传入参数,返回pos_type 类型的值(根据ANSI-C++ 标准) ,就是一个整数,代表当前get 流指针的位置 (用tellg) 或 put 流指针的位置(用tellp).
seekg() 和seekp() 这对函数分别用来改变流指针get 和put的位置。两个函数都被重载为两种不同的原型:
seekg ( pos_type position );
seekp ( pos_type position );
使用这个原型,流指针被改变为指向从文件开始计算的一个绝对位置。要求传入的参数类型与函数 tellg 和tellp 的返回值类型相同。
seekg ( off_type offset, seekdir direction );
seekp ( off_type offset, seekdir direction );
使用这个原型可以指定由参数direction决定的一个具体的指针开始计算的一个位移(offset)。它可以是:
| 参数 | 描述 |
|---|---|
| ios::beg | 从流开始位置计算的位移 |
| ios::cur | 从流指针当前位置开始计算的位移 |
| ios::end | 从流末尾处开始计算的位移 |
流指针 get 和 put 的值对文本文件(text file)和二进制文件(binary file)的计算方法都是不同的,因为文本模式的文件中某些特殊字符可能被修改。由于这个原因,建议对以文本文件模式打开的文件总是使用seekg 和 seekp的第一种原型,而且不要对tellg 或 tellp 的返回值进行修改。对二进制文件,你可以任意使用这些函数,应该不会有任何意外的行为产生。
以下例子使用这些函数来获得一个二进制文件的大小:
// obtaining file size
#include <iostream.h>
#include <fstream.h>
const char * filename = "test.txt";
int main () {
long l,m;
ifstream in(filename, ios::in|ios::binary);
l = in.tellg();
in.seekg (0, ios::end);
m = in.tellg();
in.close();
cout << "size of " << filename;
cout << " is " << (m-l) << " bytes.\n";
return 0;
}
//结果:
size of example.txt is 40 bytes.
- 二进制文件
在二进制文件中,使用<< 和>>,以及函数(如getline)来操作符输入和输出数据,没有什么实际意义,虽然它们是符合语法的。
文件流包括两个为顺序读写数据特殊设计的成员函数:write 和 read。第一个函数 (write) 是ostream 的一个成员函数,都是被ofstream所继承。而read 是istream 的一个成员函数,被ifstream 所继承。类 fstream 的对象同时拥有这两个函数。它们的原型是:
write ( char * buffer, streamsize size );
read ( char * buffer, streamsize size );
这里 buffer 是一块内存的地址,用来存储或读出数据。参数size 是一个整数值,表示要从缓存(buffer)中读出或写入的字符数。
// reading binary file
#include <iostream>
#include <fstream.h>
const char * filename = "test.txt";
int main () {
char * buffer;
long size;
ifstream in (filename, ios::in|ios::binary|ios::ate);
size = in.tellg();
in.seekg (0, ios::beg);
buffer = new char [size];
in.read (buffer, size);
in.close();
cout << "the complete file is in a buffer";
delete[] buffer;
return 0;
}
//运行结果:
The complete file is in a buffer
- 缓存和同步(Buffers and Synchronization)
当我们对文件流进行操作的时候,它们与一个streambuf 类型的缓存(buffer)联系在一起。这个缓存(buffer)实际是一块内存空间,作为流(stream)和物理文件的媒介。例如,对于一个输出流, 每次成员函数put (写一个单个字符)被调用,这个字符不是直接被写入该输出流所对应的物理文件中的,而是首先被插入到该流的缓存(buffer)中。
当缓存被排放出来(flush)时,它里面的所有数据或者被写入物理媒质中(如果是一个输出流的话),或者简单的被抹掉(如果是一个输入流的话)。这个过程称为同步(synchronization),它会在以下任一情况下发生:
当文件被关闭时: 在文件被关闭之前,所有还没有被完全写出或读取的缓存都将被同步。
当缓存buffer 满时:缓存Buffers 有一定的空间限制。当缓存满时,它会被自动同步。
