Flink中的RangePartition
导读:
RangePartition是Flink批处理中的一个算子,用于数据分区。
在Flink批处理的优化器中,会专门针对RangePartition算子进行一次优化,主要是通过采样算法对数据进行估计,并修改原job生成的OptimizedPlan。本文通过一个示例,对这个过程进行相关介绍。
示例如下:其主要功能是先进行RangePartition,然后进行WordCount。
public class MapPartition {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
if(args.length != 3){
System.out.println("the use is input output parallelism");
return;
}
//输入
String input = args[0];
//输出
String output = args[1];
//并行度
int parallelism = Integer.parseInt(args[2]);
//设置并行度
env.setParallelism(parallelism);
DataSet<String> text = env.readTextFile(input);
DataSet<Tuple2<String,Integer>> words = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] strings = value.split("\\W+");
for(String s:strings){
out.collect(new Tuple2<String, Integer>(s,1));
}
}
});
//进行Range-Partition
DataSet<Tuple2<String,Integer>> RangeWords = words.partitionByRange(0);
DataSet<Tuple2<String,Integer>> counts = RangeWords.groupBy(0).sum(1);
//写出结果
counts.writeAsText(output);
env.execute("this is a range partition job!!!");
}
}
上述代码正常来讲会形成如下的plan:
Source–>FlatMap–>Partition–>GroupReduce–>DataSink
但从WebUI上得到的结果是:

可以发现多了一些算子,这些算子就是用于采样的,接下来就详细跟踪一下这个过程。
其逻辑入口位于Optimizer类中:
#Optimizer.java line 519
plan.accept(new RangePartitionRewriter(plan));
RangePartitionRewriter实现了Visitor接口,通过accept()方法,其会对原Job生成的Plan中的各算子进行遍历,从而在RangePartition算子处改写相关逻辑。具体是在调用PostVisit()的时候进行判断是否是采用的RangePartition传输策略,代码如下:
//RangePartitionRewriter.java类中的postVisit()方法
public void postVisit(PlanNode node) {
if(node instanceof IterationPlanNode) {
IterationPlanNode iNode = (IterationPlanNode)node;
if(!visitedIterationNodes.contains(iNode)) {
visitedIterationNodes.add(iNode);
iNode.acceptForStepFunction(this);
}
}
//提取当前计划节点所有的的输入通道
final Iterable<Channel> inputChannels = node.getInputs();
for (Channel channel : inputChannels) {//遍历输入通道
ShipStrategyType shipStrategy = channel.getShipStrategy();
// Make sure we only optimize the DAG for range partition, and do not optimize multi times.
if (shipStrategy == ShipStrategyType.PARTITION_RANGE) {// 确保优化的通道的数据传输策略为范围分区
if(channel.getDataDistribution() == null) {
if (node.isOnDynamicPath()) {
throw new InvalidProgramException("Range Partitioning not supported within iterations if users do not supply the data distribution.");
}
//对该通道的范围分区进行“重写”,并将当前通道从源计划节点的通道中删除,然后加入新的通道集合
PlanNode channelSource = channel.getSource();
List<Channel> newSourceOutputChannels = rewriteRangePartitionChannel(channel);
//移除原来的OutgoingChannels
channelSource.getOutgoingChannels().remove(channel);
//添加新的OutgoingChannels
channelSource.getOutgoingChannels().addAll(newSourceOutputChannels);
}
}
}
}
当判断传输策略为Range Partition后,会调用rewriteRangePartitionChannel()方法对范围分区进行“重写”。
//RangePartitionRewriter.java类中的rewriteRangePartitionChannel()方法
private List<Channel> rewriteRangePartitionChannel(Channel channel) {
//RangePartition前驱Operator的输出?
final List<Channel> sourceNewOutputChannels = new ArrayList<>();
//sourceNode是RangePartition的前驱Operator
final PlanNode sourceNode = channel.getSource();
//targetNode就是RangePartition该Operator
final PlanNode targetNode = channel.getTarget();
//得到并行度
final int sourceParallelism = sourceNode.getParallelism();
final int targetParallelism = targetNode.getParallelism();
final Costs defaultZeroCosts = new Costs(0, 0, 0);
final TypeComparatorFactory<?> comparator = Utils.getShipComparator(channel, this.plan.getOriginalPlan().getExecutionConfig());
// 1. Fixed size sample in each partitions.
