目录
1、HashMap解决了什么问题?
HashMap底层使用数组加(jdk1.7以前)链表(jdk1.8以后在链表节点不小于8的时候会调整为红黑树)的结构完美的解决了数组和链表的问题,
使得查询和插入,删除的效率都很高,每个元素节点都有一个next属性指向下一个节点
,这里由数组结构变成了数组+链表结构(图是别人的)
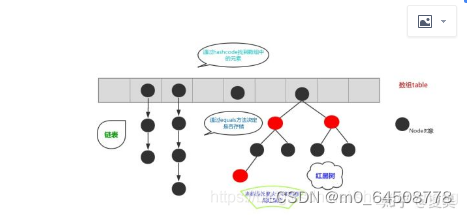
HashMap特点:
它是查询效率最高的数据结构,因为它是通过计算散列码来决定存储位置的,无论数据有多大,它的查询速度都是固定的。
2、怎么实现呢?
计算出键的hashcode,该值用来定位要将这个元素存放到数组中的什么位置,如果数组这个位置索引的地方是空的,直接将元素放进去就好了。如果已经有元素占据了索引该位置,需要使equals比较该位置的key和当前key是否相等。相等就覆盖,不相等就往链表后面加数据。
什么是hashcode:
在Object类中有一个方法:public native int hashCode();调用这个方法会生成一个int型的整数,我们叫它哈希码,哈希码和调用它的对象地址和内容有关
hashcode特点:
对于同一个对象如果没有被修改(使用equals比较返回true)那么无论何时它的hashcode值都是相同的,对于两个对象如果他们的equals返回true,那么他们的hashcode值也相等
根据hashcode的特点,用key的hashcode % 数组初始容量,在数组上确定唯一位置
初始容量大小和加载因子:
初始容量大小是创建时给数组分配的容量大小,默认值为16,加载因子默认0.75f,用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容。在做扩容的时候会生成一个新的数组,原来的所有数据要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。
3、具体代码演示
定义一个Node节点类
import java.util.Map;
public class Node<K, V> implements Map.Entry<K, V> {
private K key;
private V value;
//指向下一节点
Node<K, V> nextNode;
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
V res = this.value;
this.value = value;
return res;
}
public Node<K, V> getNextNode() {
return nextNode;
}
public void setNextNode(Node<K, V> nextNode) {
this.nextNode = nextNode;
}
public Node() {
}
public Node(K key, V value, Node<K, V> nextNode) {
this.key = key;
this.value = value;
this.nextNode = nextNode;
}
}定义HashMap实现类实现Map
import java.util.*;
public class HashMapImpl<K, V> implements Map<K, V> {
private int size;//容器的元素数量
private int length = 16;//数组的初始长度
Node<K, V>[] kvNode = new Node[length];//链表类型的数组
/**
* 得到长度
*/
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
/**
* 是否包含key值
*/
@Override
public boolean containsKey(Object key) {
//利用hashcode对数组长度求余得到唯一的节点,一定在数组长度范围内(1~16),如1617%16,在数组下标为1的地方
Node<K, V> node = kvNode[key.hashCode() % length];
while (node != null) {
if (node.getKey().equals(key)) {
return true;
}
node = node.nextNode;//指针移动
}
return false;
}
//和判断是否包含key的写法类似,遍历用equals()比较值
@Override
public boolean containsValue(Object value) {
return false;
}
/**
* 通过key拿到value的值
*/
@Override
public V get(Object key) {
if (key == null) {
System.out.println("key不能为空");
return null;
}
Node<K, V> node = kvNode[key.hashCode() % length];
while (node != null) {
if (node.getKey().equals(key)) {
return node.getValue();
}
node = node.nextNode;
}
return null;
}
/**
* 将key,value放入的方法
*
* @param key 键
* @param value 值
* @return 修改前value的值
*/
public V putMethod(K key, V value) {
//key在数组中的下标,也是链表的头
int index = key.hashCode() % length;
Node<K, V> node = kvNode[index];
//如果key存在,修改value的值,返回旧value的值
while (node != null) {
if (node.getKey().equals(key)) {
//临时变量存储改变之前的value
V val = node.getValue();
node.setValue(value);
return val;
}
node = node.nextNode;
}
//如果key不存在
//原头节点下标指向新创建的节点,新节点又指向头节点,相当于new一个节点在原头节点前面作为新头节点
kvNode[index] = new Node<>(key, value, kvNode[index]);//new一个节点,nextNode指向头节点
return null;
}
@Override
public V put(K key, V value) {
//原数组长度超过原来的四分之三调用扩容方法
if (size > length * 3 / 4) {
capacityExpansion();
}
V val = putMethod(key, value);
//如果返回为null说明没有找到key,添加新元素,增加长度
if (val == null) size++;
return val;
}
/**
* 数组扩容
*/
private void capacityExpansion() {
length *= 2;//将长度变为原来的两倍
Node<K, V>[] node = kvNode;//用一个新引用指向旧数组
kvNode = new Node[length];//将原来的数组引用指向新的扩容了的数组(扩容的数组就可以调用putMethod函数)
//再把旧数组的元素放到扩容的数组里
for (int i = 0; i < node.length; i++) {
Node<K, V> node1 = node[i];
while (node1 != null) {
putMethod(node1.getKey(), node1.getValue());
node1 = node1.nextNode;
}
}
}
@Override
public V remove(Object key) {
if (key == null) {
System.out.println("key不能为空");
return null;
}
Node<K, V> node = kvNode[key.hashCode() % length];
//头节点特殊判断,如果key为头节点,删除头节点
if (node.getKey().equals(key)) {
kvNode[key.hashCode() % length] = node.nextNode;
size--;
return node.getValue();
}
//不为头节点,第一个指向第二个节点的指针指向第三个完成删除
while (node.nextNode != null) {
if (node.nextNode.getKey().equals(key)) {
node.nextNode = node.nextNode.nextNode;
size--;
return node.getValue();
}
node = node.nextNode;
}
return null;
}
/**
* 清空HashMap
*/
@Override
public void clear() {
//相当于清空数组
for (int i = 0; i < length; i++) {
kvNode[i] = null;
}
System.out.println("数据已清空");
size = 0;
}
/**
* 返回所有的key值
*/
@Override
public Set<K> keySet() {
Set<K> set = new HashSet<>();
for (int i = 0; i < kvNode.length; i++) {
Node<K, V> node1 = kvNode[i];
while (node1 != null) {
set.add(node1.getKey());
node1 = node1.nextNode;
}
}
return set;
}
/**
* 返回所有的value值
*/
@Override
public Collection<V> values() {
Collection<V> collection = new ArrayList<>();
for (int i = 0; i < kvNode.length; i++) {
Node<K, V> node1 = kvNode[i];
while (node1 != null) {
collection.add(node1.getValue());
node1 = node1.nextNode;
}
}
return collection;
}
/**
* 返回一个集合包含所有的节点
*/
@Override
public Set<Entry<K, V>> entrySet() {
Set<Entry<K, V>> set = new HashSet<>();
for (int i = 0; i < kvNode.length; i++) {
Node<K, V> node = kvNode[i];
while (node != null) {
set.add(node);
node = node.nextNode;
}
}
return set;
}
/**
* 重写toString方法打印HashMap
*/
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Entry<K, V> res : entrySet()) {
stringBuilder.append(res.getKey()).append(",").append(res.getValue()).append("\n");
}
return stringBuilder.toString();
}
/**
* 这个方法用的少,偷个懒
*/
@Override
public void putAll(Map<? extends K, ? extends V> m) {
}
}