目录
1. 前言
为什么不能够 select * from table_name group by name 为什么一定不能是 *,而是某一个列或者某个列的聚合函数,group by 多个字段可以怎么去很好的理解呢?
2. group by 分组内幕
2.1. 数据准备
建表语句如下
CREATE TABLE `user_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`number` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
表数据如下
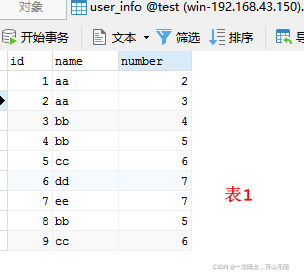
2.2. group by 分组查询
首先执行 SELECT * 语句
SELECT * FROM user_info GROUP BY `name`;
结果如下

再执行 SELECT name 如下查询
SELECT `name` FROM user_info GROUP BY `name`;
结果如下

2.3. group by 分组查询流程
下面的流程步骤未必正确,只是帮助更深入理解 group by 分组
2.3.1. 生成虚拟表
FROM user_info:该句执行后,结果就是原来的表(原数据表)FROM user_info GROUP BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示
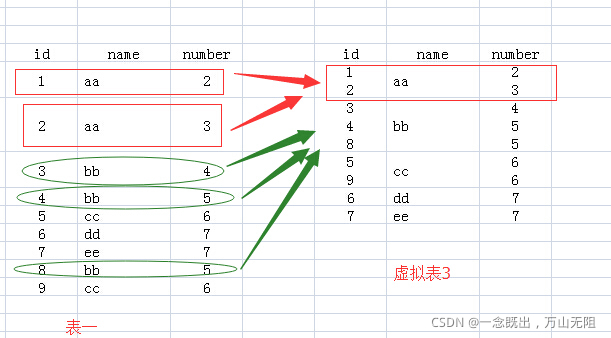
生成过程是这样的:group by name,那么找 name 那一列,具有相同 name 值的行,合并成一行,如对于 name 值为 aa 的,那么 <1 aa 2> 与 <2 aa 3> 两行合并成 1 行,所有的 id 值和 number 值写到一个单元格里面
2.3.2. 执行相关查询
接下来就要针对虚拟表 3 执行 select 了
- 如果执行
select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是有多个值的,而关系型数据库就是基于关系的,单元格中是不允许有多个值的。所以执行SELECT * FROM user_info GROUP BY name;时语句就报错了 - 我们再看
name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的 - 那么对于
id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如COUNT(id),SUM(number),而每个聚合函数的输入就是每一个多数据的单元格 - 如我们执行
SELECT `name`,SUM(number) FROM user_info GROUP BY `name`;
那么 SUM 就对虚拟表 3 的 number 列的每个单元格进行 SUM 操作,如对 name 为 aa 的那一行的 number 列执行 SUM 操作,即 2 + 3 = 5。最后执行结果如下

group by多个字段该怎么理解呢?如group by name, number,我们可以把name和number看成一个整体字段,以他们整体来进行分组的。如下图

- 接下来就可以配合
select和聚合函数进行操作了。如执行
SELECT `name`, sum(id) FROM user_info GROUP BY `name`, number;
结果如下图

3. group by 和 distinct 去重
3.1. 单列去重
SELECT DISTINCT `name` FROM user_info;
SELECT `name` FROM user_info GROUP BY name;
二者去重结果是一样的,如下

3.2. 多列去重
SELECT DISTINCT `name`,number FROM user_info;
SELECT `name`,number FROM user_info GROUP BY `name`,number;
- 注意:
distinct关键字对name, number都起作用,如果name相同,number不同是不会去重的
二者去重结果是一样的,如下

结论:对于单列或多列去重,使用 group by 和 distinct 结果是相同的
3.3. 执行方式
distinct主要是对数据两两进行比较,需要遍历整个表group by是在查询时先把数据按照分组字段分组出来再查询,当数据量较大时,group by速度要优于distinct
原文:https://blog.csdn.net/u014717572/article/details/80687042
版权声明:本文为weixin_38192427原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。