ABSTRACT
哈希在促进大规模多媒体应用方面已显示出其效率和有效性。与数据相关的监督知识(如语义标签或成对关系)可以显著提高哈希编码和哈希函数的质量。然而,面对网络上新兴概念和多媒体数据的快速增长,现有的监督哈希方法受限于人工标注的高昂成本,很容易受到监督信息的稀缺性和有效性的影响。本文提出了一种新的哈希方法,zero-shot hashing (ZSH),它利用有限的训练样本来学习哈希函数,并对未知类别的图像进行哈希编码。具体来说,我们将独立标签( 0/1形式的标签向量)投影到词向量空间中,在该空间中,所有标签之间的语义关系可以被精确地描述,从而将已知类别的监督知识迁移到未知类别中。此外,为了解决语义偏移问题,我们对词向量空间进行旋转,将语义空间与低层视觉特征空间对齐,从而减轻了语义鸿沟的影响。
Keywords: zero-shot hashing; discrete hashing; supervised knowledge transfer; semantic alignment
INTRODUCTION
哈希是一种能够有效实现大规模多媒体数据检索的索引技术。为了实现更短的检索时间和更少的计算开销,哈希技术将高维数据映射成紧凑的二进制编码。通过哈希编码,可以降低数据的存储开销,而且汉明距离可以通过CPU的异或操作来高效计算。由于哈希能够缓解“维度灾难”问题,哈希在现实场景中也得到了广泛的应用,包括多媒体检索和多媒体事件检测等。
哈希技术可以分成数据独立和数据依赖两类。对于数据独立,比如说局部敏感哈希(LSH),没有数据的先验知识(监督信息),而且哈希函数也是随机生成的。为了获得较高的准确率,需要较长的哈希编码(通常超过1000bits),但存储和计算开销问题也随之而来。为了解决这个问题,研究转向数据依赖的方法,它能利用数据本身的内部信息。数据依赖的方法可以分为有监督哈希(e.g., Supervised Hashing with Kernels, Weakly-supervised Hashing and Supervised Discrete Hashing)和无监督哈希(e.g., Iterative Quantization, Order Preserving Hashing and Robust Discrete Spectral Hashing)。通常来说,有监督哈希比无监督哈希的效果更好,因为监督信息(e.g., semanticlabels and pair-wise data relationship)有助于挖掘数据的内在性质,从而生成更好的哈希编码和哈希函数。
随着网络数据的爆炸式增长,传统的监督哈希方法面临巨大的挑战,新兴语义概念和多媒体数据增长迅猛,而监督知识( supervised knowledge)不能得到及时更新(高昂的人工标注成本)。如图1所示,对于已知类别的样本,现有的监督哈希方法可以达到令人满意的效果,因为有可靠的监督信息指导学习过程,但是这些方法不能泛化到未知类别(训练数据中不包含的类别)。例如“segway”。此外,大多数现有方法以 0/1 semantic labels or pair-wise data relationship的形式利用监督信息,导致类别之间的语义关系被忽视。这种语义独立( semantic independency)的缺点之一是每个类别既不能从其他语义相关类别中学习到也不能将它的监督信息分配给其他类别。

