前言:仅用于学习交流,配置文件可能和工作中有写差别。本次实验用到的软件有:
- hadoop-2.6.0.tar.gz
- jdk-8u161-linux-x64.tar.gz
- zookeeper-3.4.5.tar.gz
搭建前提:已完成hadoop完全分布式所需的所有操作。
计划:
一主三从的完全分布式hadoop集群,节点名称:master、slave、slave2、slave3
选择master节点和slave3节点为Namenode节点
一、搭建HA模式,修改相关配置文件
1. 创建存放HA的文件夹,修改相关配置
(1) 创建存放高可用的hadoop文件Ha
[root@master ~]# mkdir /usr/local/Ha
(2)复制完全分布式hadoop到Ha文件中
[root@master ~]# cp -r /usr/local/hadoop/hadoop-2.6.0/* /usr/local/Ha/
说明:-r的意思是递归复制,将目录下的所有文件包含子目录一起处理
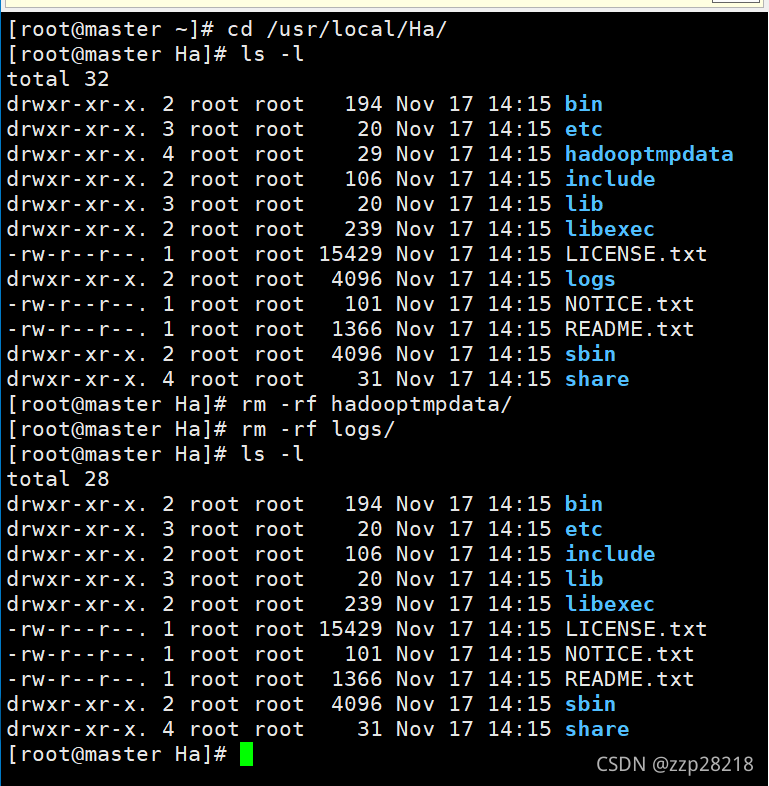
(3)删除Ha文件中的存放集群数据和日志的文件hadoopdata和logs文件夹
[root@master ~]# cd /usr/local/Ha/
[root@master Ha]# ls -l
[root@master Ha]# rm -rf hadooptmpdata/
[root@master Ha]# rm -rf logs/
[root@master Ha]# ls -l
2. 修改配置文件
(1)修改配置文件core-site.xml
[root@master Ha]# cd etc/hadoop/
[root@master hadoop]# vim core-site.xml
原文件里面配置hadoop完全分布式的配置项: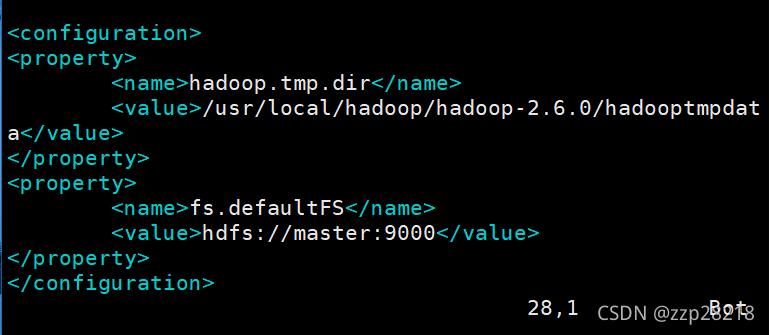
修改文件中的配置项、添加配置项,文件如下所示:
<configuration>
<!--设置存放hadoop运行时产生数据的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Ha/hadoopHAdata</value>
</property>
<!--指定hdfs中namenode的地址-->
<!--mycluster是一个集群的名称,是由两个NameNode的地址组成,可以自定义,但是后面有出先mycluster的地方,要和这里的名字保持一致-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--设置一下故障转移需要的zookeeper集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
效果如下: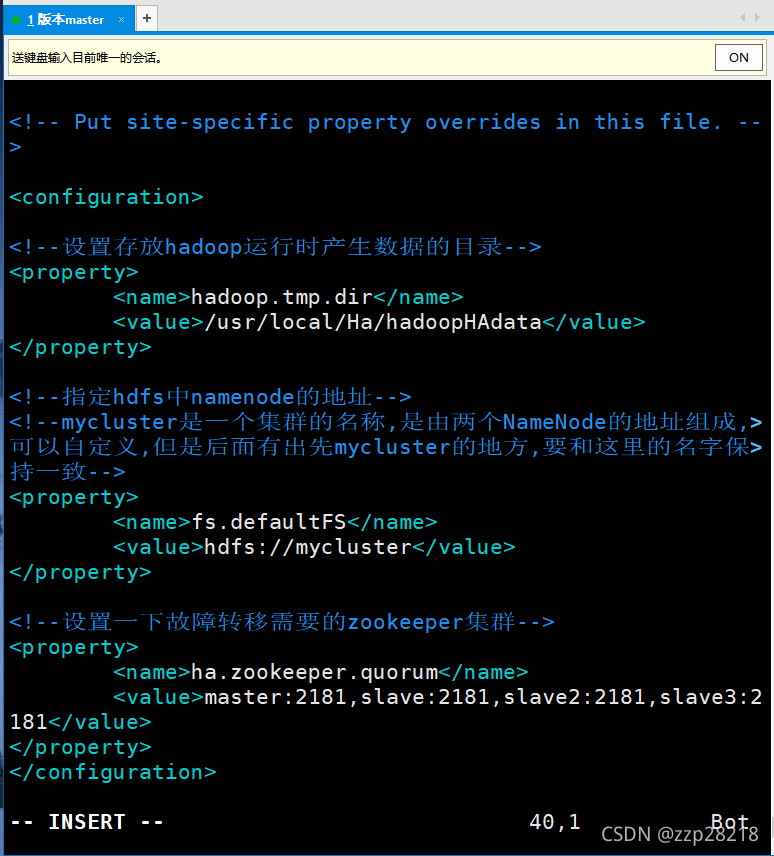
保存退出。
(2)修改配置文件hdfs-site.xml
删除原有的配置,添加以下配置:
