mysql高级
前言
一步步走来,终于是要到头了,加油呀,本篇内容也非常重要,实用性很强。在第一家公司时(…炬…),就遇到了被勒索病毒攻击的情况,当时大家发现数据库数据全没了,然后就发现让往特定账户转比特币的英文记录-.-,因此,数据库备份很重要,不管是物理磁盘坏掉、自然灾害,还是黑客攻击,都可以保障数据不丢失。文章课程链接:MySQL数据库教程天花板,mysql安装到…
1、物理备份与逻辑备份
物理备份:备份数据文件,转储数据库物理文件到某一目录。物理备份恢复速度比较快,但占用空间比较大,MySQL中可以用xtrabackup 工具来进行物理备份。
逻辑备份:对数据库对象利用工具进行导出工作,汇总入备份文件内。逻辑备份恢复速度慢,但占用空间小,更灵活。MySQL 中常用的逻辑备份工具为 mysqldump 。逻辑备份就是 备份sql语句,在恢复的时候执行备份的sql语句实现数据库数据的重现。
2、mysqldump实现逻辑备份
2.1 备份一个数据库
mysqldump命令执行时,可以将数据库备份成一个文本文件,该文件中实际上包含多个CREATE和 INSERT语句,使用这些语句可以重新创建表和插入数据。
1、查出需要备份的表的结构,在文本文件中生成一个CREATE语句
2、将表中的所有记录转换成一条INSERT语句。
基本语法:
mysqldump -u 用户名称 -h 主机名称 -p密码 待备份的数据库名称[tbname,[tbname…]]> 备份文件名称.sql
2.2 备份全部数据库
备份整个实例,可以使用 --all-databases 或 -A 参数
语法:
mysqldump -uroot -pxxxxxx --all-databases > all_database.sql
mysgldump -uroot -pxxxxxx -A > all_database.sql
2.3 备份部分数据库
使用 --databases 或-B 参数了,该参数后面跟数据库名称,多个数据库间用空格开,如果指定databases参数,备份文件中会存在创建数据库的语句,如果不指定参数,则不存在。
语法:
mysqldump -u user -h host -p --databases [数据的名称1[数据库的名称2…] > 备份文件名称.sql
例子:
mysqldump -uroot -p --databases database1 database2 > two_database.sql
2.4 备份部分表
使用场景是备份变更前的数据
语法:
mysqldump -u user -h host -p 数据库的名称 [表名1 [表名2…]] 备份文件名称.sql
例子:
mysqldump -uroot -p database1 book > book.sql
2.5 备份单表的部分数据
当我们只需要备份某张表中的部分数据,可以使用 – where 选项,where 后面跟过滤条件
语法:
mysqldump -u user -h host -p 数据库名 表名 --where=条件 备份文件名称…sql
例子:id小于 10 的备份
mysqldump -uroot -p atguigu student --where= “id < 10” > student_part_id10_low_bak.sql
2.6 排除某些表的备份
如果我们想备份某个库,但是某些表数据量很大或者与业务关联不大,这个时候可以考虑排除掉这些表,同样的,选项 --ignore-table 可以完成这个功能。
语法:
mysqldump -uroot -p 库名 --ignore-table=库名.表名 > 备份文件名称.sql
例子:
mysqldump -uroot -p database1 --ignore-table=database1.student > no_stu_bak.sql
2.7 只备份结构或只备份数据
只备份结构的话可以使用 --no-data 简写为 -d 选项;只备份数据可以使用–no-create-info 简写为 -t 选项。
- 只备份结构
