目录
简单记录对ArrayList、LinkedList以及HashMap常用容器部分源码解读
1.ArrayList
数组
①无惨构造
// 初始化一个空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;

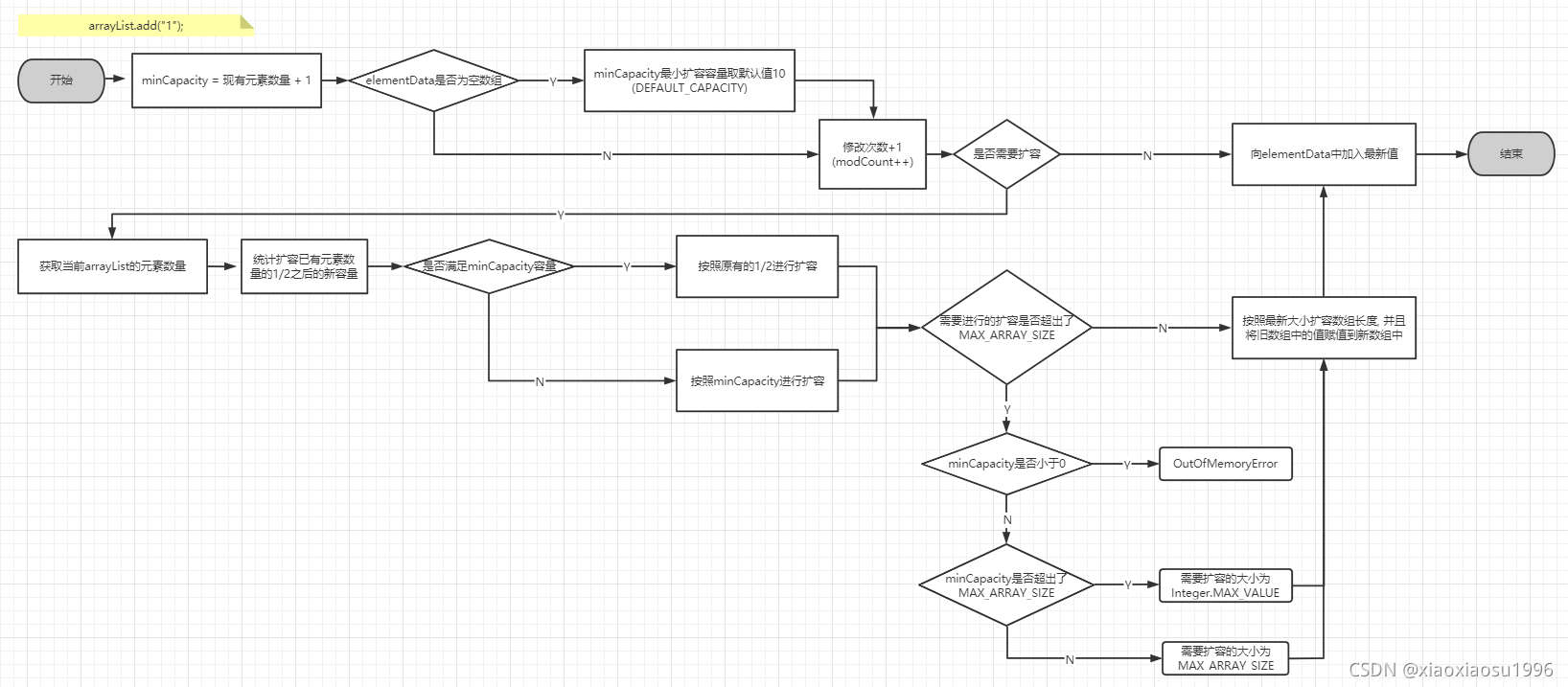
②add(E e)
- 确定容量大小
- 如果是空数组, 则取
size + 1与10中最大值, 反之确定容量为size + 1 - 修改次数+1
size + 1> 当前数组容量, 则拓展数组容量, 反之不做处理- 将当前数组容量扩充原数组容量的一半
- 新容量 <
size + 1, 则确定容量为size + 1 - 新容量 >
Integer.MAX_VALUE - 8size + 1< 0, 则说明已经超出Integer.MAX_VALUE, 报OutOfMemoryError异常size + 1>Integer.MAX_VALUE - 8, 则确定容量为Integer.MAX_VALUE, 反之为Integer.MAX_VALUE - 8