<configuration>
<!--完全分布式集群名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--集群中NameNode节点有那些-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:9000</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave3:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:50070</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave3:50070</value>
</property>
<!--指定NameNode元数据在JournalNode上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave:8485;slave2:8485;slave3:8485/mycluster</value>
</property>
<!--设置隔离机制,即同一时刻只能有同一台服务器对外响应-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时需要ssh无密钥登陆,这里是私钥不是公钥-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/Ha/hadoopHAdata/jn</value>
</property>
<!--启动自动故障切换 ,一定要加上-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<!--关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!--访问代理类:client,mycluster,active配置自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enable</name>
<value>true</value>
</property>
</configuration>
其中注意隔离机制时需要ssh无密钥登陆的配置项,好多博客都说这个配置项是用的公钥,这里应该是私钥,看了好几个博客,他们的名字都打错了,id_rsa.pub是公钥,id_rsa是私钥;还有就是一定要添加启动自动故障切换的配置项,要不然后面在nn1节点上初始化HA在zookeepe中的状态时会出错。
效果如下: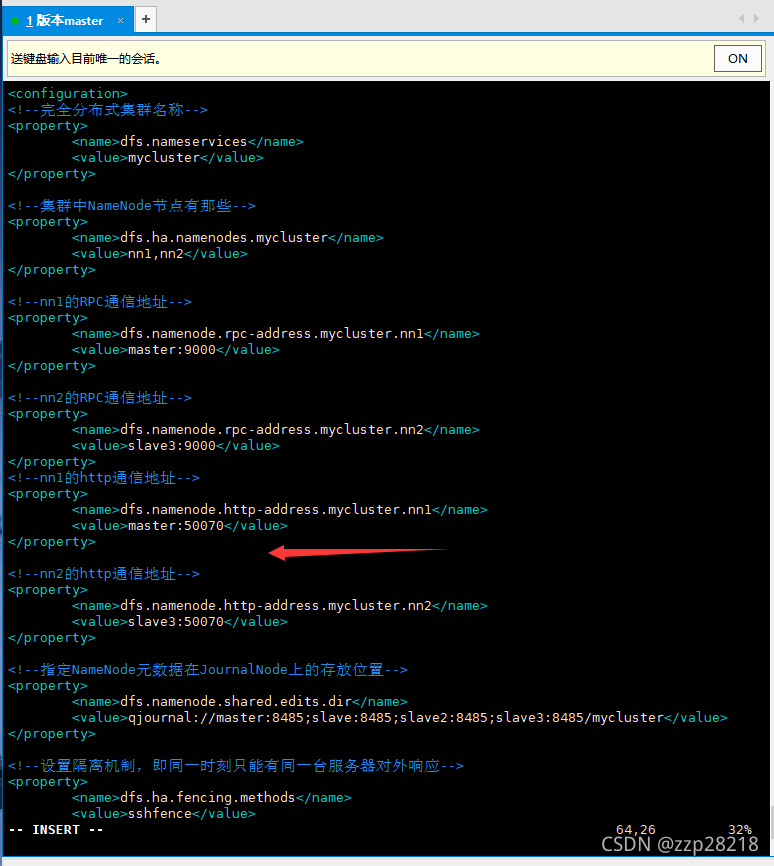
保存退出。
(3)修改配置文件yarn-site.xml
删除全部配置,添加以下配置:
<configuration>
<!--mapreduce获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave3</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave:2181,slave2:2181,slave3:2181</value>
