上一期博客,我为大家介绍了我自己写的一套自动古诗文查询系统。当我们把我们想要的古诗文名字或者其中某句话输入系统时,它会自动将古文的全文打印出来。
今天我所写的这个功能就是基于上一期古诗文查询系统的。
这套系统大致效果是这样的:老师输入一篇古文,系统通过网站自动抓取所要古文,将古文中的一些字替换成下划线让学生们填空。
这套系统将解决一个语文老师很大的痛点:挖空古诗文时需要手动删去文章内容,再手动打出下划线。这套系统可以大大提升老师的办公效率。
逻辑梳理:
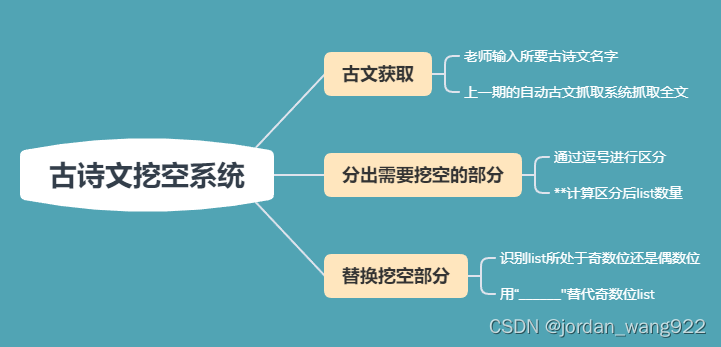
第一部分如何实现可以看我的上一期博客:Python实现自动古诗文查询系统_jordan_wang922的博客-CSDN博客
代码如下:
import requests
from bs4 import BeautifulSoup
poem = input("您需要查询的诗名或诗句:")
req = requests.get(url="https://so.gushiwen.cn/search.aspx?value=" + poem + "&valuej=" + poem[0])
req.encoding = "utf-8"
html = req.text
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("p", class_="source")
dd = poem.text.strip()
print(dd)
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("div", class_="contson")
ee = poem.text.strip()
print(ee)我们会抓取到以下结果:
接下来就到我们的第二部分,我的想法是这样的:古诗文中有许多逗号,我们可以用它来作为区分的点。如果没听懂,我用《出师表》举个例子:
先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。
通过逗号区分,就变为
['先帝创业未半而中道崩殂', '今天下三分', '益州疲弊', '此诚危急存亡之秋也。]
这一步其实非常简单,只需要用一行split语句就可以做的
这时候有一步非常关键:计算我们把整首古诗分成了几份,后面有大用
代码如下:
import requests
from bs4 import BeautifulSoup
from collections import Counter
# 随便定义一个list,也可以是自己生成的
print("老师您好,我是您的古诗文默写挖空助手")
poem = input("输入您需要挖空的古诗文:")
req = requests.get(url="https://so.gushiwen.cn/search.aspx?value=" + poem + "&valuej=" + poem[0])
req.encoding = "utf-8"
html = req.text
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("p", class_="source")
dd = poem.text.strip()
print(dd)
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("div", class_="contson")
ee = poem.text.strip()
ff = ee.split(",") #区分
#print(ff)
temp = ff
count = Counter(ee)
# 输出元素3的个数
#print(count[',']) #计算有多少个逗号从而计算分成了几份
num = count[',']
gg = ",".join(ff) #分完在将逗号还回去接下来我们要做到是让它隔开替换,换句话说,我们需要系统挖一个空,隔一个,再挖。
这里我们需要通过一些代码找到奇数位,如1,3,5,7,9:
number = 1
while number < num: #这里的num就是我们前面数的逗号的数量,不能超出这个数量
# 如果number / 2 余数为 1,代表是奇数
if number % 2 == 1:
#print(number)
order = number
number += 1最后一部就是替换了:
hh = gg.replace(ff[order],"______") #替换
gg = hh #变量每次都会换最终代码如下:
import random
import requests
from bs4 import BeautifulSoup
from collections import Counter
# 随便定义一个list,也可以是自己生成的
print("老师您好,我是您的古诗文默写挖空助手")
poem = input("输入您需要挖空的古诗文:")
req = requests.get(url="https://so.gushiwen.cn/search.aspx?value=" + poem + "&valuej=" + poem[0])
req.encoding = "utf-8"
html = req.text
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("p", class_="source")
dd = poem.text.strip()
print(dd)
soup = BeautifulSoup(req.text, features="html.parser")
poem = soup.find("div", class_="contson")
ee = poem.text.strip()
ff = ee.split(",")
#print(ff)
temp = ff
count = Counter(ee)
# 输出元素3的个数
#print(count[','])
num = count[',']
gg = ",".join(ff)
#print(ff[x + 2])
#for x in range(10):
number = 1
while number < num:
# 如果number / 2 余数为 1,代表是奇数
if number % 2 == 1:
#print(number)
order = number
number += 1
#print(hh)
hh = gg.replace(ff[order],"______")
gg = hh
print(hh)
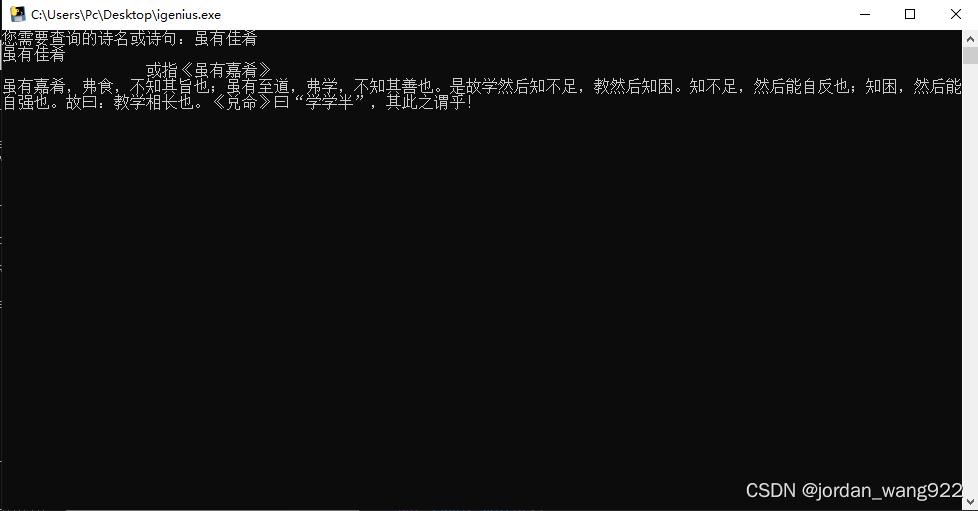
运行效果如下:

喜欢的话就点个赞吧!
版权声明:本文为jordan_wang922原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。