文章目录
dataframe常用操作
DataFrame的索引选项:
| 类型 | 说明 |
|---|---|
| obj[val] | 选取DataFrame的单个列或一组列。在一些特殊情况下会比较便利:布尔型数组(过滤行)、切片(行切片)、布尔型DataFrame (根据条件设置值)。 |
| obj.ix[val] | 选取DataFrame的单个行或一组行。 |
| obj.ix[:, val] | 选取单个列或列子集。 |
| obj.ix[val1, val2] | 同时选取行和列。 |
| reindex 方法 | 将一个或多个轴匹配到新索引。 |
| xs方法 | 根据标签选取单行或单列,并返回一个Series。 |
| icol、irow方法] | 根据整数位置选取单列或单行,并返回一个Series。 |
| get.value, set_value方法 | 根据行标签和列标签选取单个值。 |
1.创建DataFrame
直接传入一个由等长列表组成的字典创建一个DataFrame
自动会加上索引(与series相同),且所有列会被有序排列
如果指定列序列,则dataframe的列会按照指定顺序进行排列

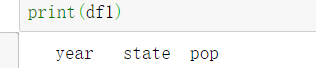
2.访问dataframe行
访问index为2的行
3.修改列的值
通过赋值直接修改,也可以指定五个值分别修改对应位置的值
4.新增列
为不存在的列赋值会创建出一个新列

5.del
关键字del用于删除列,用法 del dataframe.列名

6.嵌套字典初始化dataframe
外层字典的键作为列名,内层键则作为行索引,

7.dataframe的转置
dataframe.T 求出dataframe的转置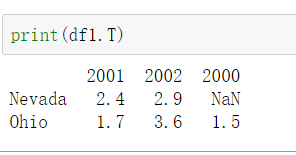
8.dataframe的数据类型
如果DataFrame各列的数据类型不同,则值数组的数据类型就会选用能兼容所有列的数据类型
9.reindex()
创建一个适应新索引的新对象,即建立一个新索引。
reindex函数的参数
| 参数 | 作用 |