控制符明确指明:当遇到流中某些特定的控制符时,同步会发生。这些控制符包括:flush 和endl。
明确调用函数sync(): 调用成员函数sync() (无参数)可以引发立即同步。这个函数返回一个int 值,等于-1 表示流没有联系的缓存或操作失败。
进程
进程是由内核定义的抽象的实体,并为该实体分配用以执行程序的各项系统资源。从内核角度看,进程由用户内存空间和一系列内核数据结构组成,用户内存空间包含了程序的代码以及代码使用的变量,而内核数据结构则用于维护进程的状态信息。包括许多与进程相关的标识号(IDs)、虚拟内存表、打开文件的描述符表、信号传递以及处理的有关信息、进程资源使用以及限制、当前工作目录和大量的其他信息。
- 进程号和父进程号
#include <unistd.h>
pid_t getpid(void);
//Always successful return process ID of caller
pit_t getppid(void);
//Always successful return process ID of parent of caller
getpid和getppid返回进程ID和父进程ID,如果子进程的父进程终止,则子进程就会变成“孤儿”,init 进程随即将收养该进程,子进程对getppid的调用将返回进程号1。
- 栈和栈帧
用户栈,函数的调用和返回使栈的增长和收缩呈线性。X86_32体系架构之上的Linux,栈驻留在内存的高地址并向下增长。内核栈是每个进程保留在内核内存中的区域,在执行系统调用的过程中供内核内部函数调用使用。每个用户栈帧包括如下信息:
- 函数实参和局部变量
- 每个函数用到的一些CPU寄存器
- 执行非局部跳转:setjmp() 和 longjmp()
使用库函数setjmp() 和 longjmp() 可以执行非局部跳转。像C语言的goto,但goto语句存在一个限制,即不能从当前函数跳转到另一函数。
#include <setjmp.h>
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);
setjmp()调用为后续由longjmp()调用执行的跳转确立了跳转目标。从编程角度来看,调用longjmp()函数后,看起来就和从第二次调用setjmp()返回时完全一样。通过查看setjmp()返回值,可以区分setjmp调用是初始返回还是第二次“返回”,初始调用返回0,后续“伪“返回的值为longjmp()调用中val参数。
- /proc文件系统
为了更简便的来访问内核信息,许多现代的UNIX实现提供一个/proc虚拟文件系统。该文件系统驻留于/proc目录中,包含了各种用于展示内核信息的文件,并且允许进程通过常规文件I/O来方便读取。之所以将/proc文件系统称为虚拟,是因为其包含的文件和子目录并未存储与磁盘上,而是由内核在进程访问此类信息时动态创建而成。
对于系统中每个进程,内核都提供了相应的目录,/proc/PID。任何进程都可以使用符号链接/proc/self来访问自己的/proc/PID目录。
| /proc/PID/文件 | 描述 |
|---|---|
| cmdline | 以\0分隔的命令行参数 |
| cwd | 指向当前工作目录的符合链接 |
| Environ | name = value 键值对环境列表,以\0分隔 |
| exe | 指向正在执行文件的符合链接 |
| fd | 文件目录,包含指向由进程打开文件的符合链接 |
| maps | 内存映射 |
| mem | 进程虚拟内存(在I/O操作之前必须调用lseek()移至有效偏移量 |
| mounts | 进程的安装点 |
| root | 指向根目录的符合链接 |
| status | 各种信息(比如,进程ID,凭证,内存使用量,信号) |
| task | 为进程中的每个线程均包含一个子目录 |
/proc 目录下的系统信息
| 目录 | 目录中文件表达的信息 |
|---|---|
| /proc | 各种系统信息 |
| /proc/net | 有关网络和套接字的状态信息 |
| /proc/sys/fs | 文件系统相关设置 |
| /proc/sys/kernel | 各种常规的内核设置 |
| /proc/sys/net | 网络和套接字的设置 |
| /proc/sys/vm | 内存管理设置 |
| /proc/sysvipc | 有关System V IPC 对象的信息 |
进程的创建
- 创建新进程:fork()
#include <unistd.h>
pid_t fork(void);
理解fork()的诀窍是,完成成对其调用后将存在两个进程,且每个进程都会从fork()的返回初继续执行。程序代码则可通过fork()的返回值来区分父,子进程。在父进程中,fork()将返回新创建子进程的进程ID,而fork()在子进程中则返回0,如有必要,子进程可以调用getpid()以获取自身的进程ID,调用getppid()以获取父进程ID。当无法创建子进程时,fork()将返回-1。在调用fork()之后,内核先调度哪个进程是无法确定的。
- 父,子进程间的文件共享
执行fork()时,子进程会获的父进程所有文件描述符的副本。这些副本的创建方式类似于dup(),这也意味着父,子进程中对应的描述符均指向相同的打开文件句柄。