- 新容量 <
- 将数组元素copy到新数组中
- 将当前数组容量扩充原数组容量的一半
- 赋值
arr[size] = e - 元素量(指针位置后移)+1, 即:
size++
总结说明
size含义: 现有元素量, 下个待新增元素位置size + 1: 未来所需要的容量- 初次加值, 如未指定容量大小, 则扩容
10 - 容量扩容一般扩容原始容量的一半, 即
newCap = oldCap + (oldCap >> 2)
③remove(int index)
- 检查索引是否越界, 如果越界则会出现
IndexOutOfBoundsException异常 - 修改次数
+1 - 获取
index位置的元素, 最后会进行返回 - 计算移动数量
index往后元素全体前移一位- 元素量(指针位置前移移)-1, 即:
--size

PS: elementData使用了transient进行修饰, 这样做的好处是因为elementData存在预留空间(可以看做是缓存数组), 在序列化时, 未使用到的空间并不需要, 以此节省空间提高执行效率
2.LinkedList
双向链表
①无惨构造
未做任何操作

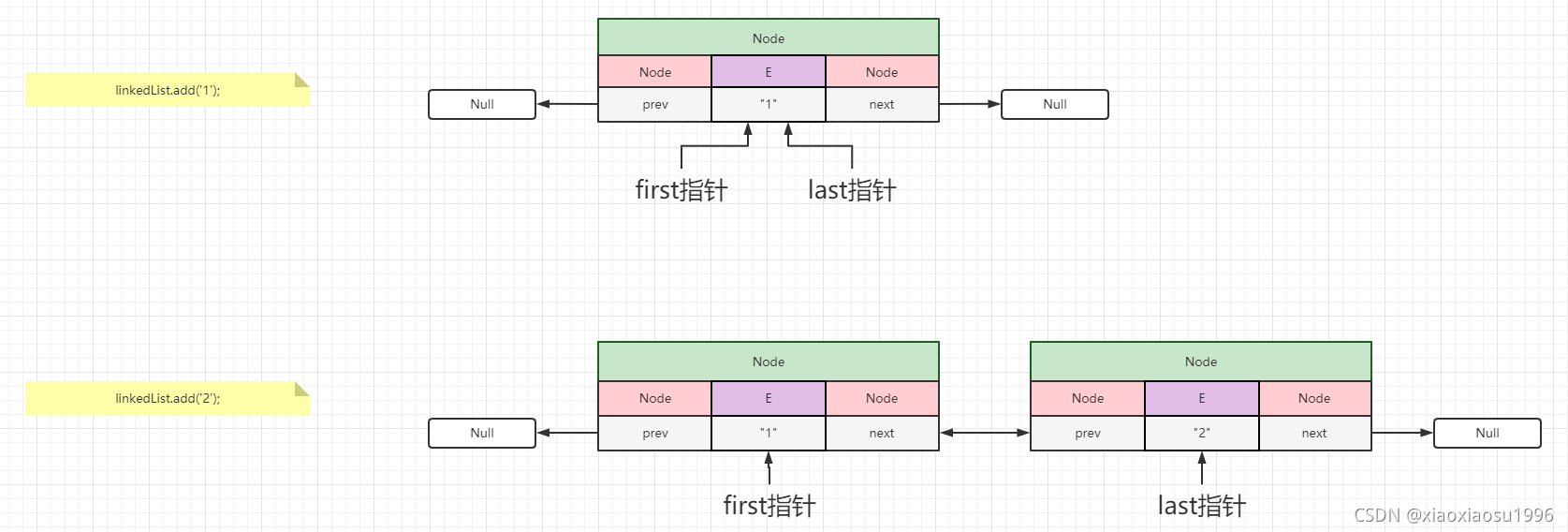
②add(E e)
目的:将e作为最后一个元素进行链接
- 获取尾节点
last - 获取新节点
elast == null, 则头结点 为e- 否则,
e链接到last后
- 元素量
+1 - 修改次数
+1
③remove(int index)
- 检查索引是否越界, 如果越界则会出现
IndexOutOfBoundsException异常 - 将
index节点断开链接
- 获取
index处的节点信息- 索引 < 总长度的一半, 则从头节点往后遍历, 直到获取到
index处节点 - 索引 >= 总长度的一半, 则从尾节点往前遍历, 直到获取到
index处节点
- 索引 < 总长度的一半, 则从头节点往后遍历, 直到获取到
- 断开
index节点- 获取
index节点前节点prev, 后节点nextprev == null, 则说明当前节点为头结点, 将头结点设置为nextprev != null, 则prev.next = nextnext == null, 则说明当前节点为尾结点, 将尾结点设置为prevnext != null, 则next.prev = prev