</property>
<!--启动自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
效果如下: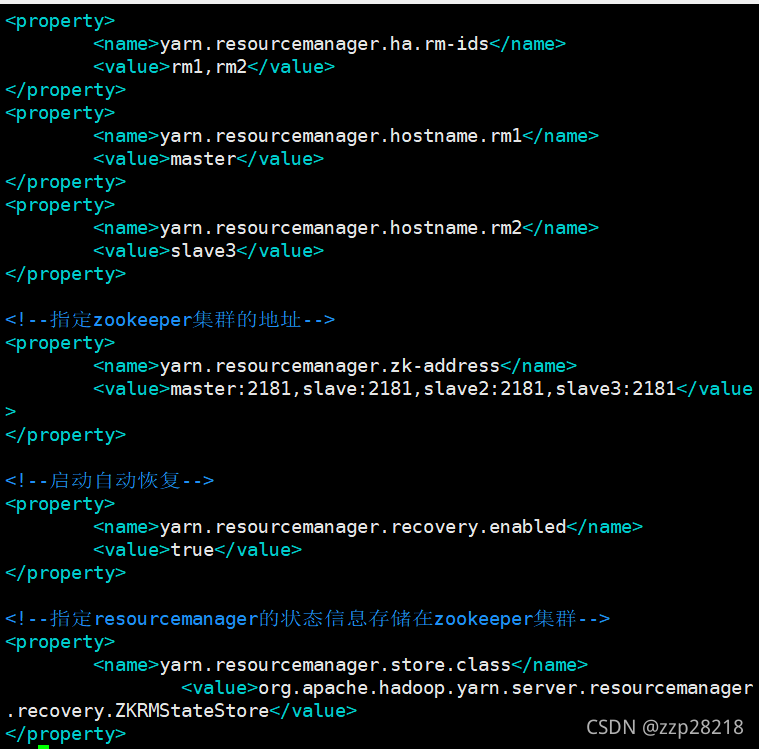
保存退出。
(4)修改配置文件slaves
在此文件中添加:master
添加master的原因:slaves文件指明哪些节点运行DateNode进程。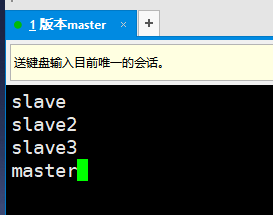
(5)将Ha文件分发给子节点,并放在/usr/local目录下
[root@master ~]# scp -r /usr/local/Ha root@slave:/usr/local/
[root@master ~]# scp -r /usr/local/Ha root@slave2:/usr/local/
[root@master ~]# scp -r /usr/local/Ha root@slave3:/usr/local/
二、开启集群、各个进程
(1)查看java进程,如果完全分布式hadoop进程没有关闭,则需要关闭。
[root@master ~]# /usr/local/hadoop/hadoop-2.6.0/sbin/stop-all.sh
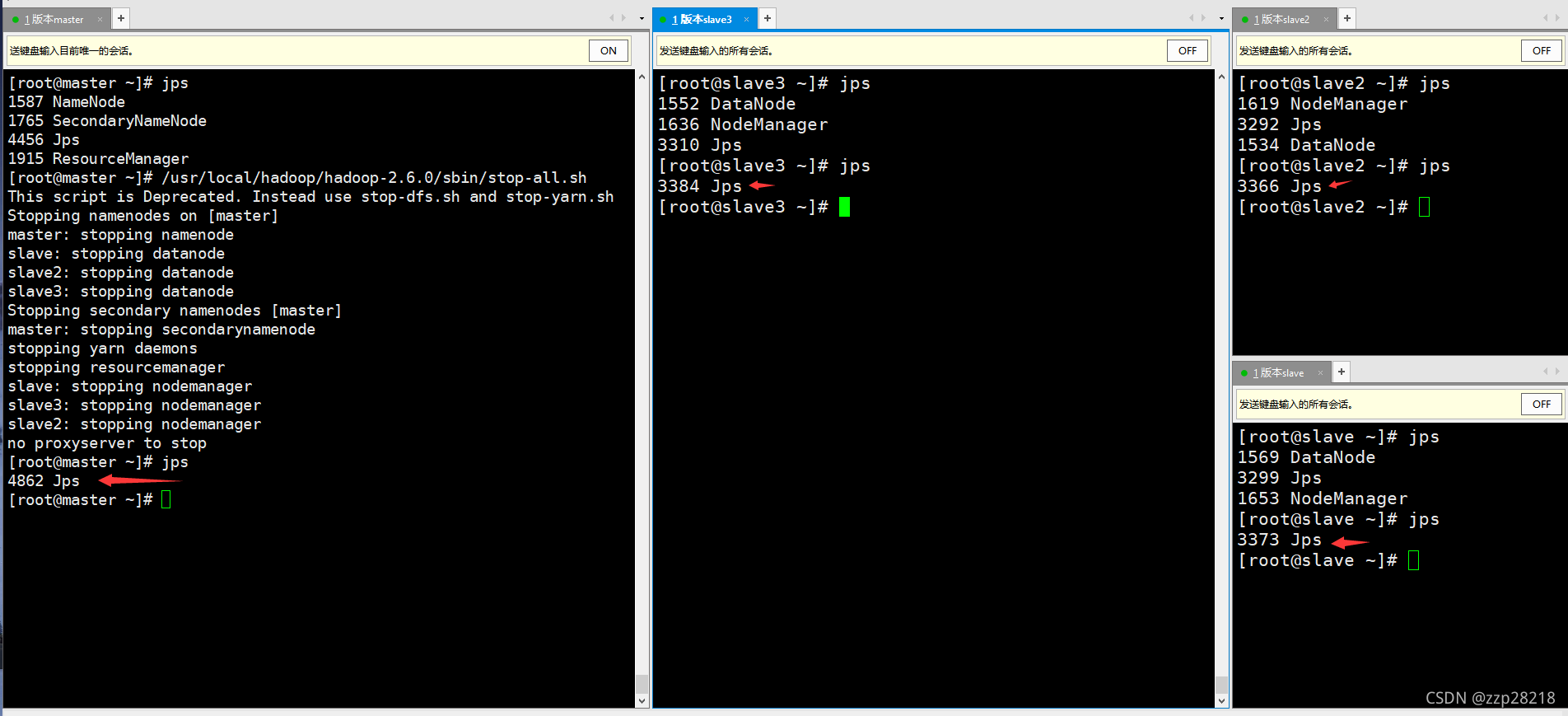
(2)准备工作:开启zookeeper服务并查看服务进程
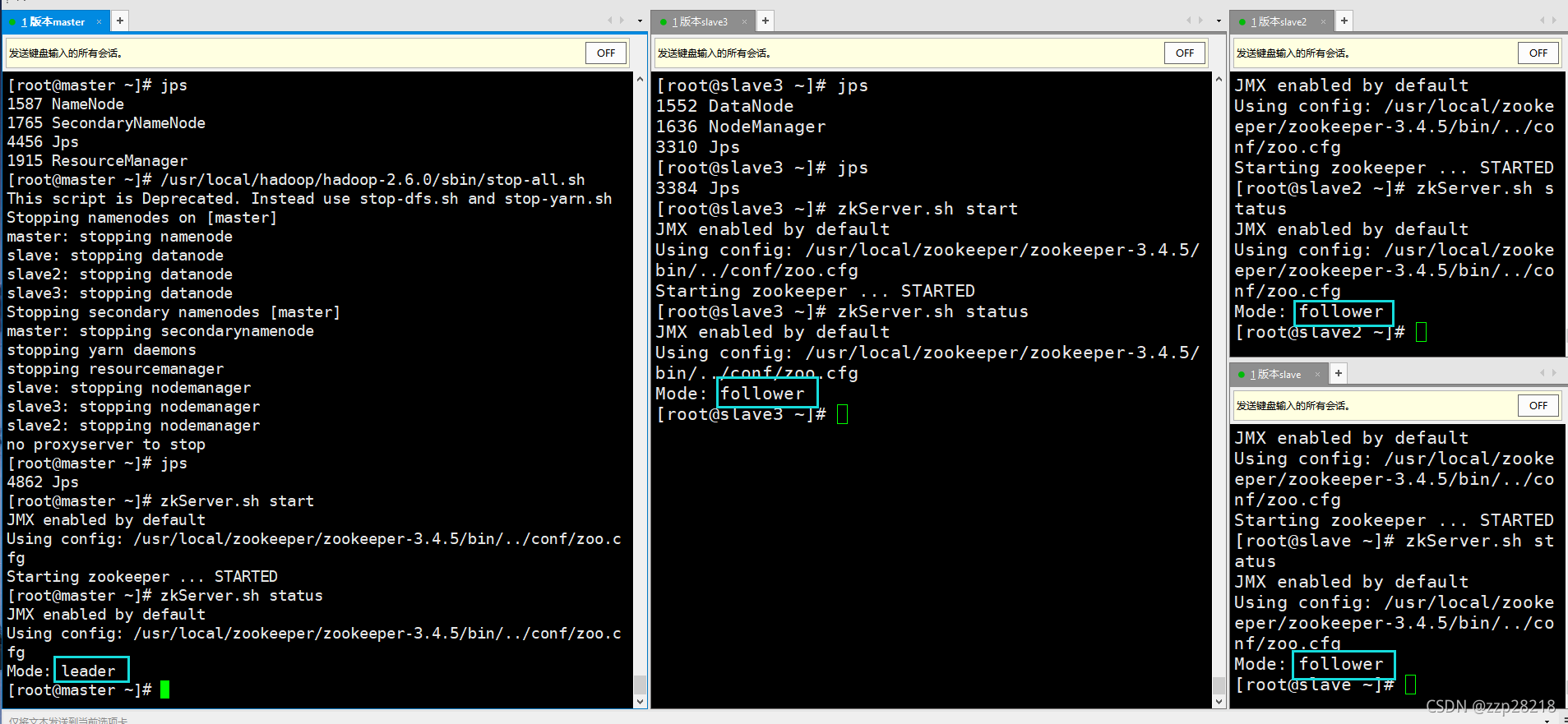
(3)启动各个进程
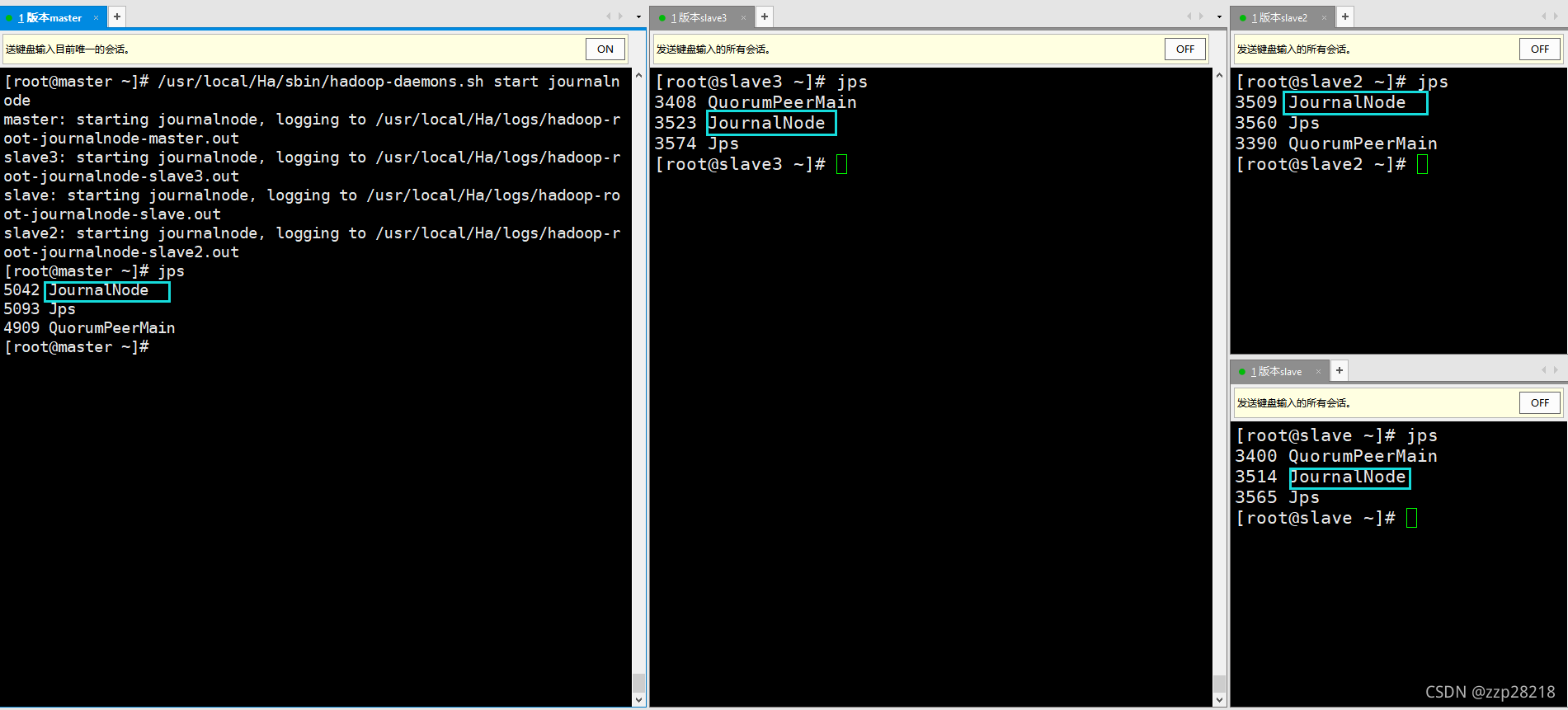
① 每个节点上,启动journalnode服务:
可以在每个节点运行命令:/usr/local/Ha/sbin/hadoop-daemon.sh start journalnode
也可以在master节点上运行:也可以是:/usr/local/Ha/sbin/hadoop-daemons.sh start journalnode
两者的区别在与:hadoop-daemons.sh可以启动给所有节点的journalnode服务
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start journalnode
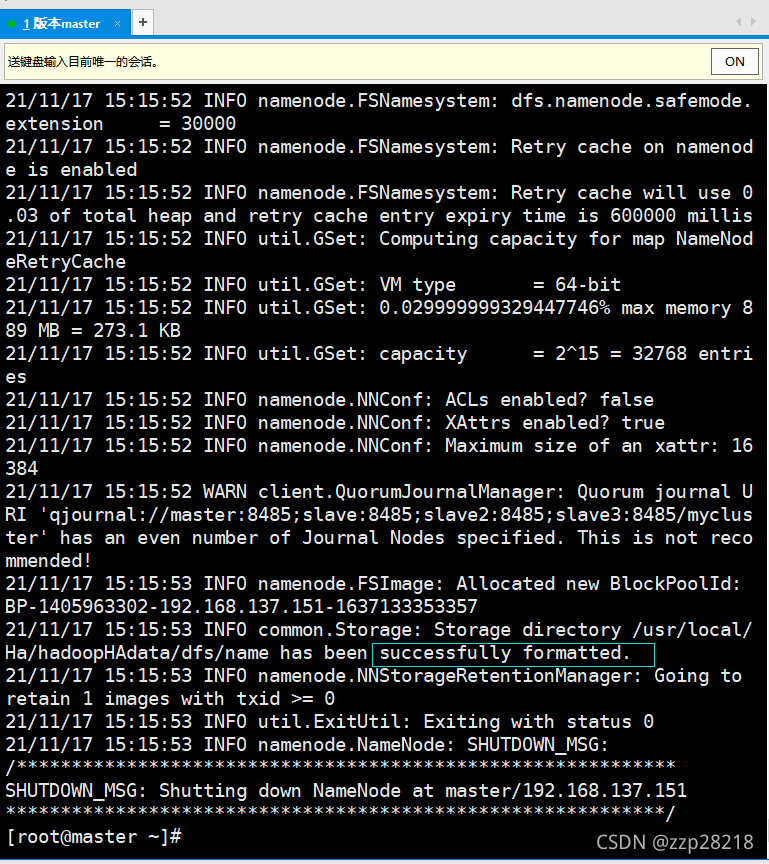
② 在master(nn1)节点上格式化hdfs文件系统
[root@master ~]# /usr/local/Ha/bin/hdfs namenode -format
出现以下内容说明成功:
INFO common.Storage: Storage directory /usr/local/Ha/hadoopHAdata/dfs/name has beensuccessfully formatted.