- fork()的内存语义
内核将每一个进程的代码段标记为只读,从而使进程无法修改自身的代码。这样父,子进程可以共享同一代码段。系统调用fork()在为子进程创建代码段时,其所构建的一系列进程级页表项均指向与父进程相同的物理内存页帧。对于父进程数据段,堆段和栈段中的各页,内核采用写时复制技术来处理。
进程的终止
- 进程的终止:_exit()和exit()
通常进程的终止方式。其一为异常终止,此外,进程可以使用_exit()系统调用正常终止。
#include <unistd.h>
void _exit(int status);
_exit()的status参数定义了进程的终止状态,父进程可以调用wait()以获取该状态。虽然将其定义为int类型,但仅有低8位为进程所用。按照惯例,终止状态为0表示进程“功成身退”,而非0值表示进程因异常而退出。
程序一般不会直接调用_exit(),而是调用库函数exit(),它会在调用 _exit()前执行各种动作。
exit()会执行的动作如下
- 调用退出处理函数(通过atexit()和on_exit()注册的函数),其执行的顺序与注册顺序相反。
- 刷新stdio流缓冲区
- 执行_exit()系统调用
- 进程终止的细节
w无论进程是否正常终止,都会发生如下动作。
- 关闭所有打开文件描述符,
- 退出处理程序
#include <stdlib.h>
int atexit(void (*func)(void));
注册退出处理程序,可以注册多个退出处理程序(甚至可以将同一函数注册多次)当程序调用exit()时,这些函数的执行顺序与注册顺序相反。
监控子进程
- 系统调用wait()
系统调用wait()等待调用进程的任一子进程终止,参数status所指向的缓冲区中返回该子进程的终止状态。
#include <sys/wait.h>
pid_t wait(int* status);
如果调用进程没有子进程终止,调用将一直阻塞,直至某个子进程终止。
如果status非空,那么关于子进程如何终止的信息则会通过status指向的整型变量返回。
将终止进程的ID作为wait()的结果返回。
- 系统调用waitpid()
系统调用wait()存在诸多限制,而设计waitpid()则意在突破这些限制。
- 如果父进程已经创建了多个子进程,使用wait()将无法等待某个特定子进程的完成,只能顺序等待下一个子进程的终止。
- 如果没有子进程退出,wait()总是保持阻塞。有时会希望执行非阻塞的等待。
- 使用wait()只能发现那些已经终止的子进程,对于子进程因某个信号(如SIGSTOP或SIGTTIN)而停止,或是已经停止子进程收到SIGCONT信号后恢复执行的情况就无能为力了。
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int* status, int options);
waitpid()status参数与wait()意义相同。
如果pid > 0 表示等待进程ID为pid的子进程。
如果pid == 0 表示等待与调用进程同一个进程组的所有子进程。
如果pid < -1 表示等待进程组标识符与pid绝对值相等的所有子进程。
如果pid == -1 表示等待任意子进程
参数options是一个位掩码
WUNTRACED:除了返回终止子进程的信息外,还返回因信号停止的子进程信息。
WCONTINUED:返回那些因收到SIGCONT信号而恢复执行的已经停止子进程的状态信息。
WNOHANG:如果参数pid所指定的子进程并未发生状态改变,则立即返回,而不会阻塞。
内存分配
- 在堆上分配内存
进程可以通过增加堆的大小来分配内存,所谓堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾。通常将堆的当前内存边界称为“program break"。
调整program break:brk()和sbrk()
改变堆的大小,其实就像命令内核改变进程的program break 位置一样。在program break 的位置抬升后,程序可以访问新分配区域内的任何内存地址,而此时物理内存页尚未分配。内核会在进程首次试图访问这些虚拟内存地址时自动分配新的物理内存页。
#include <unistd.h>
int brk(void* end_data_segment);
void* sbrk(intptr_t increment);
系统调用brk()会将program break设置为参数end_data_segment所指定的位置。由于虚拟内存以页为单位进行分配,实际会四舍五入到下一个内存页边界。调用sbrk()将program break在原有地址上增加increment大小。若调用成功,sbrk()返回前一个program break的地址,如果program break增加,那么返回值是指向这块新分配内存起始位置的指针。
在堆上分配内存:malloc()和free()
#include <stdlib.h>
void* malloc(size_t size);
malloc()函数在堆上分配size个字节大小的内存(实际上会额外分配几个字节来存放这块内存的大小,位于内存块的起始处,给free()使用),并返回指向新分配内存起始位置处的指针,其所分配的内存未经初始化。
