一、什么是Xpath?
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
XML 的标签需要我们自行定义。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准
W3School 官方文档:http://www.w3school.com.cn/xml/index.asp
XML 和 HTML 的区别:

二、xpath中的节点关系

1、xpath中的节点关系
父节点
每个元素以及属性都有一个父。
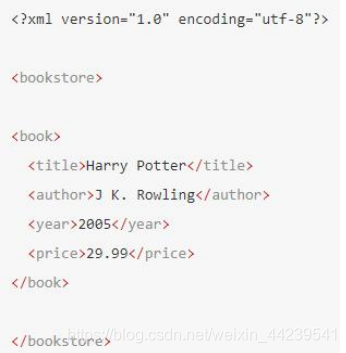
下面是一个简单 XML 例子中,book 元素是 title、author、year 以及 p
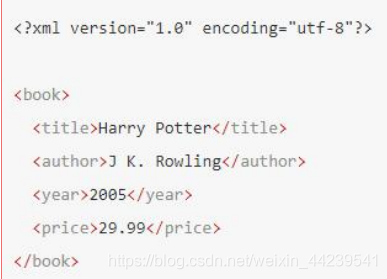
子节点
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
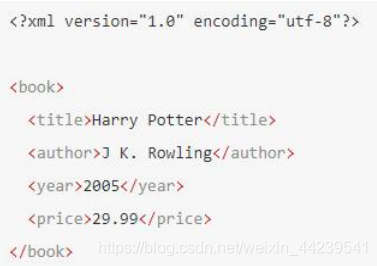
同胞节点
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
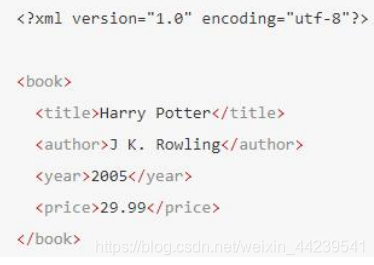
先辈节点
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素
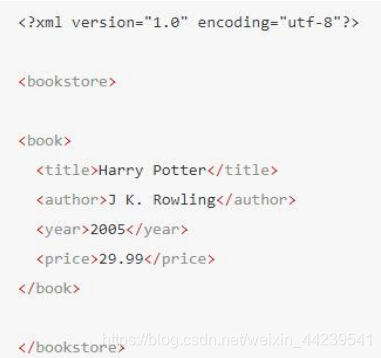
后辈节点
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
三、xpath的用法
1、选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我
们在常规的电脑文件系统中看到的表达式非常相似。
了最常用的路径表达式:

id 获取id 的属性值
starts-with 顾名思义,匹配一个属性开始位置的关键字 -- 模糊定位
contains 匹配一个属性值中包含的字符串 -- 模糊定位
text() 函数文本定位
last() 函数位置定位
2、语法
在python中用xpath时,需要用到lxml模块,这是python的第三方模块,可以通过命令 pip insall lxml下载该模块
或者也可以在pycharm中的setting的project Interpreter 里面进行下载
# 引入模块
from lxml import etree
# 使用etree.HTML(text),将文字信息转化成一个树形结构
tree = etree.HTML(text) #将文档生成一棵树
# 之后就可以通过生成的文档树 tree 来查找节点2、具体案例
(1) 爬取腾讯招聘
爬取腾讯招聘网页中所有python的北京职位,要求爬出对应的职位名称,职位类别,职位人数,职位地址及职位招聘时间
需要注意的是,在发起网络请求时,需要在请求头部,也就是request header 中加入 User-Agent 及对应的浏览器表示,腾讯招聘通过此项数据来进行反爬虫,由于我们使用的是程序,不具备此项,所以需要加入此项来伪装成一个浏览器。
还需要注意的是,原网页中一些节点在我们进行爬取之后在本地生成的文件中,可能不会显示,所以进行选取节点时,要根据生成的本地文件的节点来进行节点选取。
还需要注意的是:爬取一个表格中所有数据时,最好选取到这几项数据所在的父节点,进行循环遍历提取,如果在数据的上面几层几点进行遍历提取,可能会由于数据缺失,造成遍历时,索引错误
具体代码:
# 分析接口
# 第一页: 'https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start=0#a'
# 第二页: 'https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start=10#a'
# 第三页: 'https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start=20#a'
# 第n页:start = (n-1)*10
import requests
from lxml import etree
# 定义一个函数,用来判断空
def getDataFormList(temp_list):
if len(temp_list) > 0:
return temp_list[0]
else:
return ''
page = 1
# for page in range(1, 59, 1)
while True:
# 生成url
url = 'https://hr.tencent.com/position.php?lid=&tid=&keywords=python&start=' + str((page - 1) * 10)
print('第%s页网址'%(page),url)
# 由于服务器可能使用了反爬虫策略,所以我们应该将自己伪装成一个浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 网络访问
response = requests.get(url, headers=headers)
# with open('python.html', 'w', encoding='utf-8') as fp:
# fp.write(response.text)
# 数据提取
tree = etree.HTML(response.text)
tr_list = tree.xpath('//table[@class="tablelist"]/tr')
# 由于存在表头和表尾,所以去掉表头和表尾的tr标签节点
tr_list.pop(0) # 删除表头
tr_list.pop() # 删除表尾
# 剩下的是10个职位数据信息
if len(tr_list) == 0:
print('超出页码范围')
break
for tr in tr_list:
td_list = tr.xpath('./td')
# 需要职位名称,类别,人数,地点,发布时间
# 名称
job_name_list = td_list[0].xpath('./a/text()')
job_name = getDataFormList(job_name_list)
# print(job_name)
# 类别
job_type_list = td_list[1].xpath('./text()')
job_type = getDataFormList(job_type_list)
# 人数
job_number_list = td_list[2].xpath('./text()')
job_number = getDataFormList(job_number_list)
# 地点
job_addr_list = td_list[3].xpath('./text()')
job_addr = getDataFormList(job_addr_list)
# 发布时间
job_time_list = td_list[4].xpath('./text()')
job_time = getDataFormList(job_time_list)
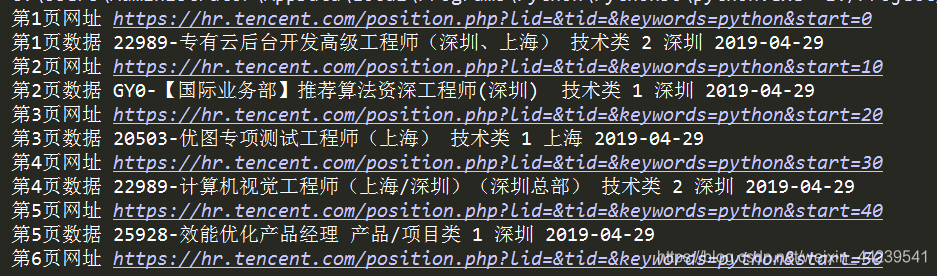
print('第%s页数据'%(page),job_name, job_type, job_number, job_addr, job_time)
page += 1
# print(tr_list)
# print(len(tr_list))
运行结果:
(2)爬取扇贝网
爬取 https://www.shanbay.com/wordlist/110521/232414/?page 中三页所有的单词信息
具体代码
import requests
from lxml import etree
base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%d'
# 判空
def getDataformList(temple_list):
if len(temple_list)>0:
return temple_list[0]
else:
return ''
for page in range(1, 4, 1):
url = base_url % (page)
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
# with open('shanbei.html', 'w', encoding=response.encoding) as fp:
# fp.write(response.text)
tree = etree.HTML(response.text)
tr_list = tree.xpath('//div[@class="span8"]/table/tbody/tr[@class="row"]')
# print(tr_list)
for tr in tr_list:
# 英文
English_list = tr.xpath('.//td[@class="span2"]/strong/text()')
English = getDataformList(English_list)
# 汉语
Chinese_list = tr.xpath('.//td[@class="span10"]/text()')
Chinese = getDataformList(Chinese_list).replace('\n','')
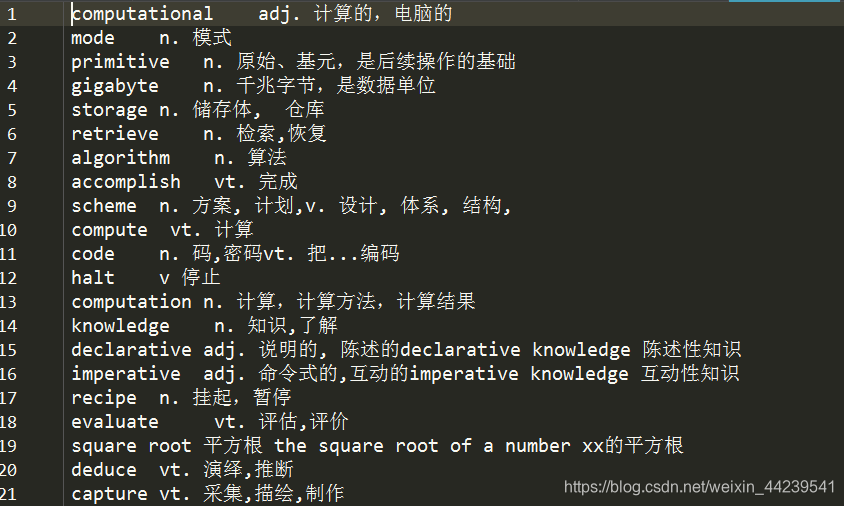
print(English+':'+Chinese)
with open('shanbei.txt','a',encoding=response.encoding) as fp:
fp.write(English+'\t'+Chinese+'\n')运行结果;
3、拼接路径
拼接路径用到了python自带的urllib模块
具体用法如下:
from urllib import request
# request 用法
# request.urljoin(base= '请求路径', url='相对路径' )
base_url = 'http://www.langlang2017.com/index.html'
src = 'fengjing,png'
full_url = request.urljoin(base_url,src)
print(full_url)运行结果:
