前言
我建议大家最好和我一样将软件放在同一个位置,当然你可以自己放别处,但是你得记清楚你的安装位置
下载hadoop和Java
这里得注意一下:建议小心找一下64位的jdk,不然后面容易出错
这里我准备的是jdk-8u162-linux-x64.tar.gz和hadoop-2.7.2.tar.gz
解压JDK
cd /opt/
sudo mkdir module
chown hadoop:hadoop -R module
cd module
mkdir jvm
#解压命令,根据你自己下载地址解压,我的在~/Downloads
cd ~/Downloads
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/module/jvm
#写入环境变量里面,我加入的是用户变量
sudo vim ~/.bashrc
#加入内容
export JAVA_HOME=/opt/module/jvm/jdk1.8.0_162
export PATH=${JAVA_HOME}/bin:$PATH
#刷新
source ~/.bashrc
解压Hadoop
cd ~/Downloads
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
cd /opt/module/
mv hadoop-2.7.2 hadoop
修改基础配置
sudo vim /etc/hostname
# 添加下面这句话
HOSTNAME=Master
sudo vim /etc/hosts
# 添加下面内容,记住你自己写的IP地址和名字,之后需要在某些文件上用到
192.168.154.80 Master
192.168.154.100 Slave1
vim ~/.bashrc
#加上这些内容
export HADOOP_HOME=/opt/module/hadoop
export PATH=${HADOOP_HOME}/bin:$PATH
export PATH=${HADOOP_HOME}/sbin:$PATH
修改hadoop的文件
修改slaves文件
需要修改五个文件
cd /opt/module/hadoop/etc/hadoop
vim slaves
localhost
Slave1

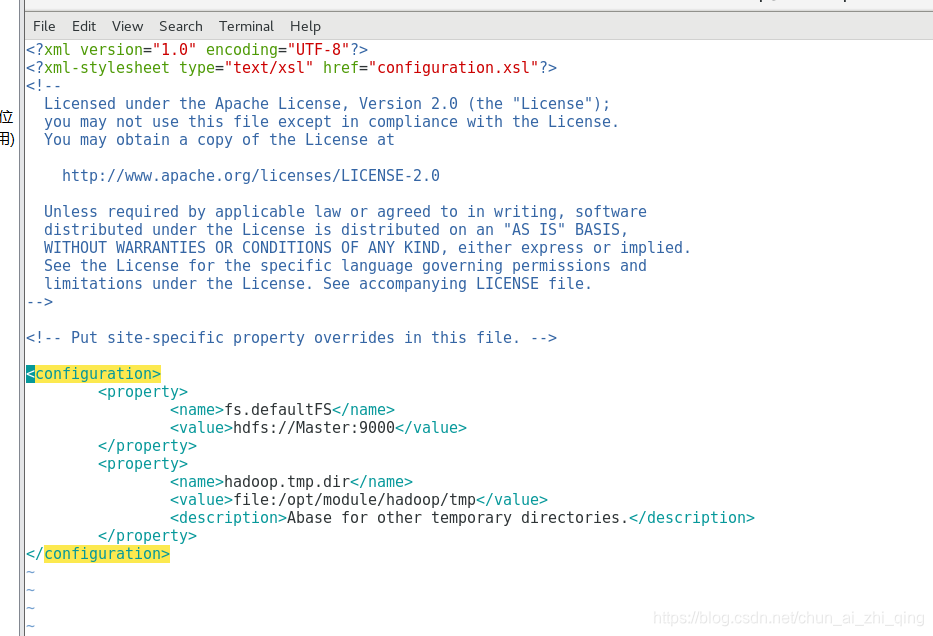
修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop/tmp/dfs/data</value>
</property>
</configuration>

文件 mapred-site.xml
(可能需要先重命名,默认文件名为 mapred-site.xml.template)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>

yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>

克隆虚拟机




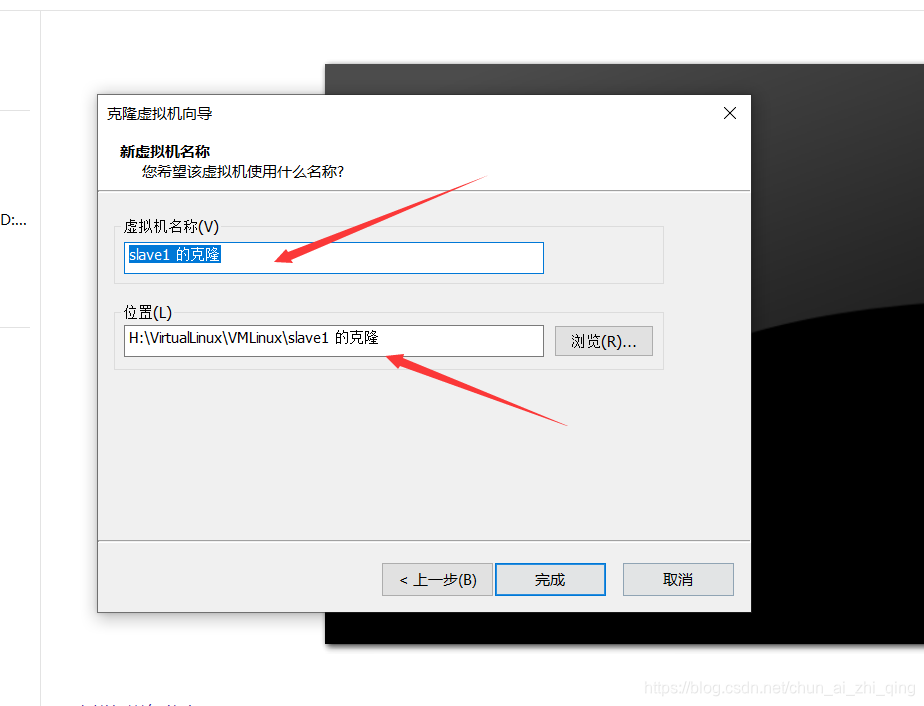
配置新的虚拟机
还记得我们之前配置的hosts文件吗?我们该用上了
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
#修改为hosts的Slave1的IP
IPADDR=192.168.154.100
sudo vim /etc/hostname
# 添加下面这句话
HOSTNAME=Slave1
两台电脑重启
运行
hdfs namenode -format
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
免密码运行(可配可不配)
主机输入命令
ssh localhost #之后输入密码
exit;
cd ~/.ssh
rm ./id_rsa*
ssh-keygen -t rsa #一直回车
cat ./id_rsa.pub >> ./authorized_keys
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
从机输入命令
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
修改两个机器的ssh配置
sudo vim /etc/ssh/sshd_config
#找到下面这句话,把注释去除
PasswordAuthentication yes
#重启服务
systemctl restart sshd.service
两台电脑运行下面命令
chmod g-w /home/hadoop
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
eval "$(ssh-agent -s)"
ssh-add
版权声明:本文为chun_ai_zhi_qing原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。