目录
3.2.1 select_rgb_white_yellow()
1 项目介绍
我现在有这样一个停车场的航拍视频parking_video,mp4

处理视频与处理视频一样,就是把视频的每一帧抽出来然后处理图像
我们现在做三个事情
- 停车场一共有多少车位被占据
- 停车场一共有多少车位没被占据
- 标识出没有被占据的停车位
结果是这样的,我们可以看到也不是特别准,这个是因为我数据量不够,如果增加数据量会有更好的效果
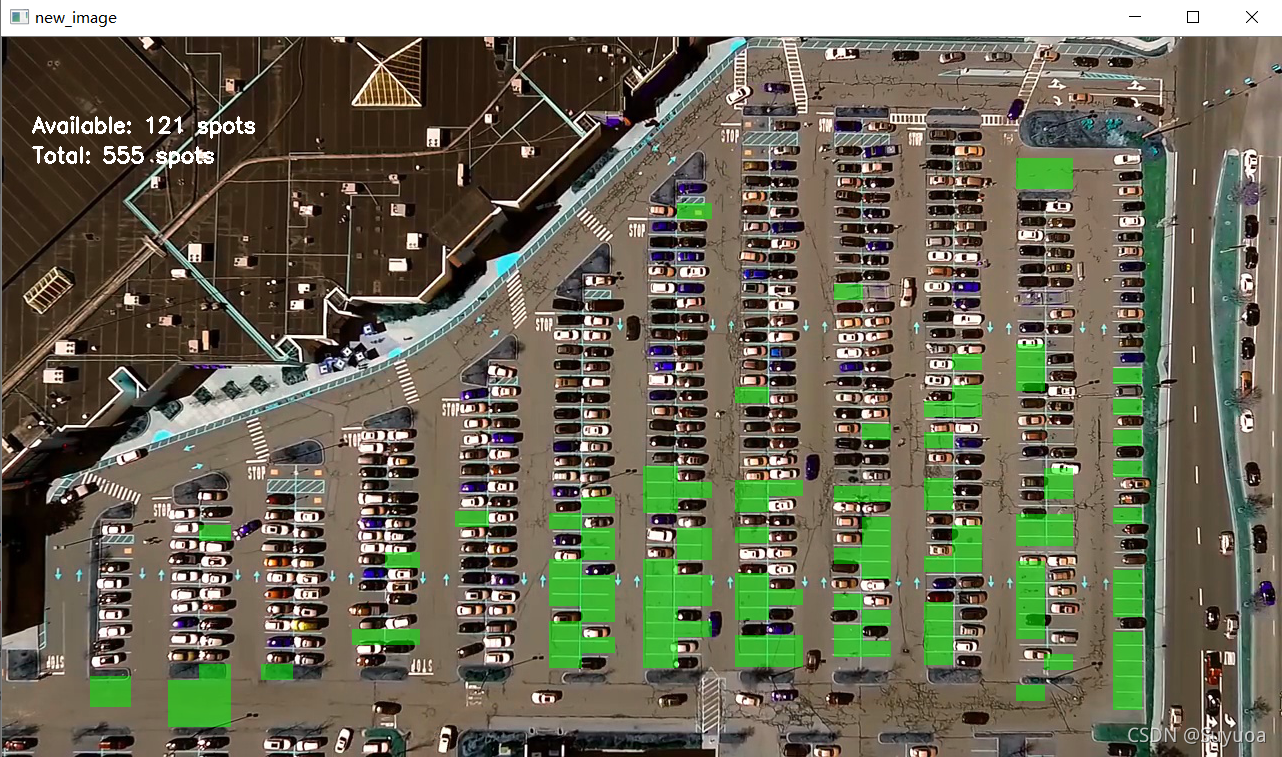
由于我们要处理视频,这个项目对计算机的算力是有要求的,像我这个机器是NVIDIA GeForce GTX 970M,是无法让这个视频实时判定的(会卡,但是如果够耐心也可以走完)
我们这个项目一共有三个py文件
train.py会训练出模型carl.h5供park_test使用
Parking中定义了一个工具类,其中有若干种方法供park_test使用