③ 在master(nn1)节点上初始化HA在Zookeeper中状态:
[root@master ~]# /usr/local/Ha/bin/hdfs zkfc -formatZK
出现下图所示信息表示成功: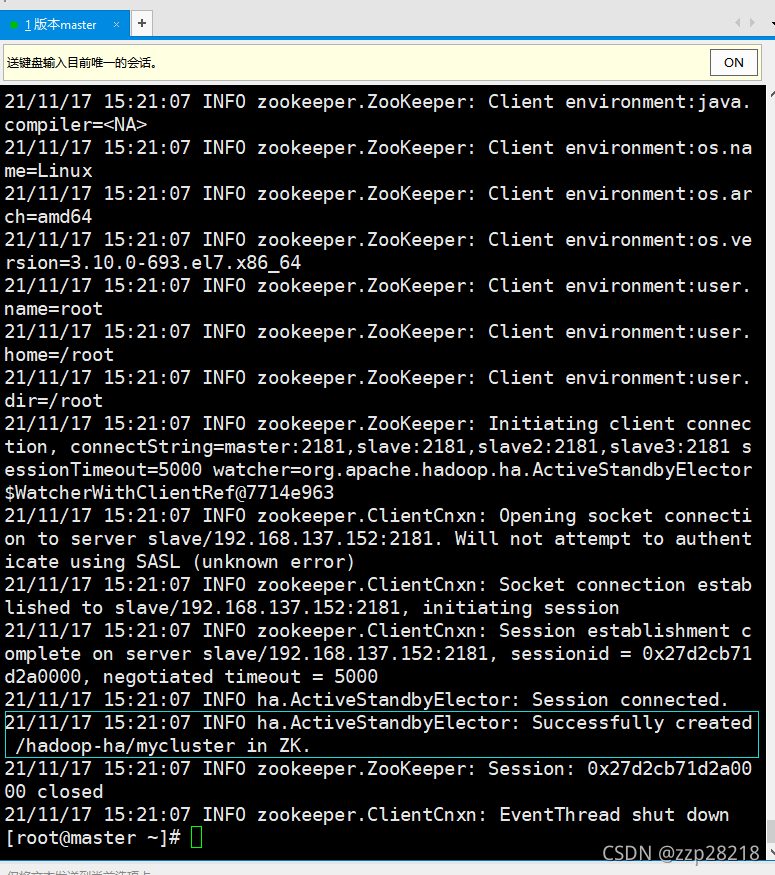
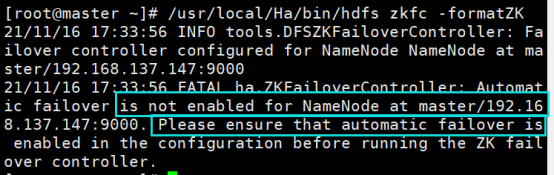
如果出现下图这种错误,就在各个节点的hdfs-site.xml文件中添加如下配置:
<!--启动自动故障切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
④ 在master(nn1)节点上启动namenode:
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemon.sh start namenode
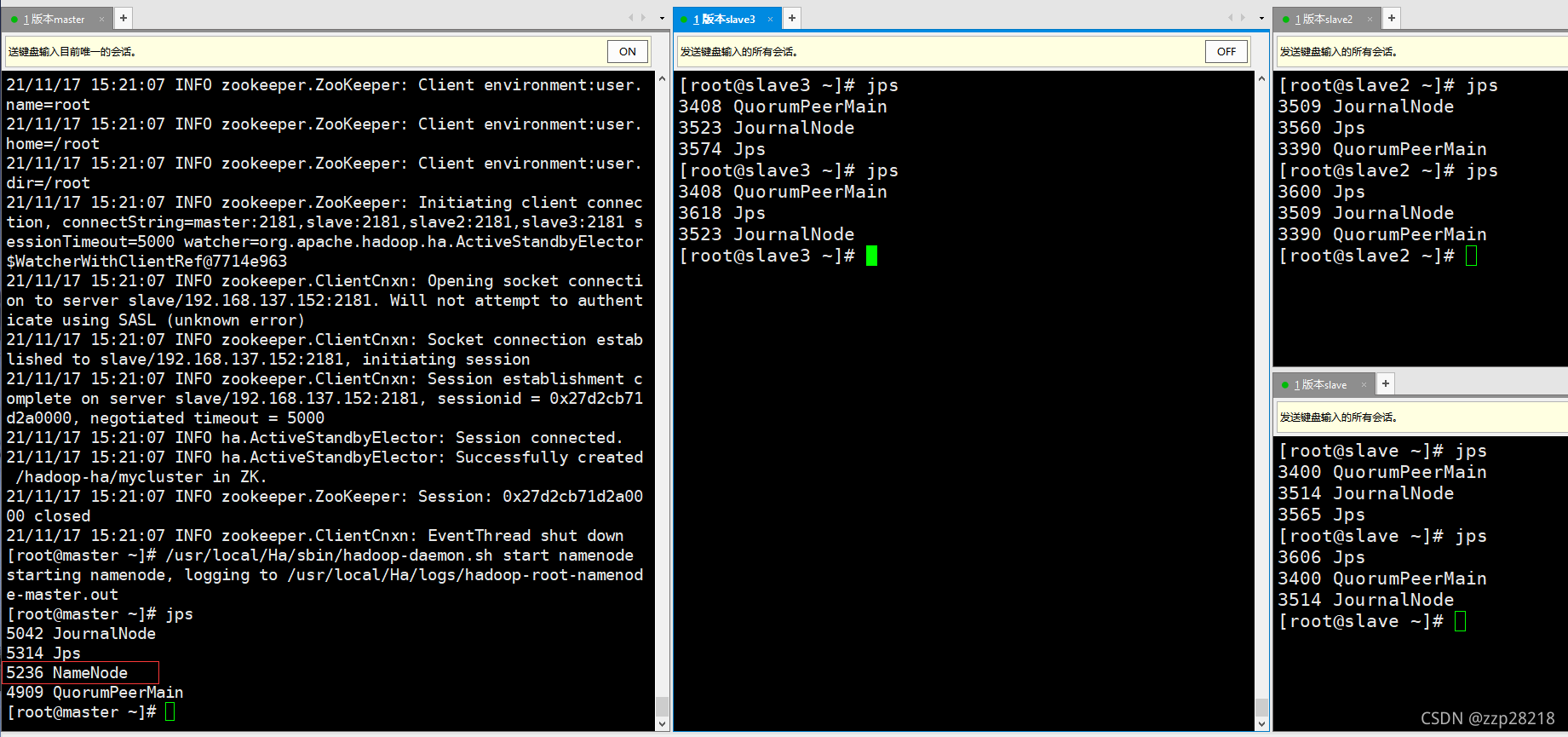
就只有master节点有NameNode进程,其他节点是没有的。
⑤ 在slave3(nn2)节点上同步master(nn1)节点的元数据信息:
[root@slave3 ~]# /usr/local/Ha/bin/hdfs namenode -bootstrapStandby
出现下图显示状态为0则为成功!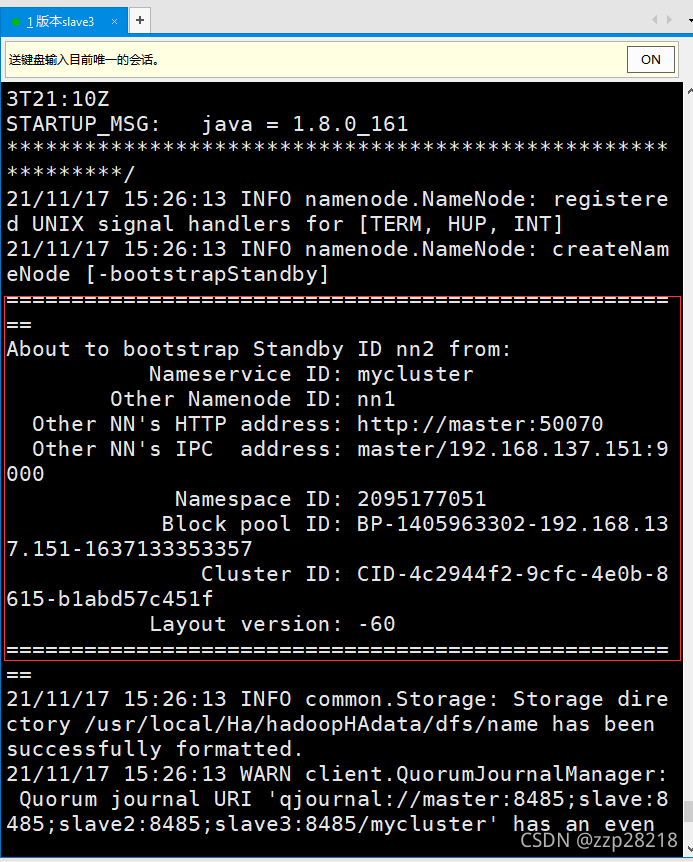
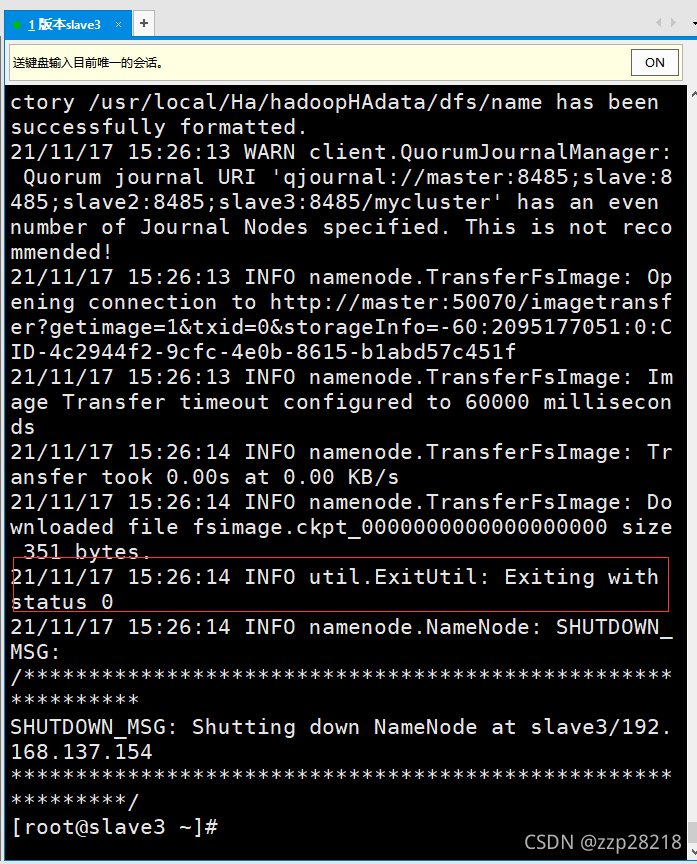
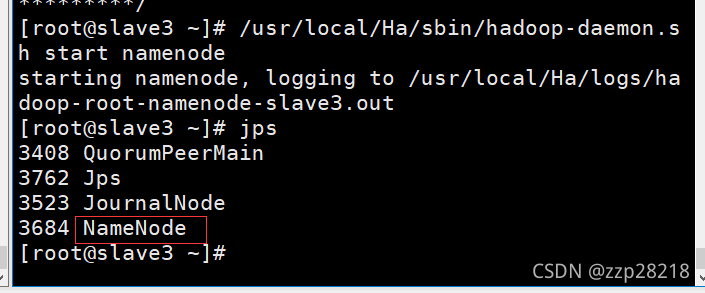