上述缺点启发我们,是否可以先通过已知类别学习哈希函数,在面对未知类别时,利用已经学习到的哈希函数进行哈希编码。该目标的关键挑战是如何构建已知类别与未知类别的关联,来迁移监督信息。 zero-shot learning (ZSL)被广泛用于解决此问题。ZSL的目标是学习从特征空间到高层语义空间的映射关系,从而避免对新类别进行标注并重新训练模型。ZSL通常通过类-属性描述子(class-attribute descriptors)来构建低层视觉特征和高层语义空间的语义联系,从而只使用属性和类别之间的关系就可以学习到新类别。然而,现存的基于属性的ZSL方法有以下局限:(1)人工标注的属性信息存在不准确和不完整问题;(2)当面对跨域(domain shift)问题时,预定义的属性的区分能力降低。
近年来,辅助数据集被证明有助于帮助零样本学习问题。例如,利用Wikipedia,可以得到单词的分布式表示(distributional representation of word embedding),能够使得相似的单词在语义空间上的距离更近。在学习过程中,视觉信息可以被词向量描述,这些知识可以被迁移到模型中。所以许多方法利用辅助模态(跨模态)来解决ZSL问题。
如前所述,随着新型概念和多媒体数据的迅速增长,我们急需一种能够对未知类别图像进行哈希编码的可靠且灵活的哈希函数。然而,在哈希领域,ZSL问题很少被研究。我们提出一种新颖的哈希方案,零样本哈希(zero-shot hashing ,ZSH)。由于word embedding能够很好地捕获语义关系,我们将one-hot的标签映射到语义空间,从而已知类别和未知类别能够共享监督信息。这种方法使得可以不借助任何视觉信息就能编码未知类别的图像。此外,即使我们不能精确地检索到该类别,也能检索到语义相近的类别图像。而且我们认识到直接利用词向量会导致语义偏移(semantic shift)问题。所以旋转词向量空间(rotate embedded space)来提升哈希函数对未知类别的泛化能力。为了更进一步提升哈希函数的效果,我们保留了数据的局部结构性质(保持相似性)和二进制哈希编码的离散性质。
CONTRIBUTIONS
1、解决了利用有限的已知类别的训练数据来学习可靠的哈希函数,用于对未知类别的图像进行哈希编码的问题。提出了一种新颖的zero-shot hashing方案,通过 semantic embedding space将原本独立的标签联系起来。这是首次提出利用有限的监督知识,对新兴概念进行哈希编码的问题。
2、提出一种将监督知识从已知类别迁移到未知类别的策略。具体地,我们将标签投影到词向量空间,这样标签之间的语义关系可以量化地计算。通过这种方式,未知类别标签可以用它相近的已知类别来表示。例如,“ segway”可以用“bicycle”和“automobile”来学习得到。
3、由于初始的语义向量是来自现成(纯粹基于语料库)的词向量空间,可能会带来类别与视觉特征之间的语义偏移( semantic shift)问题。为了缓解这一问题,我们提出旋转词向量空间(rotate embedded space)来更好地匹配底层特征,从而缓解语义鸿沟现象。