|---|---|
| index | 用作索引的新序列。既可以是index实例,也可以是其他序列型的Python数据结构。Index会被完全使用,就像没有任何复制一样。 |
| method | 插值(填充)方式。 |
| fill_valuefill_value | 在重新索引的过程中,需要引入缺失值时使用的替代值 。 |
| limit | 前向或后向填充时的最大填充量. |
| level | 在Multiindex的指定级别上匹配简单索引,否则选取其子集 |
| copy | 默认为True,无论如何都复制;如果为False,则新旧相等就不复制 |
建立dataframe df1
如果某个索引值当前不存在,就引入缺失值NaN
指定缺失时,用0填充
method=’ffill‘可以实现前向值填充
method
| 参数 | 作用 |
|---|---|
| ffill或pad | 前向填充(或搬运)值 |
| bfill或backfill | 后向填充(或搬运)值 |
对于DataFrame,reindex可以修改行索引、列索引,或两个都修改。如果仅传入一个序列,则会重新索引行
创建dataframe df2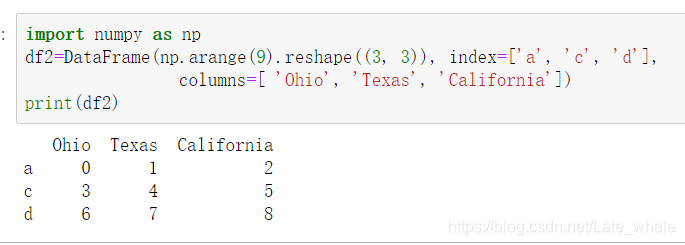
重新索引列
同时对行和列进行重新索引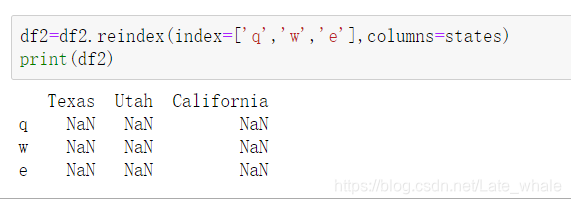
10.drop()
drop方法返回的是一个在指定轴上删除了指定值的新对象
删行
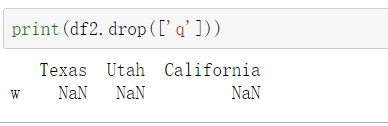
删列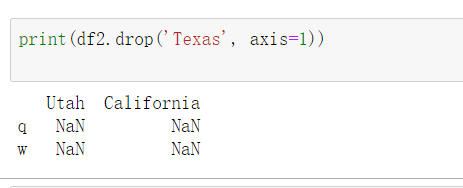
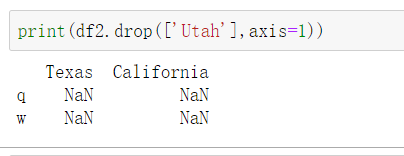
11.dataframe.values
以二维ndarray的形式返回dataframe的数据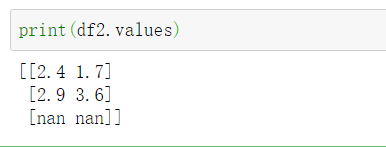
12.dataframe.index.name和dataframe.columns.name