⑥ 在slave3(nn2)上开启namenode服务
[root@slave3 ~]# /usr/local/Ha/sbin/hadoop-daemon.sh start namenode
⑦ 在master节点启动各个节点的DataNode进程,或者一个节点一个节点启动
一个节点一个节点的启动:
/usr/local/Ha/sbin/hadoop-daemon.sh start datanode
在master节点启动所有节点的DataNode:
/usr/local/Ha/sbin/hadoop-daemons.sh start datanode
这里选择在master节点启动所有节点的DataNode进程:
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start datanode
jps查看各个节点进程: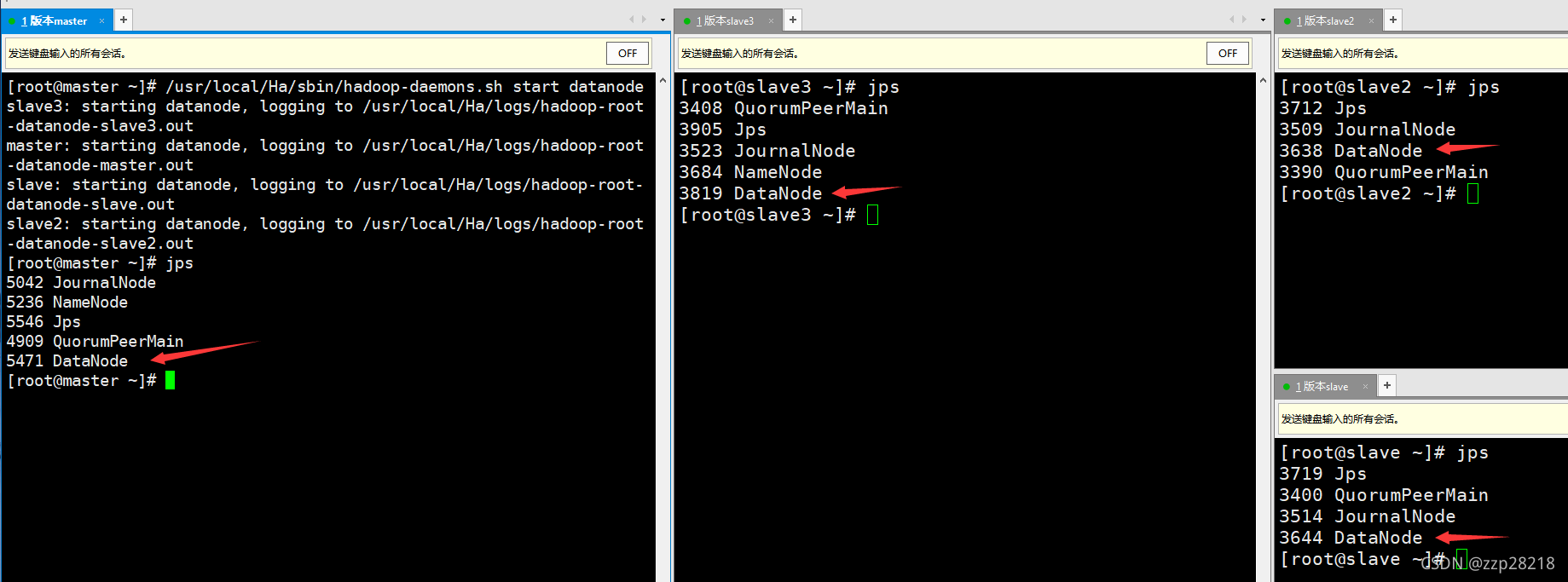
⑧ 在其中一个NameNode(master或slave3)节点上启动DFSZK Failover Controller,那个机器上启动,那个机器的NameNode状态就是Active NameNode。
[root@master ~]# /usr/local/Ha/sbin/hadoop-daemons.sh start zkfc
jps查看进程,发现只有NameNode节点有DFSZKFailoverController进程,其他的节点没有。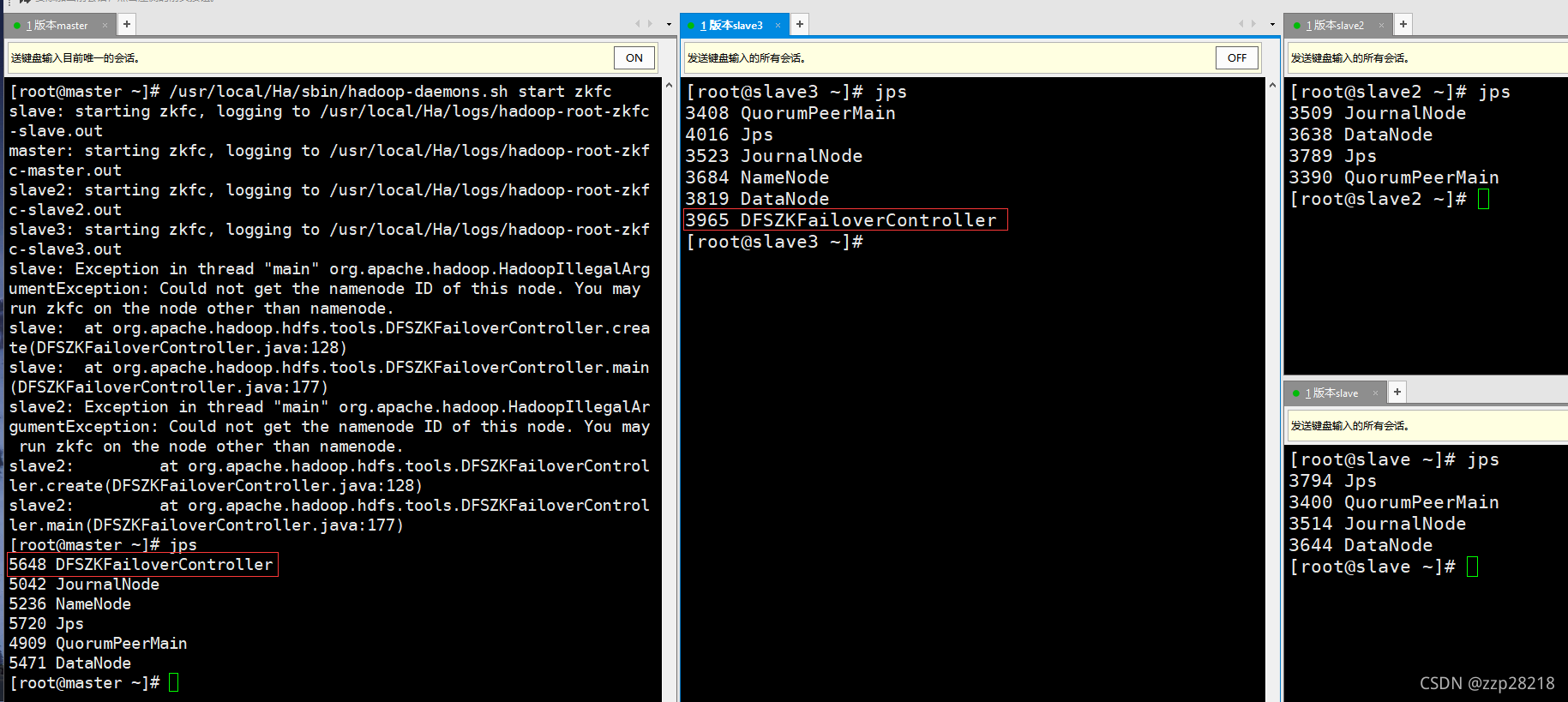
出现以下信息的意思可能你的配置文件中的涉及到zookeeper方面的配置中,端口配置错了,或者是由于其他节点不是NameNode节点,所以他会查找不到。
属于第一种情况的,两个NameNode节点中只会有一个DFSZKFailoverController进程。
属于第二种情况的在端口没有配置错的情况下属于正常。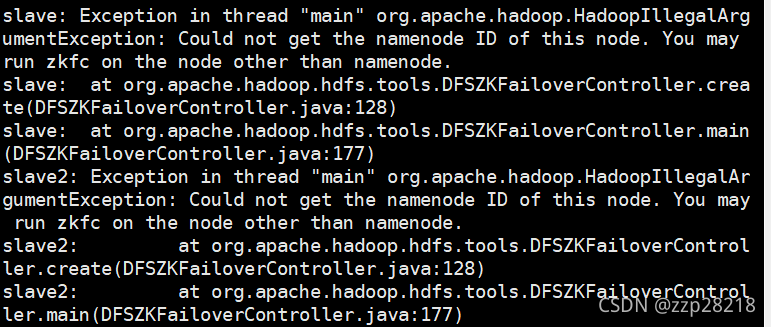
⑨ 查看NameNode状态
- 通过浏览器查看NameNode节点(master、slave3)的状态
访问:master:50070和slave3:50070,可以看到由于我是在master节点启动的zkfc,所以master节点的NameNode状态为active,slave3为standby。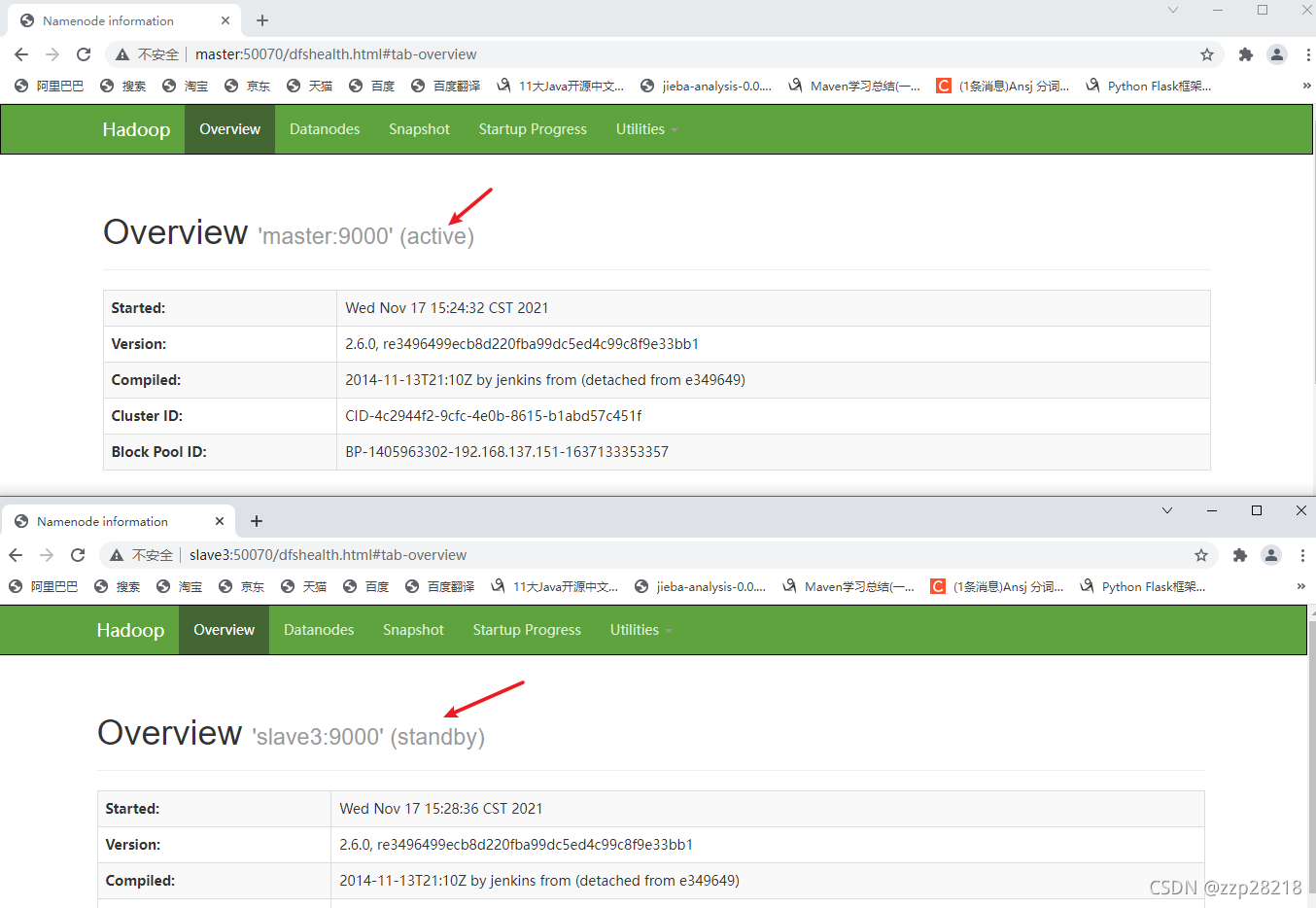
- 通过命令查看状态:
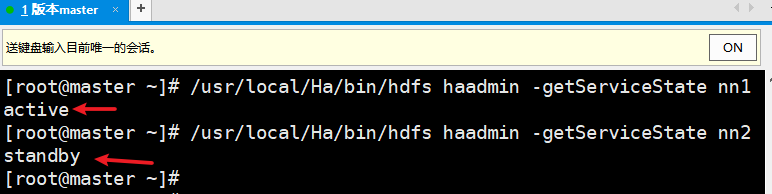
master节点上:
[root@master ~]# /usr/local/Ha/bin/hdfs haadmin -getServiceState nn1
[root@master ~]# /usr/local/Ha/bin/hdfs haadmin -getServiceState nn2
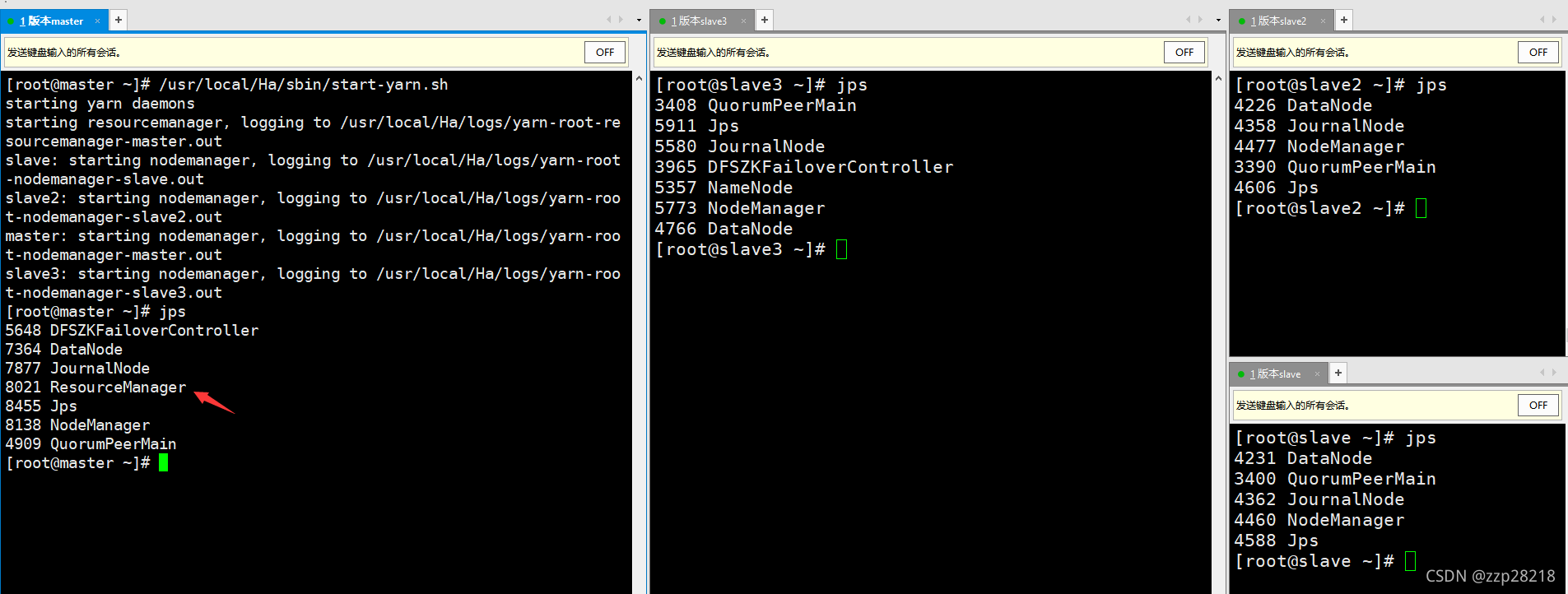
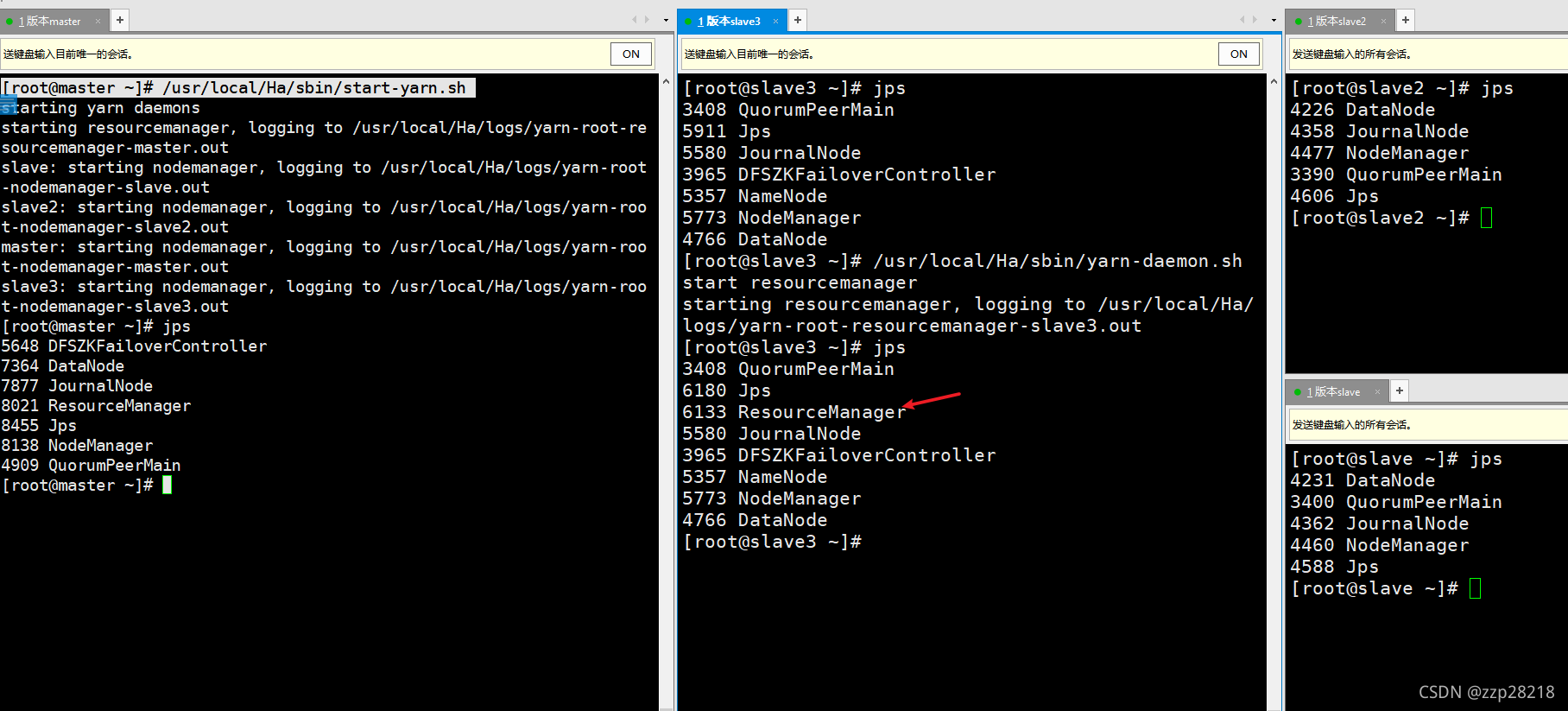
⑩ 启动Yarn、终止NameNode节点为active的NameNode进程、关闭所有进程
- 启动Yarn