mysqldump -uroot -p database1 --no-data > no_data_bak.sql
- 只备份数据
mysqldump -uroot -p database1 --no-create-info > no_create_info_bak.sql
2.8 备份中包含数据存储、函数、事件
mysqldump备份默认是不包含存储过程,自定义函数及事件的。可以使用 --routines 或 -R 选项来备份存储过程及函数,使用 --events 或 -E 参数来备份事件。
查看当前库有哪些存储过程或者函数:
SELECT SPECIFIC_NAME,ROUTINE_TYPE ROUTINE_SCHEMA FROM information-schema.Routines WHERE ROUTINE_SCHEMA=“表名”;
备份atguigu库的数据,函数以及存储过程
mysqldump -uroot -p -R -E --databases database1 > fun_database1_bak.sql
3、mysql命令恢复数据
使用mysqldump命令将数据库中的数据备份成一个文本文件。需要恢复时,可以使用 mysql命令 来恢复备份的数据。
mysql命令可以执行备份文件中的 CREATE语句和 INSERT语句。
通过CREATE语句来创建数据库和表。通过INSERT语句来插入备份的数据。
基本语法:
mysql -u root -p [dbname] s backup.sql
说明:dbname参数表示数据库名称。该参数是可选参数,可以指定或不指定。指定数据库名时,表示还原该数据库下的表。此时需要确保MySQL服务器中已经创建了该名的数据库。不指定数据库名时,表示还原文件中所有的数据库。此时sql文件中包含有CREATE DATABASE语句,不需要MySQL服务器中已存在这些数据库。
3.1 单库备份中恢复单库
使用root用户,将备份导入数据库中,命令如下:
mysql -uroot -p < database1.sql # 如果备份文件中包含了创建数据库的语句,则恢复的时候不需要指定数据库名称
mysql -uroot -p database2 < database1.sql # 恢复到指定的数据库,前提是要建好库
3.2 全量备份恢复
具有全量备份,现在想整个恢复:
mysql -u root -p < all.sql
3.3 从全量备份中恢复单库
我们只想恢复某一个库,但是我们有的是整个实例的备份,这个时候我们可以从全量备份中分离出单个库的备份。
sed -n ‘/^-- Current Database: 库名/,/^-- Current Database: /p’ alldatabase.sql > database1.sql # 先将 database1 涉及的sql分离,在进行单库恢复操作
3.4 从单库备份中恢复单表
说我们知道哪个表误操作了,那么就可以用单表恢复的方式来恢复。
用shell语法分离出创建表的语句及插入数据的语句后 再依次导出即可完成恢复
cat atguigu.sgl sed -e ‘/./H;S!d;)’ -e ‘x;/CREATE TABLE ‘class’/!d;g’> class_structure.sql
cat atquigu.sgl grep --ignore-case 'insert into ‘class’ > class_data.sql
source class_structure.sql; # 执行SQL
source class_data.sql;
4、物理备份和恢复:直接复制整个数据库
这种方式只适合 MyISAM 存储引擎,直接将数据文件复制备份就行。恢复时,直接将备份的数据文件复制到文件目录下重启服务。
5、表的导出与导入
5.1 表的导出
- 使用SELECT…INTO OUTFILE导出文本文件
mysql默认对导出的目录有权限限制,也就是说使用命令行进行导出的时候,需要指定目录进行操作.查询secure_file_priv值:
SHOW GLOBAL VARIABLES LIKE%secure%';
说明:
如果设置为empty,表示不限制文件生成的位置,这是不安全的设置;
如果设置为一个表示路径的字符串,就要求生成的文件只能放在这个指定的目录,或者它的子目录;
如果设置为NULL,就表示禁止在这个MySQL实例上执行select …into outfile 操作;
导出举例:
SELECT * FROM account INTO OUTFILE “/var/lib/mysql-files/account.txt”;
- 使用mysqldump命令导出文本文件
mysqldump -uroot -p -T “/var/lib/mysql-files/” database1 account
将生成 .sql文件和 .txt 文件,前者为表结构,后者为数据
- 使用mysql命令导出文本文件
mysql -uroot -p --execute=“SELECT * FROM account;” database1 > “var/lib/mysql-files/account.txt”;
5.2 表的导入
- 使用LOAD DATAINFILE方式导入文本文件
SELECT * FROM database1.account INTO OUTFILE ‘/var/lib/mysql-files/account_0.txt’; # 导出
LOAD DATA INFILE ‘/var/lib/mysql-files/account_0.txt’ INTO TABLE database1.account; # 导入
- 使用mysqlimport方式导入文本文件
SELECT * FROM database1.account INTO OUTFILE ‘/var/lib/mysgl-files/account.txt’ FIELDS TERMINATED BY ‘,’ ENCLOSED BY ‘"’; # 导处
mysqlimport -uroot -p database1 ‘/var/lib/mysql-files/account.txt ’ --fields-terminated-by= ‘,’ --fields-optionally-enclosed-by=’"’ # 导入
导入可以加的其他参数可自行查阅资料
6、数据库迁移
6.1 概述
数据迁移(data migration)是指选择、准备、提取和转换数据,并将数据从一个计算机存储系统永久地传输到另一个计算机存储系统的过程。此外,验证迁移数据的完整性 和 退役原来旧的数据存储,也被认为是整个数据迁移过程的一部分。
数据库迁移的原因是多样的,包括服务器或存储设备更换、维护或升级,应用程序迁移,网站集成,灾难恢复和数据中心迁移。
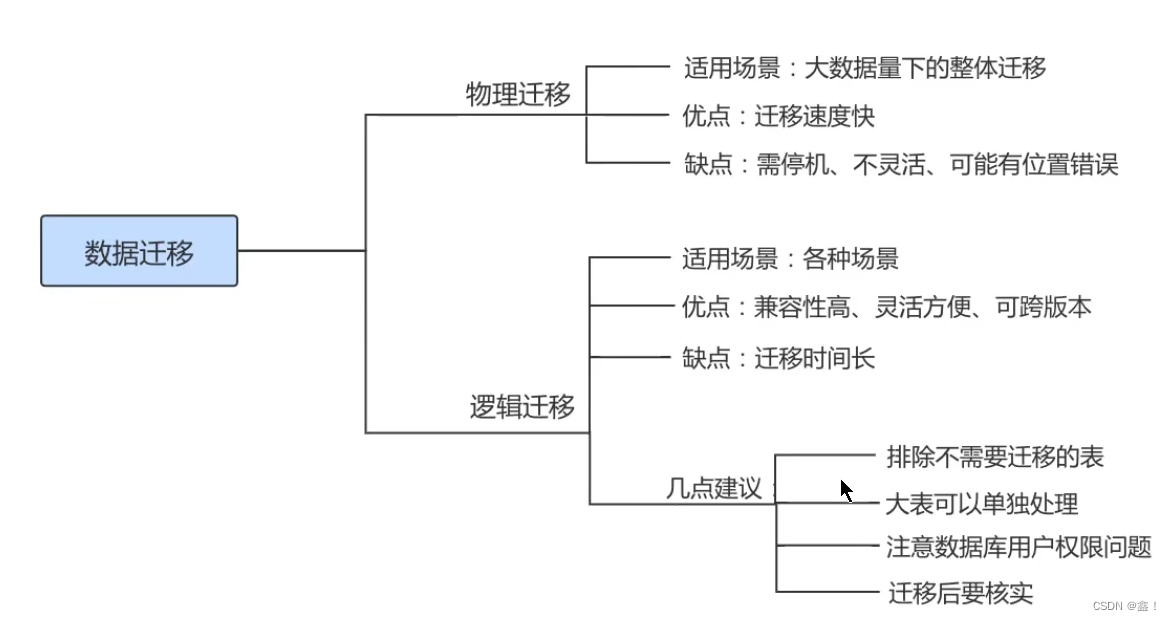
根据不同的需求可能要采取不同的迁移方案,但总体来进,MySQL 数据迁移方案大致可以分为 物理迁移 和 逻辑迁移两类。通常以尽可能自动化 的方式执行,从而将人力资源从繁琐的任务中解放出来。
6.2 迁移方案
- 物理迁移(直接把数据文件、日志文件、配置文件等复制过来,这种方式只适用 MyISAM存储引擎)
物理迁移适用于大数据量下的整体迁移。使用物理迁移方案的优点是比较快速,但需要停机迁移并且要求 MySQL版本及配置必须和原服务器相同,也可能引起未知问题。
物理迁移包括拷贝数据文件和使用 XtraBackup 备份工具两种 - 逻辑迁移
逻辑迁移适用范围更广,无论是 部分迁移 还是 全量迁移,都可以使用逻辑迁移。逻辑迁移中使用最多的就是通过mysqldump 等备份工具
6.3 迁移注意点
- 相同版本的数据库之间迁移注意点
方式1:因为迁移前后MySQL数据库的 主版本号相同,所以可以通过复制数据库目录来实现数据库迁移,但是物理迁移方式只适用于MyISAM引擎的表。对于InnoDB表,不能用直接复制文件的方式备份数据库。
方式2:最常见和最安全的方式是使用 mysqldump命令导出数据,然后在目标数据库服务器中使用MySQL命令导入 - 不同版本的数据库之间迁移注意点