2 展示图像
2.1 park_test
2.1.1 导入库
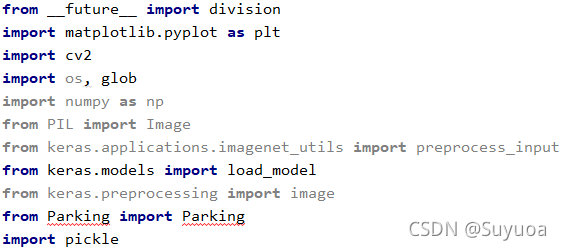
Parking是上面提到的提供方法的Py文件,pickle是存储文件用的,这个用的时候再提
之后我们就从main来分析
2.1.2 读取测试数据
![]()
我们的测试数据一共有两张图片

2.1.3 读取模型与视频

- 我们此时还没有模型,下面会进行训练,但是不影响在这里定义,因为weights_path现在只是一个字符串
2.1.4 定义分类

我们的分类是字典形式的
![]()
2.1.5 show_images()
实例化工具类后调用工具类种的show_images()方法

2.2 Parking
2.2.1 导入库

2.2.2 show_images()


定义工具类后定义show_images函数,参数为输入的图像与camp,camp是颜色映射,在这里我们没有使用,我们在主函数中只传入了两张图像

之后我们确认列与行,cols是列,row是行,由于我们只有两张图,计算出来是1行2列

将图片大小改变为15*12
![]()
对两张图片进行枚举,之后放在指定的位置
![]()
- enumerate的序号是从0开始的,需要+1才能放到指定的位置上,我举一个例子plt.subplot(1,2,1),这个的意思是按照1行2列排好,然后将该图放到1的位置上
进行判定,如果图像的shape长度为2(图像是灰度图),那么camp置为gray,否则保持不变,我们这里图像不是灰度图,所以camp还是None,我们print出来看一下

由于是两张图所以会出现两个None
![]()
将图绘制出来,不设置横纵坐标

把图像拉大填充至整个图像区域,pad是图像距离图像区域两侧的边距,h_pad是填充后图像之间的纵向间距,w_pad是填充后图像之间的横向间距,拉大后展示出来

如果不加入tight_layout的话会是这样

加入后是这样

3 图像预处理
3.1 park_test
之后回到主函数

3.1.1 img_process()
这个是我们主函数的方法

在img_process()中的第一步调用了park中的select_rgb_white_yellow的方法
3.2 Parking
3.2.1 select_rgb_white_yellow()
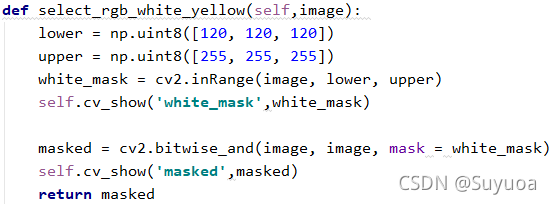
首先定义lower和upper两个阈值
![]()
之后我们使用inRange函数,inRange会筛选掉我们不像要的颜色,如果低于低阈值则将像素点值置为0,如果高于高阈值则将像素点置为0,在两阈值之间的值置为255,参数如下
- image 要处理的图像
- lower 低阈值
- upper 高阈值
![]()
- 这个函数会对三个通道分别进行处理
image这个参数是我们从map这个方法传入进来的
![]()
我们的white_mask是这样的


之后我们使用bitwise_and,这个是图像的与运算,如果对两张相同的图像做与运算,图像还是其本身,我们现在先看没使用mask的情况
![]()

- 后面的所有步骤我就只展示第一张图了
我们比较关注的点应该是图像中有一部分变为青色了,这是因为我们读取图像时用的是plt进行读取,plt与cv2的通道顺序不同,所以会变为青色,这个不重要,一会儿会进行二值处理,都会变成黑色或白色
现在我们再看一下带mask的,mask会保留图像中白色的区域,然后将黑色的区域置为黑色


得到返回值masked后我们回到 img_process()
3.3 park_test
3.3.1 img_process()
我们把得到的两个结果做成一个集合,然后一起展示一下
![]()

之后将上一步的结果使用park中的convert_gray_scale处理
![]()
这个实际上就是将图转为灰度图,我就不单开一个标题来写了
![]()
转换完之后我们展示一下