#include <stdlib.h>
void free(void* ptr);
free()函数释放ptr参数所指向的内存块。一般情况下,free()并不降低program break的位置,而是将这块内存添加到空闲内存列表中,供后续的malloc()函数循环使用。
在堆栈上分配内存:alloca()
和malloc函数功能一样,alloca()也可以动态分配内存,不过是通过增加栈帧的大小从栈上分配。
#include <alloca.h>
void* alloca(size_t size);
信号
信号是事件发生时对进程的通知机制。有时也称为软件中断,信号因某些事件而产生。信号产生后,会稍后被传递给某一进程,而进程也会采取某些措施来响应信号。在产生和到达期间,信号处于等待(pending)状态。
通常,一旦内核接下来要调度该进程运行,等待信号会马上送达,或者如果进程在运行,则会立即传递信号(如进程向自己发送信号)。然而,有时候需要确保一段代码不为传递来的信号所中断。为了做的这一点,可以将信号添加到进程的信号掩码中,会阻塞该组信号的到达。如果所产生的信号属于阻塞之列,那么信号将保持等待状态,直至稍后对其解除阻塞。
信号到达后,进程视具体信号执行如下默认操作
- 忽略信号: 内核将信号丢弃,信号对进程没有产生任何影响。
- 终止进程
- 产生核心转储文件,同时进程终止:核心转储文件包含进程虚拟内存的镜像,可将其加载到调速器中以检查进程终止时的状态。
- 停止进程:暂停进程的执行。
- 于之前暂停后再度恢复进程的执行。
除了根据特定信号而采取默认行为外,程序也能改变信号到达时的响应行为。也称为对信号的处置设置。程序可以将对信号的处置设置为如下之一。- 采取默认行为:这适用于撤销对之前对信号设置的修改,恢复其默认处置的场景。
- 忽略信号:这适用默认行为为终止进程的信号。
- 执行信号处理程序
- 信号类型和默认行为
SIGABRT:当进程调用abort()函数时,系统向进程发送该信号。默认情况下,该信号会终止进程,并产生核心转储文件。
SIGALRM:经调用alarm()或setitimer()而设置的实时定时器一旦到期,内核将产生该信号。
SIGBUS:产生该信号,即表示发送了某种内存错误,当使用由mmap()所创建的内存映射时,如果试图访问的地址超出了底层内存映射文件的结尾,那么将产生该错误。
SIGCHLD:当父进程的某一子进程终止时,内核将向父进程发送该信号。
SIGCLD:与SIGCHLD信号同义。
SIGCONT:该信号发送给已停止的进程,进程将会恢复运行(即在之后的某个时间点重新获得调度)。
SIGFPE:该信号因特定类型的算术错误而产生,比如除以0。
SIGINT:当用户键入终端中断字符(通常为Control-C),该信号的默认行为是终止进程。
SIGIO:利用fcntl()系统调用,可于特定类型(入终端和套接字)的打开文件描述符发送I/O事件时产生该信号。
SIGKILL:此信号,程序无法将其阻塞,忽略或者捕获,故而总能终止进程。
SIGSEGV:这一信号非常常见,当应用程序对内存的引用无效时,就会产生该信号。
SIGSTOP:这是一个必停信号,程序无法将其阻塞,忽略或者捕获,故而总能停止进程。
SIGSYS:如果进程发起的系统调用有误,那么将产生该信号。
SIGTERM:这是用来终止进程的标准信号,也是kill和killall命令所发生的默认信号。
SIGTRAP:该信号用来实现断点调试功能以及strace命令所执行的跟踪系统调用功能。
SIGURG:系统发送该信号给进程,表示套接字上存在紧急数据。
SIGPIPE:管道断开,默认终止进程。
等等
- 改变信号的处理:signal()
UNIX系统提供了两种方法改变信号处理:signal()和sigaction()
#include <signal.h>
void (*signal(int sig, void (*handler)(int))) (int);
//Return previous signal disposition on success, or SIG_ERR on error
//类似如下定义
typedef void (*sighandler_t)(int);
sighandler_t signal(int sig, sighandler_t handler);
第一个参数sig,标识希望修改处置的信号编号,第二个参数handler,则标识信号抵达时所调用的函数地址。signal()的返回值是之前的信号处理函数,像handler参数一样,是一个指针,指向的是带有一个整型参数且无返回值得参数。在为signal()指定handler参数时,可以用如下值来代替函数地址。
SIG_DFL:将信号处置重置为默认值。
SIG_IGN:忽略该信号
- 发送信号:kill()
#include <signal.h>
int kill(pid_t pid, int sig);
pid 参数标识一个或多个目标进程,而sig则指定要发送的信号。
- 发送信号的其他方式:raise()和killpg()
#include <signal.h>
int raise(int sig);
在单进程程序中,调用raise(),相当于对kill()的调用:
kill(getpid(), sig);
支持线程的系统会将raise()实现为:
pthread_kill(pthread_self(), sig)
pthread_kill()意味着将信号传递给调用raise()的特定线程。而kill()调用会发送一个信号给调用进程,并可将该信号传递给该进程的任一线程。
- 信号集
许多信号相关的系统调用都需要能表示一组不同的信号。多个信号可以使用一个称之为信号集的数据结构来表示,其系统数据类型为sigset_t。
#include <signal.h>
int sigemptyset(sigset_t* set);
int sigfillset(sigset_t* set);
//both return 0 on success, or -1 on error
sigemptyset()函数初始化一个未包含任何成员的信号集。sigfillset()函数则初始化一个信号集,使其包含所有信号。必须使用sigemptyset()或者sigfillset()来初始化信号集。
#include <signal.h>
int sigaddset(sigset_t* set, int sig);
int sigdelset(sigset_t* set, int sig);
sigaddset()和sigdelset()向一个集合中添加或者移除单个信号。
#include <signal.h>
int sigismember(const sigset_t* set, int sig);
如果sig是set的一个成员,那么sigismember()函数将返回1(true),否则返回0(false)。
- 信号掩码(阻止信号传递)
内核会为每个进程维护一个信号掩码,即一组信号,并将阻塞其针对该进程的传递。如果将遭阻塞的信号发送给某个进程,那么对该信号的传递将延后,直至从进程信号掩码中移除该信号,从而解除阻塞为止。信号掩码实际属于线程属性,在多线程进程中,每个线程都可以使用pthread_sigmask()函数来独立检查和修改其信号掩码。
向信号掩码中添加一个信号,有如下几种方式。
但调用信号处理函数时,可将引发调用的信号自动添加到信号掩码中,是否发生这一情况,要视sigaction()所使用的标准而定。
使用sigaction()函数设置信号处理函数时,可以指定一组额外信号,当调用该处理函数时将其阻塞。
使用sigprocmask()系统调用,随时可以显式的向信号掩码中添加或者移除信号。
#include <signal.h>
int sigprocmask(int how, const sigset_t* set, sigset_t* oldset);
how 参数指定了sigprocmask()函数想给信号掩码带来的变化。
SIG_BLOCK,将set指向信号集内的信号添加到掩码中。
SIG_UNBLOCK,将set指向信号集中的信号从信号掩码中移除。
SIG_SETMASK,将set指向的信号集赋给信号掩码。
- 处于等待状态的信号
如果进程收到一个该进程正在阻塞的信号,那么该信号会添加到进程的等待信号集中,当解除对该信号的锁定时,会随之将该信号传递给此进程,可以使用sigpending()确定进程中处于等待状态的是哪些信号。
#include <signal.h>
int sigpending(sigset_t* set);
sigpending()系统调用返回处于等待状态的信号集。
- 不对信号处理进行排队处理
等待信号集只是一个掩码,仅表明一个信号是否发生,而未表明其发生的次数。如果同一信号在阻塞状态下产生多次,那么会将该信号记录在等待信号集中,并在稍后仅传递一次。
- 改变信号处理函数:sigaction()
虽然sigaction()的用法比之前signal()更为复杂,当也更具灵活性和可移植性。
#include <signal.h>
int sigaction(int sig, const struct sigaction* act, struc sigaction* oldact);
//return 0 on success, or -1 on error
sig 参数标识想要获取或改变的信号编号。该参数可以是除去SIGKILL和SIGSTOP之外的任何信号。
act 参数是一枚指针,指向描述信号新处理的数据结构,如果仅对信号现有的处置感兴趣,可将该参数设为NULL。oldact参数用来返回之前信号处置的相关信息,如无意获取此类信息,可设为NULL。act和oldact所指向的结构类型如下所示:
strcut sigaction {
void (*sa_handler)(int);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
信号处理器函数
- 可重入函数和异步信号安全函数
如果同一个进程的多条线程可以同时安全的调用某一函数,那么该函数就是可重入的。此处的“安全”意味着,无论其他线程调用该函数的执行状态如何,函数均可产生预期结果。更新全局变量或静态数据结构的函数可能是不可重入的,只用到本地变量的函数肯定是可重入的。
cmake使用
- 什么是CMake
CMake它允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程,然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件,如 Unix 的 Makefile 或 Windows 的 Visual Studio 工程。从而做到“Write once, run everywhere”。