- 将
index节点元素置null(回收) - 元素量
-1 - 修改次数
+1
- 获取
补充
index节点查找, 是从中折半, 进行查询

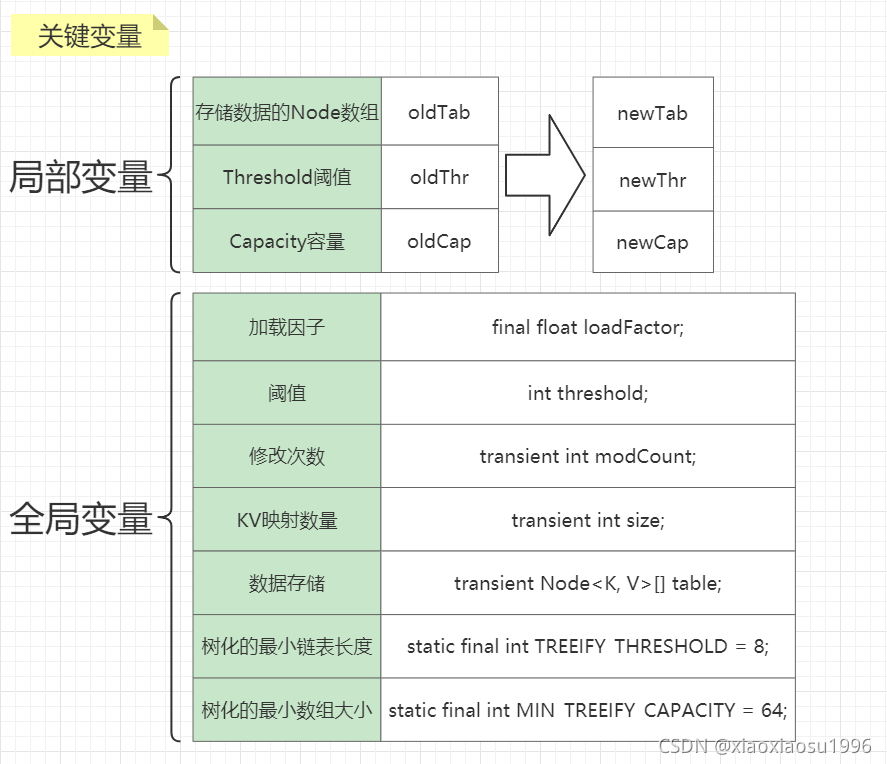
3.HashMap
数组 + 链表 <-> 红黑树
①无惨构造
// 设置默认负载因子: 0.75
this.loadFactor = DEFAULT_LOAD_FACTOR;
②put(K key, V value)
- 扰动函数
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
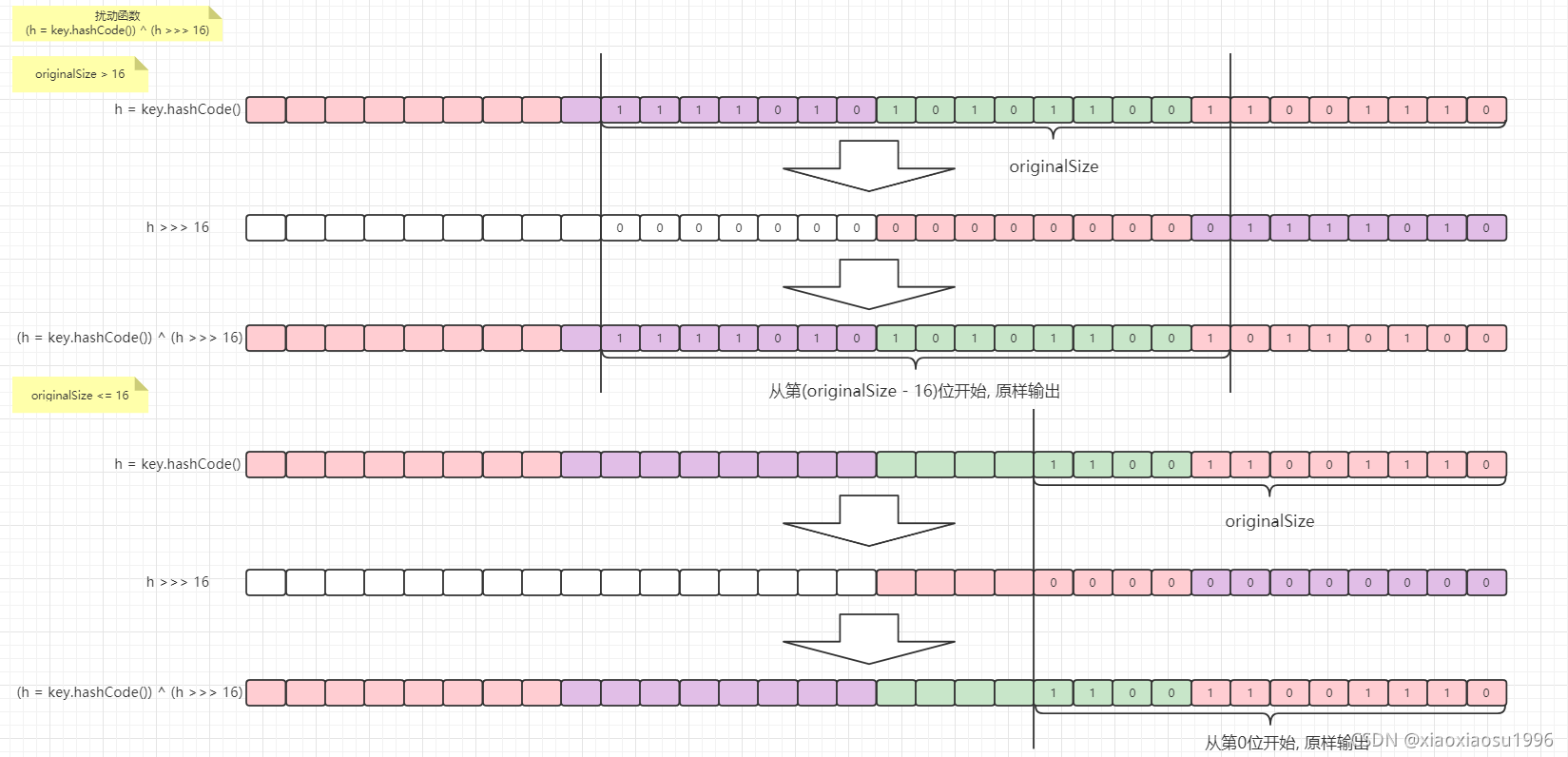
总结
只有当
key的hash值大于16位时, 高半区16与低半区16进行^操作, 以此增加低半区随机性
初始化判断
- 扩容
当前
key值是否已存在- 不存在, 则直接赋值
- 存在, 则头结点(以下称为