4、为了生成更可靠的哈希函数,我们提出利用数据的潜在性质来提升 intermediate binary codes(哈希编码的近似解)。具体地,在学习过程中,对哈希编码增加离散约束,并且保持了数据局部结构(如果两个图像在原始空间中相近,那么它们在汉明空间也应该相近)。
ZERO-SHOT HASHING
Problem Definition
假设给定n张训练图像X,对应的标签矩阵为Y,其中包含C个类别。传统的监督哈希方法认为测试数据也是来自这C个类别的。而零样本哈希中测试数据类别和训练数据类别没有交集。我们希望仅仅通过训练数据X,学习哈希函数f,不仅能够保证对于语义相近物体的哈希编码的汉明距离较短,而且对于未知类别的测试数据有较好的泛化能力。
Overall Framework
框架如图2所示,可以分成离线阶段和在线阶段。在离线阶段,我们首先通过CNN提取训练图像的视觉特征,同时利用NLP模型将已知类别标签映射到语义向量空间,从而能够捕获已知类别和未知类别之间的联系。在监督学习哈希函数的过程中,ZSH不再使用0/1形式的标签向量,而是利用语义空间中的实值向量,来迁移监督知识。进一步地,我们旋转词向量空间来更好地对齐底层视觉特征空间。同时,为了提升哈希函数,ZSH保持了哈希编码的局部结构信息和离散性质。最后,我们利用学习到的哈希函数对数据库中所有图像进行哈希编码,以供后续检索。在线阶段,每得到一张新的查询图像,我们将它通过学习到的映射进行哈希编码,然后检索返回与它汉明距离接近的图像。
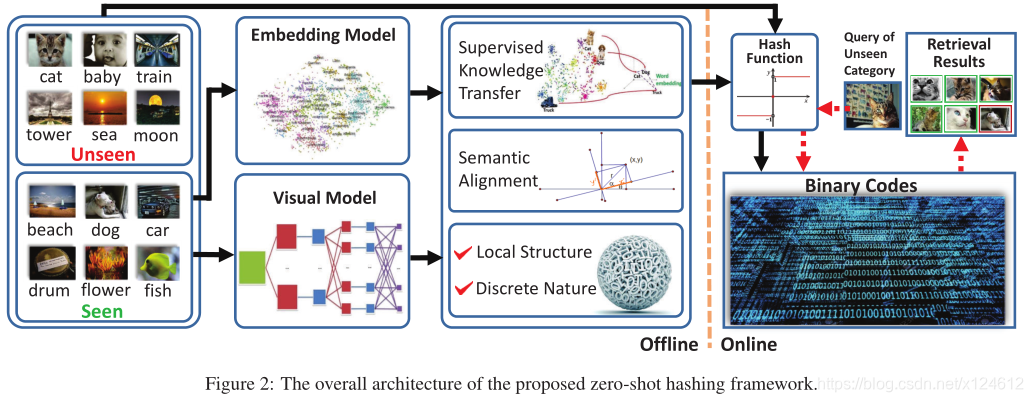
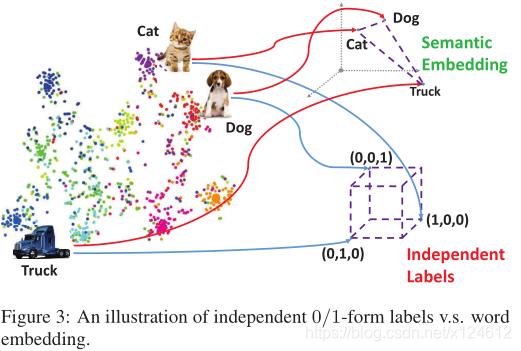
Transferring Supervised Knowledge
现有的大多数监督哈希方法是对已知类别的查询图像检索相关结果,因为可以利用监督信息理解查询图像。但是,当哈希系统对于未知类别没有先验知识时,未知类别的查询图像就会被错误理解,从而导致不准确的检索。主要原因之一是监督信息通常以0/1标签向量或点对关系的形式表示,使得标签相互独立,忽视了类别之间的高层语义联系。(例如,猫和卡车的区别比狗大)。如图3所示,当使用0/1标签时,每个类别被映射到超立方体的一个顶点,使得每两个类别之间的距离都相同。为了解决这个问题,我们提出利用NLP技术来关联语义标签。我们将0/1标签映射到词向量空间,从而标签之间的语义关系可以定量地计算。这样,未知类别就可以用与它相近的已知类别来表示。例如,在词向量空间,猫与狗之间的距离相近,即使哈希系统从未见过猫这个类别,仍然可以从狗这个类别中获得一些监督知识。我们用Wikipedia预训练语言模型。每个类别被映射成50维的词向量。
Semantic Alignment
由于领域差异、语义转移、符号学变异(domain difference, semantic shift, semasiological variation)等问题,从现成的词向量空间迁移而来的监督知识可能会偏离图像的潜在语义。为了解决这个问题,我们提出语义对齐策略,将初始的词向量空间与底层视觉特征进行对齐。我们寻求满足正交约束的转换矩阵R,来旋转标签矩阵Y进行修正。由于我们的目标是利用修正的监督知识来指导学习高质量的哈希编码和哈希函数,所以最小化下述误差:
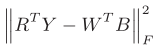
B是哈希编码,W是从哈希编码到监督信息空间的映射矩阵。上述语义转换可以有效缓解哈希编码和监督知识之间的语义鸿沟。
Hashing Model
我们的目标是利用语义标签Y,从已知类别的训练数据X中学习哈希函数,使得对于未知类别的测试数据也能生成高质量的哈希编码。同时,哈希函数的质量很大程度上依赖于训练数据的中间二进制码的可靠性。换句话说,该模型可以同时很好地控制哈希函数和哈希编码。为了达到这个目标,我们提出下述模型:
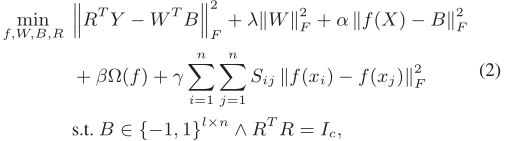
其中,R是语义旋转矩阵,W是从哈希编码到监督信息空间的映射矩阵,B是哈希编码,F代表矩阵的Frobenius范数,S是原始视觉特征空间的相似矩阵。
f(x)是从非线性特征空间到汉明空间的哈希函数,P是变换矩阵,用核函数 φ(x)来处理线性不可分问题,a是从训练数据X中随机选取的m个锚点。
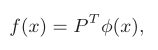
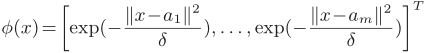
我们对B进行离散约束,以最大程度地避免哈希编码的信息损失。损失函数最后一项是为了保持训练数据的局部结构信息(相似性保持),也就是说,如果两个图像在原始特征空间相似,那么他们在汉明空间的哈希编码也相似。
Optimization
整个优化过程是交替迭代地优化:
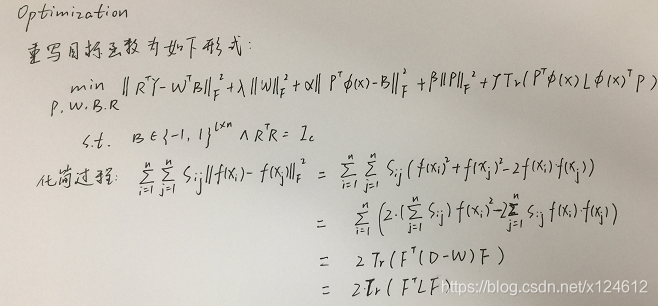




Algorithm Analysis
Convergence Study
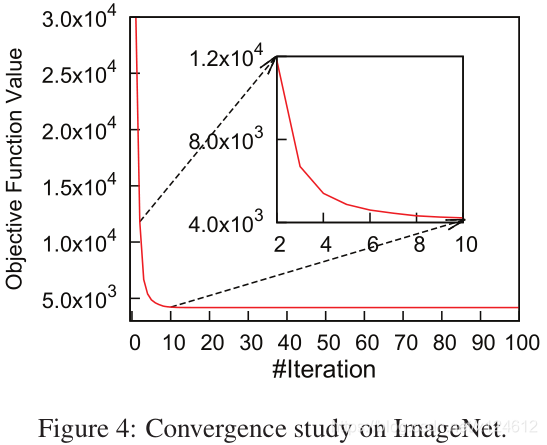
如算法1所示,在每次迭代中,所有变量的更新都会使目标函数的值减小。我们利用ImageNet对其收敛性进行了实证研究。具体来说,我们使用从ImageNet数据集中随机抽取的30,000幅图像训练ZSH模型,其中语义标签作为监督信息。我们随机选取了1000个anchor,并将哈希编码长度设置为64。如图4所示,目标函数的起始值约为30000,但在10次迭代中急剧下降,在第20次迭代时达到稳定的局部极小值。这一现象表明了我们算法的有效性。
Computational Complexity
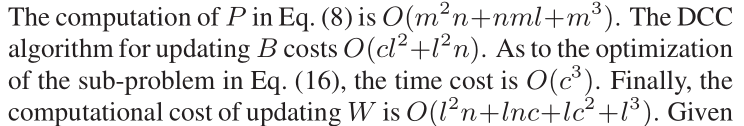
由于m ≪ n, l ≪ n, c ≪ n,并且算法在10次迭代后就收敛,所以算法的整体时间复杂度为O(n)。值得注意的是,算法的主要操作是矩阵乘法,它可以通过使用并行或分布式算法大大加快速度。
EXPERIMENT
Experimental Settings
实验用到了CIFAR-10,ImageNet and MIRFlickr 三个图像数据集。
CIFAR-10总共有60000张图像,包括airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck这10个类别,每个类别各有6000张图像,类别之间没有重复图像。