final int sampleSize = SAMPLES_PER_PARTITION * targetParallelism;
//SampleInPartition继承自RichMapPartitionFunction,用于各分区的采样,SampleInPartition在Flink-core中,RichMapPartitionFunction则在flink-runtime中
final SampleInPartition sampleInPartition = new SampleInPartition(false, sampleSize, SEED);
//得到RangePartition的前驱Operator的输出格式,即RangePartition的接受格式
final TypeInformation<?> sourceOutputType = sourceNode.getOptimizerNode().getOperator().getOperatorInfo().getOutputType();
//IntermediateSampleData中存储了元素值和权重weight
final TypeInformation<IntermediateSampleData> isdTypeInformation = TypeExtractor.getForClass(IntermediateSampleData.class);
final UnaryOperatorInformation sipOperatorInformation = new UnaryOperatorInformation(sourceOutputType, isdTypeInformation);
//MapPartitionOperatorBase是flink-core中的类
final MapPartitionOperatorBase sipOperatorBase = new MapPartitionOperatorBase(sampleInPartition, sipOperatorInformation, SIP_NAME);
//采样的Map节点,MapPartitionNode是flink-optimizer中dag包的类,其中只有DagConnection
final MapPartitionNode sipNode = new MapPartitionNode(sipOperatorBase);
//新建一个Channel,该Channel的source是RangePartition的前驱Operator
final Channel sipChannel = new Channel(sourceNode, TempMode.NONE);
sipChannel.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED);
//SingleInputPlanNode也是flink-optimizer中plan包的类,其中多了Channel input 的信息,应该是用在OptimizedPlan中的
final SingleInputPlanNode sipPlanNode = new SingleInputPlanNode(sipNode, SIP_NAME, sipChannel, DriverStrategy.MAP_PARTITION);
sipNode.setParallelism(sourceParallelism);
sipPlanNode.setParallelism(sourceParallelism);
sipPlanNode.initProperties(new GlobalProperties(), new LocalProperties());
sipPlanNode.setCosts(defaultZeroCosts);
//设置新加的Channel的target节点为新创建的采样MapPartitionNode
sipChannel.setTarget(sipPlanNode);
this.plan.getAllNodes().add(sipPlanNode);
sourceNewOutputChannels.add(sipChannel);
// 2. Fixed size sample in a single coordinator.
//SampleInCoordinator实现了GroupReduceFunction,用于将各分区的采样混合?
final SampleInCoordinator sampleInCoordinator = new SampleInCoordinator(false, sampleSize, SEED);
final UnaryOperatorInformation sicOperatorInformation = new UnaryOperatorInformation(isdTypeInformation, sourceOutputType);
//GroupReduceOperatorBase是flink-core中的
final GroupReduceOperatorBase sicOperatorBase = new GroupReduceOperatorBase(sampleInCoordinator, sicOperatorInformation, SIC_NAME);
//Reduce节点,GroupReduceNode-optimizer中dag的类,其中有DagConnection
final GroupReduceNode sicNode = new GroupReduceNode(sicOperatorBase);
//初始化一个新的Channel,其Source是1.中的Map算子
final Channel sicChannel = new Channel(sipPlanNode, TempMode.NONE);
sicChannel.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED);
//同理,根据sicNode和Channel信息构建PlanNode,是flink-optimizer中plan中的类
final SingleInputPlanNode sicPlanNode = new SingleInputPlanNode(sicNode, SIC_NAME, sicChannel, DriverStrategy.ALL_GROUP_REDUCE);
//注意这里的并行度需要设置为1,因为要将各节点的样本根据权值进行聚合到一起,相当于中心Coordinate的作用
sicNode.setParallelism(1);
sicPlanNode.setParallelism(1);
sicPlanNode.initProperties(new GlobalProperties(), new LocalProperties());
sicPlanNode.setCosts(defaultZeroCosts);
//设置Channel的Target
sicChannel.setTarget(sicPlanNode);
sipPlanNode.addOutgoingChannel(sicChannel);
this.plan.getAllNodes().add(sicPlanNode);
// 3. Use sampled data to build range boundaries.