p)的操作p.key以及p.hash与之相等, 直接覆盖赋值p instanceof TreeNode- 遍历
pp.next == null- 则
p.next = 新节点 - 是否满足树化(
binCount >= TREEIFY_THRESHOLD - 1)table.length < MIN_TREEIFY_CAPACITY- 扩容
- 树化
- 则
p.key以及p.hash与之相等, 直接覆盖赋值
- 如果是已有值节点, 新值替换旧值
修改次数
+1现有
KV映射数量(算上新增的值) > 阈值- 扩容
补充说明
- 容量始终为
2的次幂, 最大容量MAXIMUM_CAPACITY, 即2^30 - 每次扩容, 都是原始的一倍
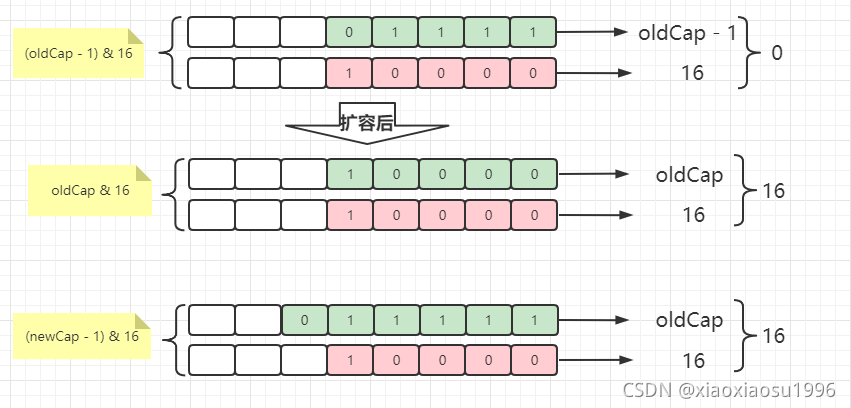
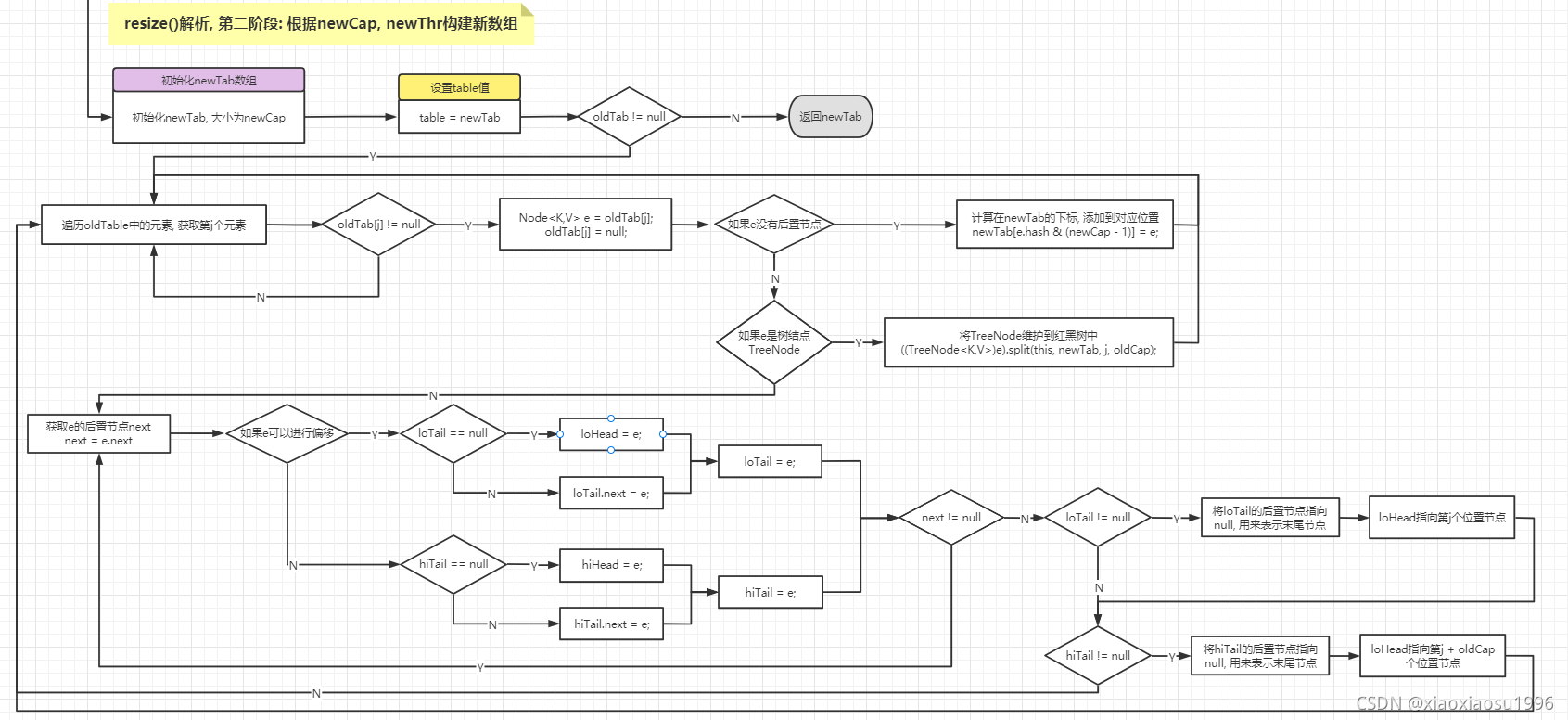
(n - 1) & hash与e.hash & oldCap
1.重新确定存放位置
2.oldCap & e.hash用在扩容后, 作为节点是否可以进行再偏移的依据
1.