ImageNet是根据WordNet层次结构组织的图像数据集。我们的实验使用了ImageNet for The Large Scale Visual Recognition Challenge 2012 (ILSVRC2012)的子集,包括120多万张图像,标记了1000个类别。
MIRFlickr从社交摄影网站Flickr收集了25000张图片。该数据集于2008年首次引入,在多媒体研究中得到了广泛的应用。MIRFlickr是一个多标签的数据集,每张图像都与24个类别(如天空、河流等)相关联。
我们提取AlexNet的 fc-7层特征作为图像的视觉特征。
对于图像检索,常使用MAP和precision这两个评估指标。MAP侧重于检索结果的排序,我们取top5000的结果。precision侧重于检索准确性,我们取汉明距离小于2的结果。
我们将提出的ZSH方法与四个 state-of-the-art的监督哈希方法( COSDISH , SDH , KSH and LFH )进行对比。对于基于锚点的算法,我们从训练数据中随机选取1000个锚点。进一步地,我们比较了最具代表性的无监督哈希方法(Inductive Hashing on Manifolds,IMH)。
对于所有比较的算法,我们遵循其最优参数设置。对于ZSH,根据经验设置参数,α=0.000001,γ=0.0000001, λ=0.001,β=0.00001,迭代次数为10。原始特征空间的相似矩阵定义如下:N(x)是k个最近邻样本, σ = 1
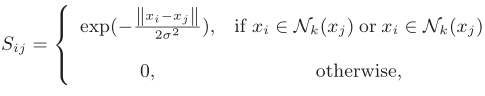
Results on CIFAR-10
Overall Comparison of Zero-Shot Image Retrieval
为了评价在未知类别中图像检索的有效性,我们将 CIFAR-10分成“可见”的训练集和“不可见”的测试集。我们选择"truck"作为未知的测试类别,其余9个类别作为已知的训练集。对于所有待比较的算法,我们随机选取10000张图像用来学习哈希函数。为了测试,我们从未知类别中随机选取1000张图像作为查询图像,剩下的5000张测试图像和已知类别的54000张图像一起构成检索数据库。
所有算法的性能如图5所示(哈希编码长度分别取16,32,64,96,128)。可以看到,对于MAP而言,提出的ZSH算法性能在不同编码长度都超过了所有其他哈希算法,对于precision而言,ZSH在大多数情况也表现出较高的检索性能。这是因为我们的方法在学习哈希编码和哈希函数时,不仅利用标签之间固有的语义关系来迁移监督知识,而且保持了数据的离散性和结构性。有趣的是,我们观察到,在precision上,无监督方法IMH甚至比一些监督方法(KSH、LFH)效果更好。这可能是因为,无监督方法仅仅利用特征空间的分布特性进行哈希编码,而监督的方法在学习过程中可能受到独立标签的误导。