高版本的MySQL数据库通常都会 兼容低版本,因此可以从低版本的MySQL数据库迁移到高版本的MySQL数据库。
但旧版本与新版本的MySQL可能使用不同的默认字符集,会导致不能正常显示数据,如果数据库中有中文数据,那么迁移过程中需要对 默认字符集进行修改 - 不同数据库间的迁移
咱就不要想这么多了,如果有这种场景,那还是交给DBA
6.4 迁移小结
7、如何删库不跑路
传统的高可用架构是不能预防误删数据的,因为主库的一个drop table命令,会通过binlog传给所有从库和级联从库,进而导致整个集群的实例都会执行这个命令。
为了找到解决误删数据的更高效的方法,我们需要先对和MySQL相关的误删数据,做下分类:
1.使用delete语句误删数据行;
2.使用drop table或者truncate table语句误删数据表;
3.使用drop database语句误删数据库;
4.使用rm命令误删整个MySQL实例;
7.1 delete:误删行
处理措施:数据恢复
使用Flashback工具 恢复数据
原理:修改binlog 内容,拿回原库重放。如果误删数据涉及到了多个事务的话,需要将事务的顺序调过来再执行(逆过程)。
使用前提:binlog_format=row 和 binlog_row_image=FULL处理措施:预防
代码上线前,必须 SQL审查、审计。
建议可以打开 安全模式,把 sql_safe_updates 参数设置为on。强制要求加 where 条件且where后需要是索引字段,否则必须使用limit。否则就会报错。如果确实需要使用,可以用 where id > 0 的条件
7.2 truncate/drop:误删库/表
背景:
delete全表是很慢的,需要生成回滚日志、写redo、写binlog。所以,从性能角度考虑,优先考虑使用truncate table或者drop table命令。
使用delete命令删除的数据,还是可以用Flashback来恢复。而使用truncate /drop table和drop database命令删除的数据,就没办法通过Flashback来恢复了。因为,即使我们配置了binlog format=row,执行这三个命令时,记录的binlog还是statement格式。binlog里面就只有一个truncate/drop 语句,这些信息是恢复不出数据的。
方案:
这种情况下恢复数据,需要使用 全量备份 与 增量日志 结合的方式
方案的前提: 有定期的全量备份,并且实时备份binlog。
7.3 预防使用 truncate / drop 误删库/表
- 权限分离
限制帐户权限,核心的数据库,一般都 不能随便分配写权限,想要获取写权限需要 审批。比如只给业务开发人员DML权限,不给truncate/drop权限。即使是DBA团队成员,日常也都规定只使用只读账号,必要的时候才使用有更新权限的账号。
不同的账号,不同的数据之间要进行 权限分离,避免一个账号可以删除所有库。
2. 制定操作规范
比如在删除数据表之前,必须先对表做改名操作(比如加 _to_be_deleted)。然后,观察一段时间,确保对业务无影响以后再删除这张表。
3. 设置延迟复制备库
简单的说延迟复制就是设置一个固定的延迟时间,比如1个小时,让从库落后主库一个小时。出现误删除操作1小时内,到这个备库上执行 stop slave ,再通过之前介绍的方法,跳过误操作命令,就可以恢复出需要的数据。这里通过 CHANGE MASTER TO MASTER_DELAY = N命令,可以指定这个备库持续保持跟主库有N秒的延识。比如把N设置为3600,即代表1个小时。
7.4 rm:误删MySQL实例
对于一个有高可用机制的MySQL集群来说,不用担心 rm 删除数据。因为只删掉其中某一个节点数据的话,HA系统就会选出一个新的主库,从而保证整个集群的正常工作。我们把这个节点上的数据恢复回来后,再接入整个集群就好了。
但如果是恶意地把整个集群删除,哪哪就需要考虑跨机房备份,跨城市备份。
end…
如果总结的还行,就点个赞呗 @_@ 如有错误,欢迎指正!