(n - 1) & hash用在扩容前, 计算存放节点的索引值
2.依据oldCap & e.hash == 0计算当前节点是否还能再偏移
3.在扩容结束后, 后续插值计算位多出一位
则(newCap - 1) & hash == (oldCap - 1) & hash + oldCap
4.根据上图, 不难看出hash < 16不进行偏移, 反之偏移一个oldCap
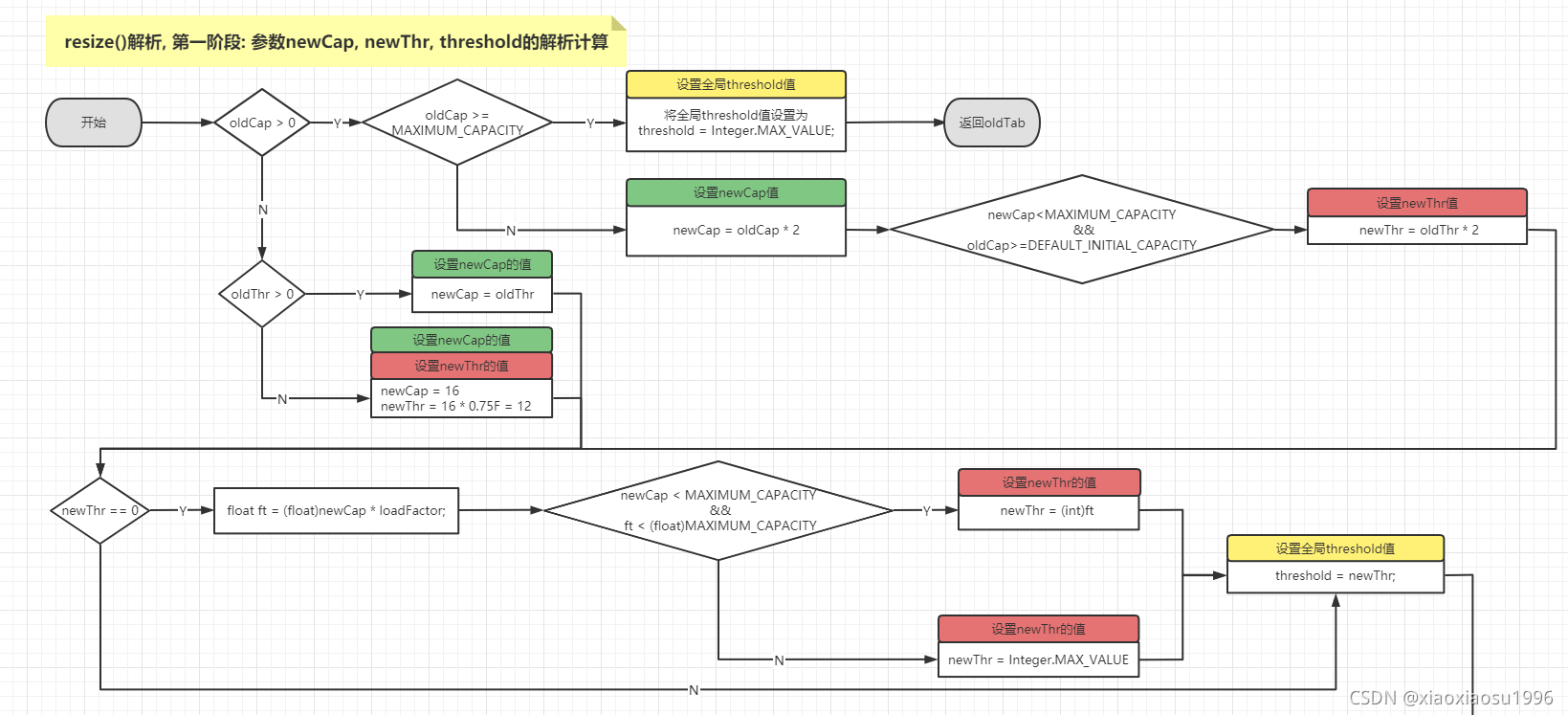
- 扩容函数
resize()
触发点
table == null || table.length == 0++size > thresholdnode链表长度大于8, 进行树化判断, 且table.length > 64- 为什么说
node链表长度大于8, 而不是等于8呢
因为当bitCount == 7的时候, 实际长度已经为8, 而在做判断前, 又存在链接新节点的操作, 所以大于是8
p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) { treeifyBin(tab, hash); }- 为什么说
处理
版权声明:本文为xiaoxiaosu1996原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。