当哈希编码长度从16-64变化时,所有算法的MAP都增长迅速,在64-128变化时,增长缓慢。当编码长度较短时,需要更长的编码来保证描述能力和区分能力,但是,当编码足够长时,表示能力饱和,提供更多的bit不能显著提高性能。对于precision而言,当编码长度大于64时,哈希性能显著下降。回想一下,我们的搜索半径根据经验设置为2,在汉明空间中形成一个半径为2的超球体。当代码长度从16增加到64时,检索能力的显著提高抵消了搜索的困难。然而,随着汉明空间的增大,搜索难度呈线性增长,从而降低了搜索精度。因此,为了在效率和有效性之间进行权衡,应该选择折衷的代码长度。
Effect of Different Unseen Category
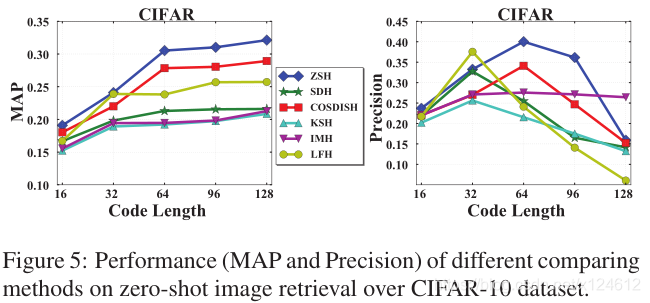
本实验中,我们试图评价ZSH方法在不同未知类别的性能。实验参数设置和上述一样,图6展示了将每个类别分别作为未知测试类别的MAP和precision。
可以看到在不同类别的性能有所变化,在bird最佳,automobile最差。直观地说,如果一个未知类别在语义上更接近于其他已知类别,则可以从词向量空间迁移更多相关的监督知识,从而提高检索性能。为了更深入地探究不同未知类别性能波动的原因,我们计算了每个未知类别与其他已知类别之间的平均余弦相似性,并在表1中列出了相应的MAP。
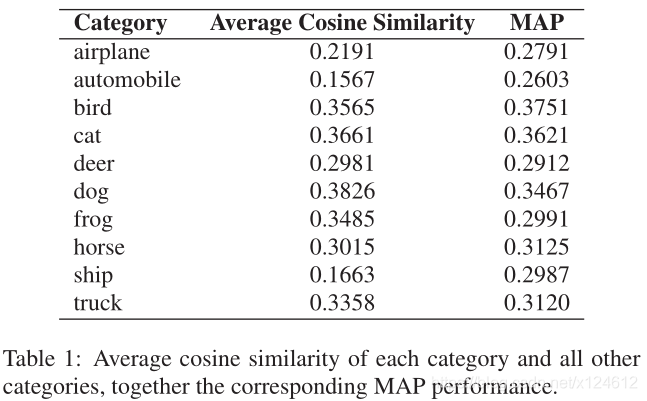
可以观察到,MAP性能与平均余弦相似度正相关。例如,余弦相似度较大的类别(如狗、猫)性能相对较好,而余弦相似度较小的类别(如飞机、汽车)性能相对较差。这说明,为了获得满意的检索结果,未知类别必须与已知类别具有足够的相关性。
我们还比较了实值语义标签和0/1二值标签的效果。语义标签的性能明显优于二值标签。其根本原因是语义空间可以帮助捕获已知类别和未知类别之间的关系,从而迁移监督知识。而二值标签忽略了语义相关性,导致检索性能出现不规则波动。
Effect of Seen Category Ratio
本实验中,我们评估在不同数量的已知类别时ZSH方法的性能。我们从0.1-0.9调整训练集中已知类别的比率。对于每个比率,我们从已知类别中随机选取10000张图片用于训练。然后,从未知类别中随机选取1000张图像作为查询,来检索剩下的59000张图像。当比率为0.1时,该类别的全部6000张图像都用来做训练集。
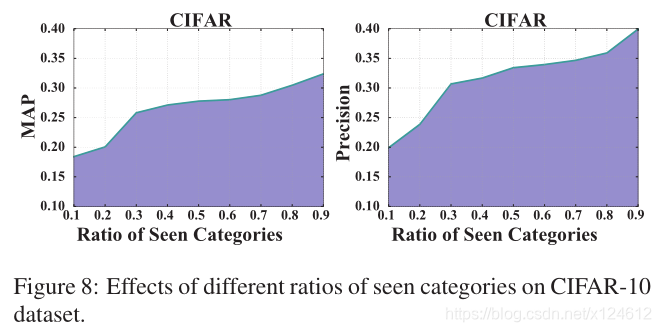
从图8中可以看到,(1)随着已知类别比例的增加,MAP和precision都有所提高;(2)当比例从0.1-0.3时,检索性能显著提高,而比例从0.3-0.9之间时,提升相对缓慢些。我们分析是当有较多的已知类别时,更有可能找到与未知类别相关的监督信息,
从而指导学习更好的哈希编码,同时提高哈希函数的质量。
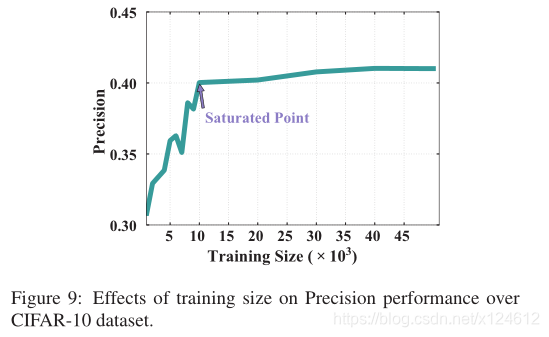
Effect of Training Size
本实验评价不同训练集大小对ZSH方法检索性能的影响。简便起见,我们选择precision作为评价指标,“truck”作为未知类别,训练集大小在{1000,2000,…,10000,20000,…,50000}范围内。
从图9可以看到,当训练集大小从1000-10000时,precision性能迅速提升。然而,随着训练数据的增加,ZSH性能没有显著提高。为了平衡训练效率和有效性,在余下的实验中,我们始终将训练规模设置为10000。