dataframe的index和columns均有name属性
指定其name,并输出查看结果
dataframe常用方法
准备工作
创建一个DataFrame以便演示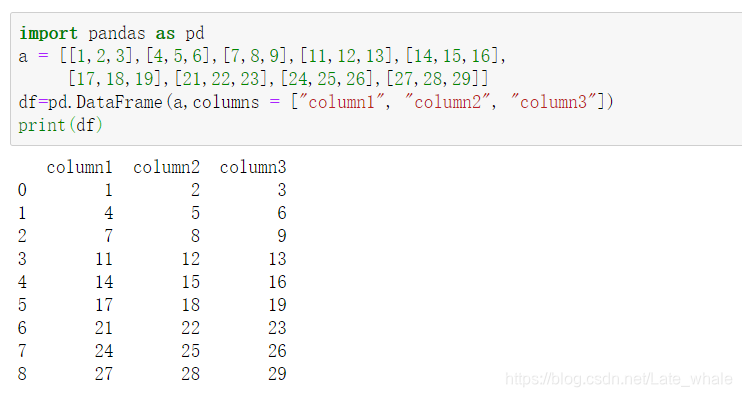
head()
默认查看dataframe的前5行,可以查看前n行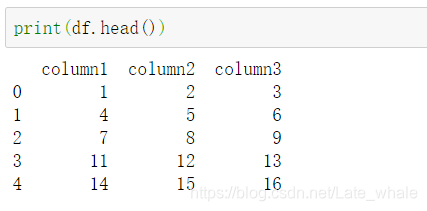
n为6时
tail()
与head()相反,查看dataframe的后五行或后n行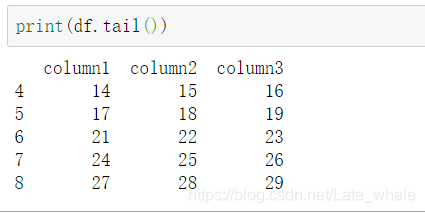
n=6时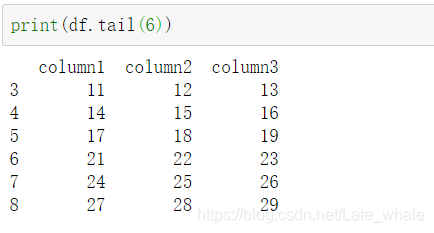
info()
用于查看dataframe中一些属性的描述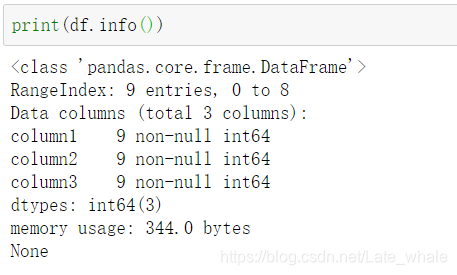
describe()
用于查看dataframe的一些基本统计数据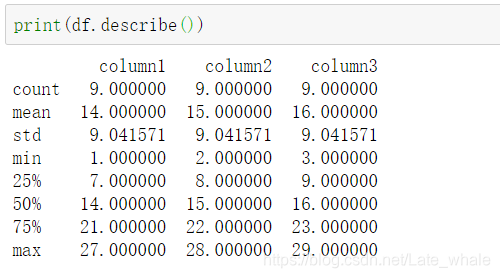
value_counts()
用于查看dataframe某列中数据分类以及每类的数量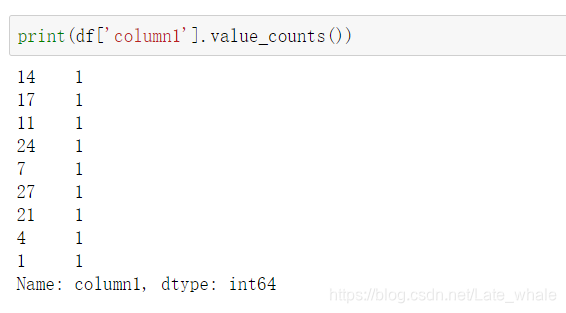
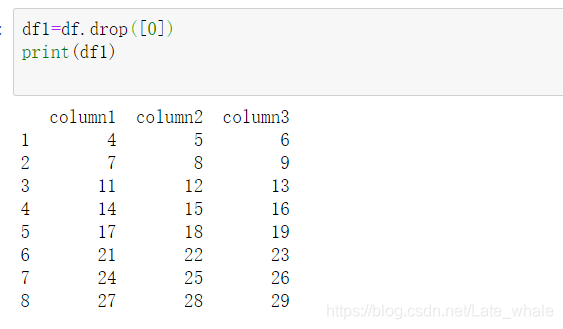
drop()
用于删除dataframe某一列或某几列,或者某一行或某几行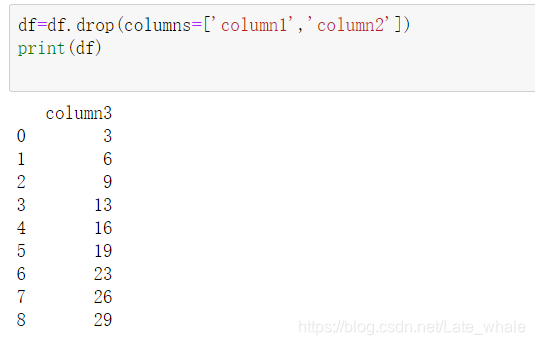
rename()
用于重命名dataframe中某一列或某几列,后面参数默认为false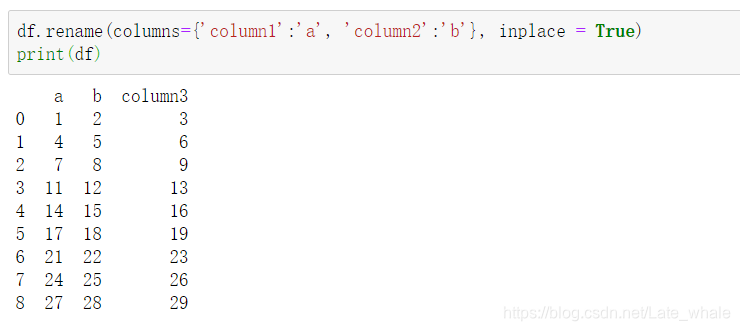
copy
用于拷贝一个dataframe
reset_index()
用于dataframe生成新的索引 。
df1为df删掉前两行,df2为df1索引重排之后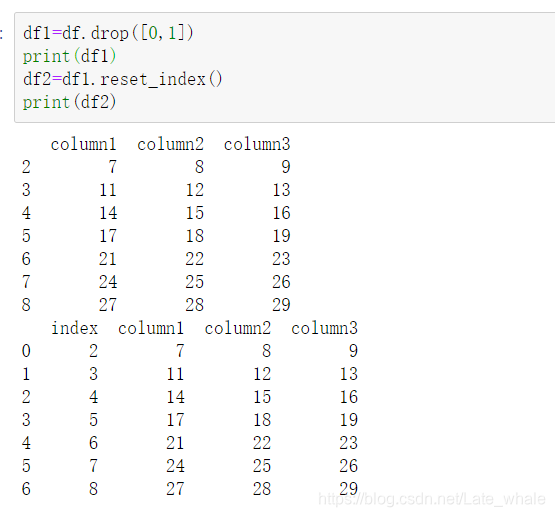
最后
可以关注一下我的公众号,最近开始写公众号,我会在上面分享一些资源和发布一些csdn上发布不了的干货
点个关注是对博主最大的支持