master节点: /usr/local/Ha/sbin/start-yarn.sh
slave3节点:/usr/local/Ha/sbin/yarn-daemon.sh start resourcemanager
查看服务状态:
[root@master ~]# /usr/local/Ha/bin/yarn rmadmin -getServiceState rm1
[root@master ~]# /usr/local/Ha/bin/yarn rmadmin -getServiceState rm2

- 终止NameNode节点为active的NameNode进程
原来状态: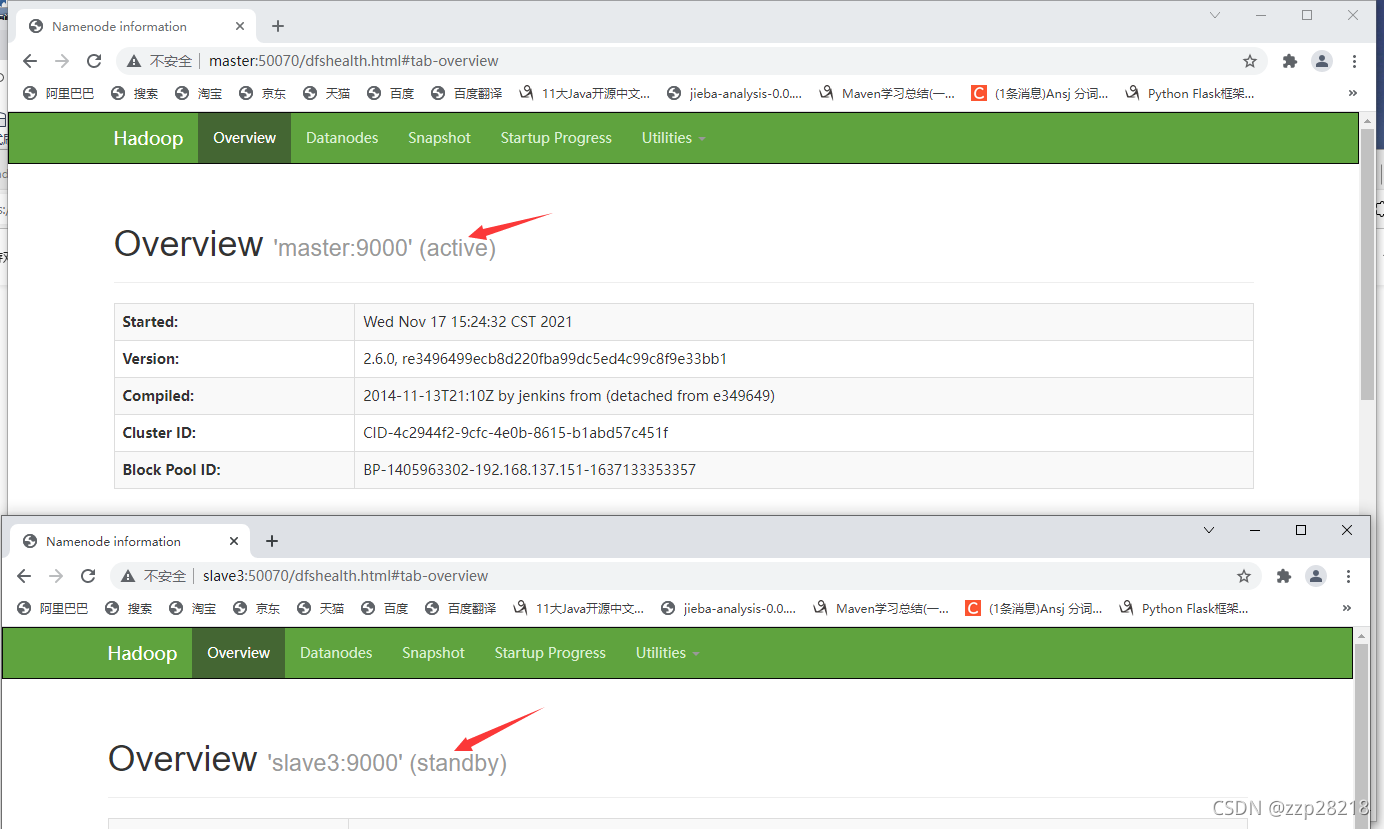
在active状态的NameNode对应的节点去执行以下命令(我这里是master节点):
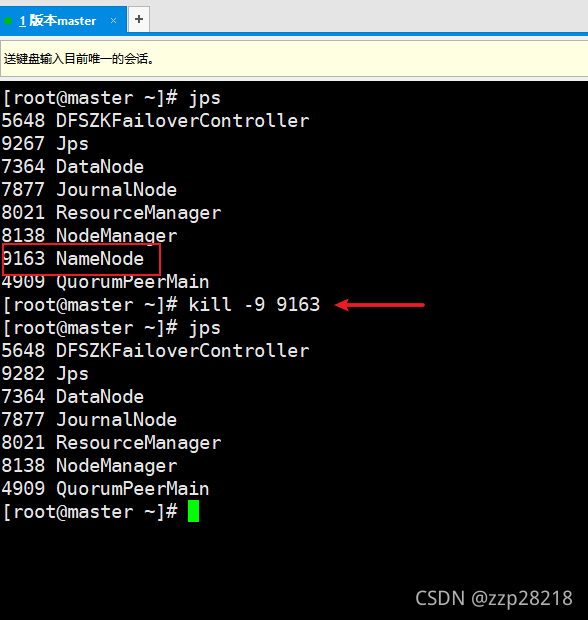
[root@master ~]# jps
[root@master ~]# kill -9 9163
[root@master ~]# jps
刷新网页: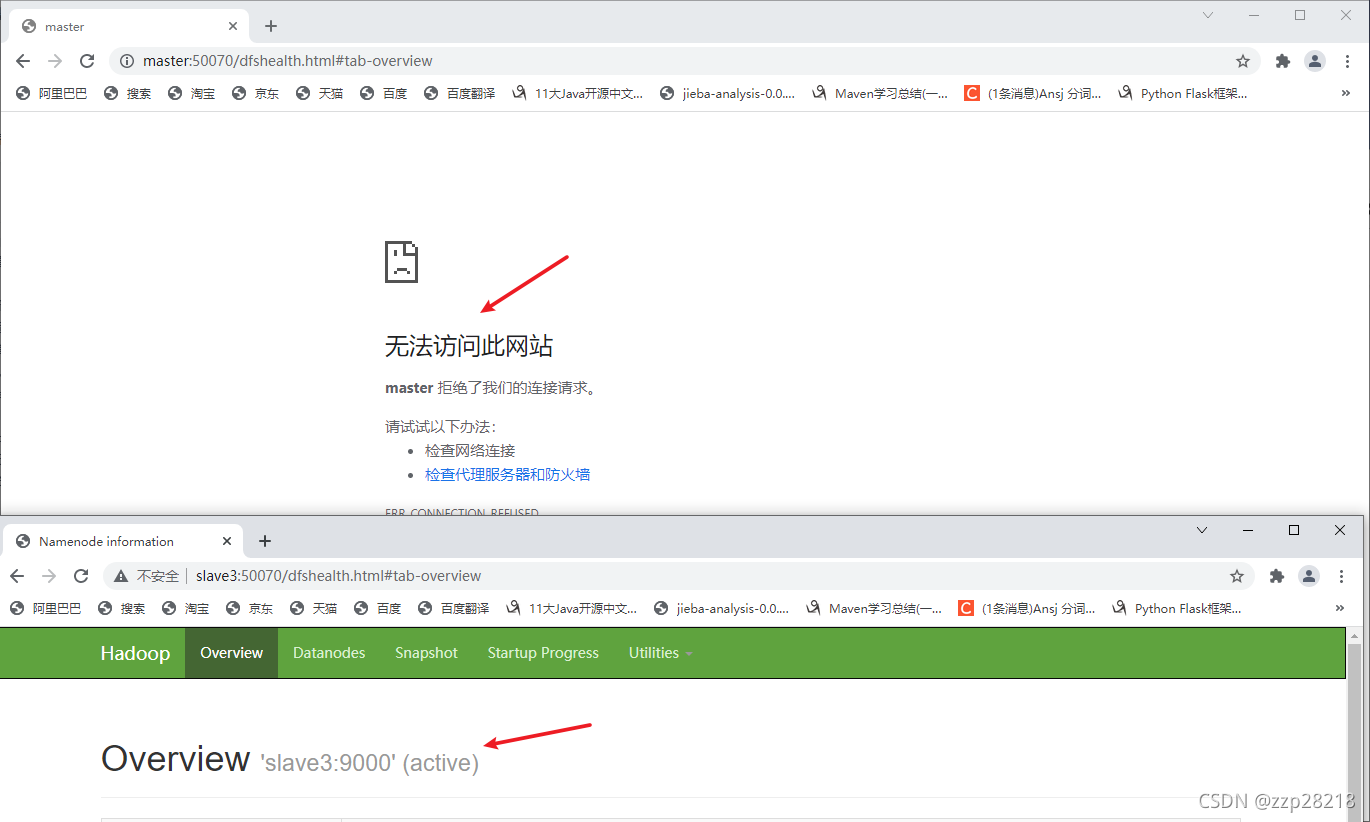
发现slave3的NameNode节点状态变为:active,master节点死机。说明高可用hadoop搭建成功!
- 关闭所有进程:
master节点上:
[root@master ~]# /usr/local/Ha/sbin/stop-dfs.sh
[root@master ~]# /usr/local/Ha/sbin/stop-yarn.sh
[root@master ~]# zkServer.sh stop
(4) 启动HA集群
[root@master ~]# /usr/local/Ha/sbin/start-all.sh
三、提示错误解决
(1)提示没有开启自动故障切换
解决方法:在配置文件hdfs-site.xml中添加如下配置项:
<!--启动自动故障切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
(2)slave: Exception in thread “main” org.apache.hadoop.HadoopIllegalArgumentException: Could not get the namenode ID of this node. You may run zkfc on the node other than namenode.slave:atorg.apache.hadoop.hdfs.tools.DFSZKFailoverController.create(DFSZKFailoverController.java:128)
正常情况下:出现以下信息的意思是由于其他节点不是NameNode节点,所以他会查找不到。
出问题的时候:出现以下信息的意思可能你的配置文件中的涉及到zookeeper方面的配置项中,端口配置有误。
属于第一种情况的,两个NameNode节点中只会有一个DFSZKFailoverController进程。
属于第二种情况的在端口没有配置错误的情况下属于正常。
如果觉得作者的这篇文章对你有帮助,可以点点赞关注一下哦~。谢谢你的支持!