Results on ImageNet
Overall Comparison of Zero-Shot Image Retrieval
我们从ILSVRC2012数据集中随机选取100个类别,他们的词向量从Wikipedia中学习得到。这样大概有130000张图像,并将数据及分成训练集(90个已知类别)和测试集(10个未知类别)。对于所有算法,我们从已知类别中随机选取10000张图像用于训练,从未知类别中随机选取1000张图像用作查询,然后用学习到的哈希函数对剩余的图像进行哈希编码,来构建检索数据库。
图10展示了不同哈希编码长度的效果。可以看到,ZSH在大多数情况下优于其他方法。当哈希编码长度从16到128变化时,在 ImageNet数据集上的变化趋势与 CIFAR-10相同。这个现象再次表明,我们应该选择一个折衷的编码长度来保证检索性能。
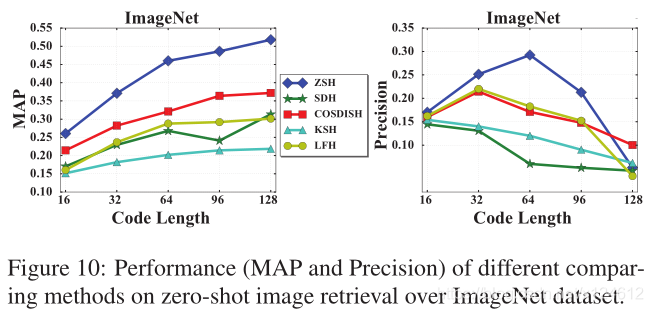
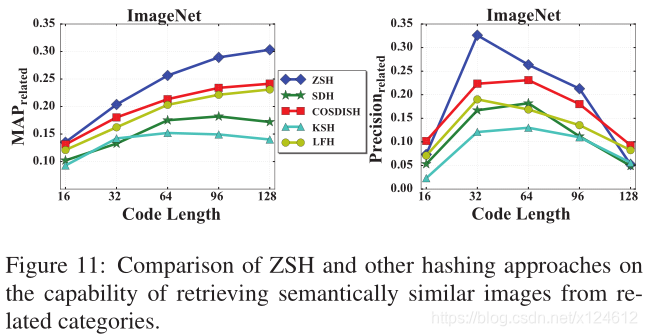
Image Retrieval in Related Categories
在零样本图像检索的场景中,我们希望即使无法检索到相同类别的相关图像,仍然可以得到语义相关的图像。例如,查询图像是一张猫的图片,我们更倾向于检索到狗而不是车。我们提出的ZSH方法是利用语义向量来建立起相似类别的联系。这样就可以通过迁移已知类别的监督知识来学习哈希函数,从而有效地对未知类别图像进行哈希编码。
由于我们需要检索更多的相关类别,全部剩余图像都用来构建检索数据库。参数设置同上。为了评价检索相关类别的性能,对MAP和precision进行修改。
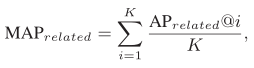
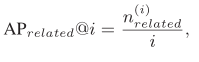
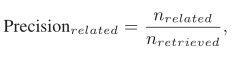
我们利用WordNet来定义查询类别A与检索类别B是否相关:(1)A、B不属于同一类别;(2)A可以在5步内到达B。
该实验中,K=5000。对MAP而言,在不同的编码长度,ZSH都优于其他方法。对precision而言,编码长度在32bits、64bits、96bits时分别达到了0.3262, 0.2636, 0.2129,比第二名都高出很多。这表明ZSH能够从最相关的类别中检测出语义相似的图像。
Results on MIRFlickr
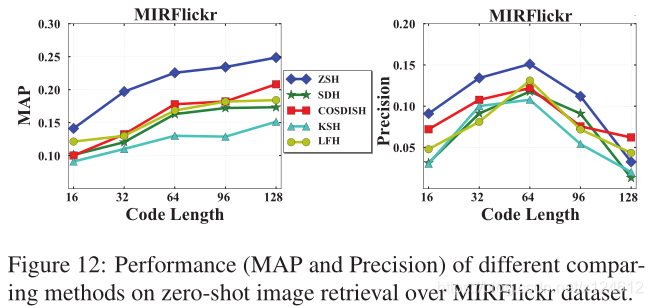
在真实图像中,特别是用户生成的照片,通常每张图像都有多个标签。为了进一步证明ZSH的实用性,我们在一个真实的多标签数据集上进行了实验,即MIRFlickr,它包含了从社交摄影网站Flickr上下载的25000张图片。每张图像都与24个标签相关联。在多标签图像数据集中,不同类别的图像有重叠,使得数据集难以划分为训练集和测试集。因此,我们利用ImageNet作为辅助数据集来训练哈希函数,并在MIRFlickr数据集上评价零样本图像检索的性能。我们从ILSVRC2012中选取了与MIRFlickr的24个标签不同的类别。公平起见,所有的哈希方法都是随机抽取10000张图像用于训练。