在 linux 平台下使用 CMake 生成 Makefile 并编译的流程如下:
- 编写 CMake 配置文件 CMakeLists.txt 。
- 执行命令 cmake PATH 或者 ccmake PATH 生成 Makefile。其中, PATH CMakeLists.txt 所在的目录。
- 使用 make 命令进行编译。
- 单个源文件
例如,假设现在我们的项目中只有一个源文件 main.cc。编写CMakeLists.txt,并保存在与 main.cc 源文件同个目录下:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo1)
# 指定生成目标
add_executable(Demo main.cc)
CMakeLists.txt 的语法比较简单,由命令、注释和空格组成,其中命令是不区分大小写的。符号 # 后面的内容被认为是注释。命令由命令名称、小括号和参数组成,参数之间使用空格进行间隔。对于上面的 CMakeLists.txt 文件,依次出现了几个命令:
- cmake_minimum_required:指定运行此配置文件所需的 CMake 的最低版本;
- project:参数值是 Demo1,该命令表示项目的名称是 Demo1 。
- add_executable: 将名为 main.cc 的源文件编译成一个名称为 Demo 的可执行文件。
编译项目,之后,在当前目录执行 cmake . ,得到 Makefile 后再使用 make 命令编译得到 Demo1 可执行文件。
- 多个源文件
上面的例子只有单个源文件。现在假如把 power 函数单独写进一个名为 MathFunctions.c 的源文件里,使得这个工程变成如下的形式:
./Demo2
|
+--- main.cc
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
这个时候,CMakeLists.txt 可以改成如下的形式:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 指定生成目标
add_executable(Demo main.cc MathFunctions.cc)
唯一的改动只是在 add_executable 命令中增加了一个 MathFunctions.cc 源文件。这样写当然没什么问题,但是如果源文件很多,把所有源文件的名字都加进去将是一件烦人的工作。更省事的方法是使用 aux_source_directory 命令,该命令会查找指定目录下的所有源文件,然后将结果存进指定变量名。其语法如下:
aux_source_directory(<dir> <variable>)
因此,可以修改 CMakeLists.txt 如下:
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 查找当前目录下的所有源文件
# 并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 指定生成目标
add_executable(Demo ${DIR_SRCS})
这样,CMake 会将当前目录所有源文件的文件名赋值给变量 DIR_SRCS ,再指示变量 DIR_SRCS 中的源文件需要编译成一个名称为 Demo 的可执行文件。
- 多个目录,多个源文件
现在进一步将 MathFunctions.h 和 MathFunctions.cc 文件移动到 math 目录下。
./Demo3
|
+--- main.cc
|
+--- math/
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
对于这种情况,需要分别在项目根目录 Demo3 和 math 目录里各编写一个 CMakeLists.txt 文件。为了方便,我们可以先将 math 目录里的文件编译成静态库再由 main 函数调用。根目录中的 CMakeLists.txt :
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo3)
# 查找当前目录下的所有源文件
# 并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 添加 math 子目录
add_subdirectory(math)
# 指定生成目标
add_executable(Demo main.cc)
# 添加链接库
target_link_libraries(Demo MathFunctions)
参考资料
- Linux UNIX系统编程手册 套装上下册 [The Linux Programming Interface] [德] Michael Kerrisk 著,孙剑,许从年,董健 等 译
- http://www.hahack.com/codes/cmake/
- https://blog.csdn.net/kingstar158/article/details/6859379
- http://www.ruanyifeng.com/blog/2011/12/inode.html