//RangeBoundaryBuilder实现了RichMapPartitionFunction,用于计算各个分段的界
final RangeBoundaryBuilder rangeBoundaryBuilder = new RangeBoundaryBuilder(comparator, targetParallelism);
final TypeInformation<CommonRangeBoundaries> rbTypeInformation = TypeExtractor.getForClass(CommonRangeBoundaries.class);
final UnaryOperatorInformation rbOperatorInformation = new UnaryOperatorInformation(sourceOutputType, rbTypeInformation);
//MapPartitionOperatorBase是flink-core中的类
final MapPartitionOperatorBase rbOperatorBase = new MapPartitionOperatorBase(rangeBoundaryBuilder, rbOperatorInformation, RB_NAME);
//Map节点,MapPartitionNode是flink-optimizer中dag的类,其中只有DagConnection
final MapPartitionNode rbNode = new MapPartitionNode(rbOperatorBase);
//创建以2.中reduce的节点为Source的Channel
final Channel rbChannel = new Channel(sicPlanNode, TempMode.NONE);
rbChannel.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED);
//创建PlanNode,flink-optimizer中plan中的类
final SingleInputPlanNode rbPlanNode = new SingleInputPlanNode(rbNode, RB_NAME, rbChannel, DriverStrategy.MAP_PARTITION);
rbNode.setParallelism(1);
rbPlanNode.setParallelism(1);
rbPlanNode.initProperties(new GlobalProperties(), new LocalProperties());
rbPlanNode.setCosts(defaultZeroCosts);
rbChannel.setTarget(rbPlanNode);
sicPlanNode.addOutgoingChannel(rbChannel);
this.plan.getAllNodes().add(rbPlanNode);
// 4. Take range boundaries as broadcast input and take the tuple of partition id and record as output.
//AssignRangeIndex实现了RichMapPartitionFunction,利用了boundary来得到每个记录的输出
final AssignRangeIndex assignRangeIndex = new AssignRangeIndex(comparator);
final TypeInformation<Tuple2> ariOutputTypeInformation = new TupleTypeInfo<>(BasicTypeInfo.INT_TYPE_INFO, sourceOutputType);
final UnaryOperatorInformation ariOperatorInformation = new UnaryOperatorInformation(sourceOutputType, ariOutputTypeInformation);
//MapPartitionOperatorBase是flink-core中的类
final MapPartitionOperatorBase ariOperatorBase = new MapPartitionOperatorBase(assignRangeIndex, ariOperatorInformation, ARI_NAME);
//Map节点,MapPartitionNode是flink-optimizer中dag的类,其中只有DagConnection
final MapPartitionNode ariNode = new MapPartitionNode(ariOperatorBase);
//创建以RangePartition的前驱Operator为Source的Channel
final Channel ariChannel = new Channel(sourceNode, TempMode.NONE);
// To avoid deadlock, set the DataExchangeMode of channel between source node and this to Batch.
//为了防止死锁,将Channel的DataExchangeMode设置为Batch
ariChannel.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.BATCH);
//创建PlanNode,flink-optimizer中plan中的类
final SingleInputPlanNode ariPlanNode = new SingleInputPlanNode(ariNode, ARI_NAME, ariChannel, DriverStrategy.MAP_PARTITION);
ariNode.setParallelism(sourceParallelism);
ariPlanNode.setParallelism(sourceParallelism);
ariPlanNode.initProperties(new GlobalProperties(), new LocalProperties());
ariPlanNode.setCosts(defaultZeroCosts);
//将创建的Channel的Target指向新创建的Map Operator
ariChannel.setTarget(ariPlanNode);
this.plan.getAllNodes().add(ariPlanNode);
//将新创建的Channel添加到RangePartition的前一个Operator的sourceNewOutputChannels中
sourceNewOutputChannels.add(ariChannel);
//计算得到的boundaries会被输出到广播通道,rbPlanNode即Channel的sourceNode,为step3创建的map节点,用于计算各个分段的界的
final NamedChannel broadcastChannel = new NamedChannel("RangeBoundaries", rbPlanNode);
broadcastChannel.setShipStrategy(ShipStrategyType.BROADCAST, DataExchangeMode.PIPELINED);
//将Channel的Target指向step4创建的Map Operator,用于得到每个记录属于哪个分区的
broadcastChannel.setTarget(ariPlanNode);
List<NamedChannel> broadcastChannels = new ArrayList<>(1);
broadcastChannels.add(broadcastChannel);
//broadcastChannels的source是计算各个分段界的rbPlanNode,target是根据界将各个记录分离的ariPlanNode
//这里将broadcastChannels添加给ariPlanNode
ariPlanNode.setBroadcastInputs(broadcastChannels);
// 5. Remove the partition id.