然后用学习到的哈希函数对MIRFlickr中所有图像进行哈希编码,并从中抽取1000张图像作为查询图像,在其余24000张图像中检索。我们认为与查询图像至少共享两个标签的是正确近邻。在图12中,对MAP而言,在不同的编码长度,ZSH都优于其他方法。随着代码长度的增加,所有算法的MAP性能不断提高,ZSH在128bits时达到0.2488,而第二名COSDISH是19%。对precision而言,ZSH在大多数情况下超过了所有其他方法。与CIFAR-10和ImageNet相似,从16到64呈上升趋势,性能从64下降到128。在MIRFlickr上的良好性能证明了ZSH在索引和搜索真实图像数据方面的潜力。
CONCLUSION
随着网络上新兴概念和多媒体数据的爆炸式增长,无法为现有的监督哈希方法及时提供足够的标记数据。在本文中,我们研究了如何从有限的已知类别中学习哈希函数,来对未知类别的图像进行哈希编码。我们提出一种新颖的哈希方案,ZSH,它能够将已知类别的监督知识迁移到未知类别中。独立的0/1形式的标签被映射到语义丰富的词向量空间,从而标签的语义相关性能够被很好地描述和量化。考虑到领域差异和语义偏移问题,我们利用语义对齐来减小哈希编码和高层语义的差距。具体的,我们旋转了词向量空间来修正监督知识,从而学习高质量的哈希编码。此外,在ZSH模型中,还保留了哈希编码的局部结构特性和离散性质。我们设计了一种高效的算法对模型进行迭代优化,实验结果表明了算法的收敛性和有效性。我们在三个真实图像数据集上评估了提出的ZSH方法,包括CIFAR-10、ImageNet和MIRFlickr。实验结果表明,与现有的几种哈希方法相比,ZSH算法在零样本图像检索方面具有明显的优越性。
在后续工作中,我们期望通过整合文本和视觉等多种来源的知识,加强对标签语义关联的探索。我们希望这将弥补单模态的不完全表示,从而从根本上解决领域差异和语义偏移问题。
DRAWBACKS
Supervised Knowledge:
监督信息只使用了标签的语义向量,可以考虑利用文本、图像、视频等多源信息,或者利用属性信息(目前大多是预先定义的attribute,如何自动学习属性特征?)
Semantic Alignment:
本文只是旋转词向量空间,可以考虑其他方法来解决semantic shift问题
Hash Model:
本文是先提取图像特征,再利用相似性保持和离散性质两个特性来构建哈希函数,可以考虑利用深度哈希方法,同时学习图像特征和哈希函数,避免信息损失;
本文利用已知类别训练好的哈希函数,直接对未知类别进行哈希编码,由于分布不同,可能存在domain shift的问题,可以考虑domain adaptation策略,增量学习,强化学习等
Transductive:
zero-shot的另一种情形是,训练数据中除了已知类别的数据,还存在大量包含已知类别和未知类别的无标签数据,如何利用这部分信息?(Transductive Zero-Shot Hashing via Coarse-to-Fine Similarity Mining)
Multi-label:
如何融合多标签信息,来构建新的标签?
OOV-label:
对于在词向量的词表中未出现的新类别,如何处理其标签?