//创建Channel,source为将各个记录分离的ariPlanNode
final Channel partChannel = new Channel(ariPlanNode, TempMode.NONE);
final FieldList keys = new FieldList(0);
partChannel.setShipStrategy(ShipStrategyType.PARTITION_CUSTOM, keys, idPartitioner, DataExchangeMode.PIPELINED);
ariPlanNode.addOutgoingChannel(partChannel);
//RemoveRangeIndex继承自MapFunction,从泛型<Tuple2<Integer,T>,T>中可知,其通过将Tuple2<Integer,T>map为T将分区信息进行删除
//因为找到记录的分区之后,分区编号就没有存在的意义了,因此为流中的记录移除分区编号
final RemoveRangeIndex partitionIDRemoveWrapper = new RemoveRangeIndex();
final UnaryOperatorInformation prOperatorInformation = new UnaryOperatorInformation(ariOutputTypeInformation, sourceOutputType);
final MapOperatorBase prOperatorBase = new MapOperatorBase(partitionIDRemoveWrapper, prOperatorInformation, PR_NAME);
//Map节点,MapNode是flink-optimizer中dag的类,其中只有DagConnection信息
final MapNode prRemoverNode = new MapNode(prOperatorBase);
//创建PlanNode,flink-optimizer中plan中的类
final SingleInputPlanNode prPlanNode = new SingleInputPlanNode(prRemoverNode, PR_NAME, partChannel, DriverStrategy.MAP);
//设置Channel的target,target为新创建的Map Operator,该map消除了数据中的分区信息,只保留原始记录
partChannel.setTarget(prPlanNode);
//将新创建的节点并行度设置为RangePartition节点的后继节点的并行度
prRemoverNode.setParallelism(targetParallelism);
prPlanNode.setParallelism(targetParallelism);
GlobalProperties globalProperties = new GlobalProperties();
globalProperties.setRangePartitioned(new Ordering(0, null, Order.ASCENDING));
prPlanNode.initProperties(globalProperties, new LocalProperties());
prPlanNode.setCosts(defaultZeroCosts);
this.plan.getAllNodes().add(prPlanNode);
// 6. Connect to target node.
//将原来的RangePartition算子的输入Channel的source设置为prPlanNode
channel.setSource(prPlanNode);
channel.setShipStrategy(ShipStrategyType.FORWARD, DataExchangeMode.PIPELINED);
prPlanNode.addOutgoingChannel(channel);
return sourceNewOutputChannels;
}
经过以上步骤,则将OptimizedPlan进行了改写,从而完成了分区的“重写”。上述代码可以结合下图来看(可以放大图片看):
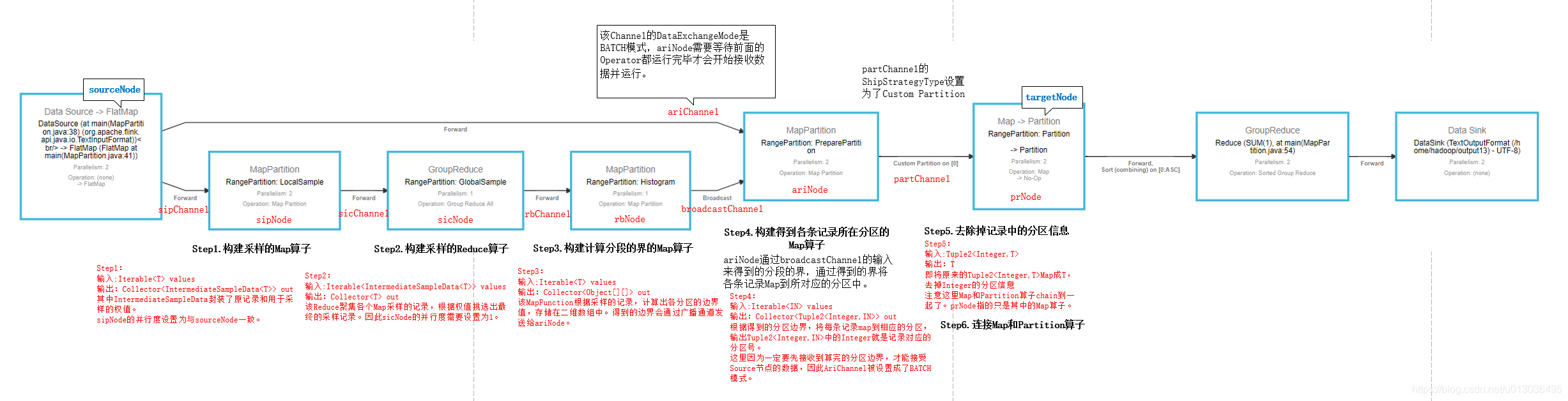
对具体的采样算法感兴趣,可以参考:
https://blog.csdn.net/yanghua_kobe/article/details/69603795
https://blog.csdn.net/yanghua_kobe/article/details/69358347