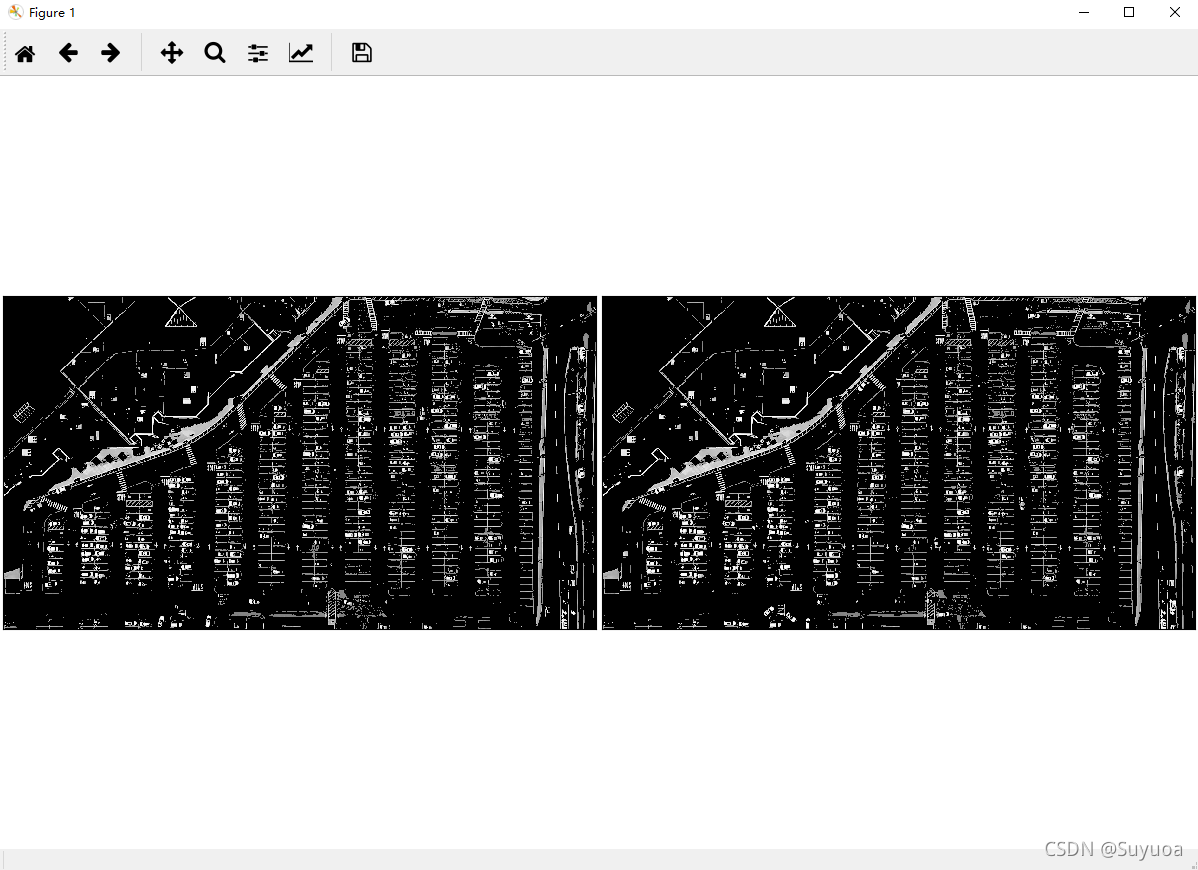
到上面这一步就消除了plt与cv2通道不同的问题,现在都变成白色了
下面我们把刚刚的结果传递给park中的detect_edges()
![]()
detect_edges实际上是用Canny做了边缘检测,阈值为(50,200)
![]()
x现在我们的edge_images是这样的

之后我们使用park中的select_region操作上面的结果
![]()
3.4 Parking
3.4.1 select_region()
这一步的功能是在指定的点上画圈

首先我们获取图片的宽与高,这里面用的变量名是rows和cols(行与列)后面赋值的内容是shape,所以为宽与高
![]()
画出图上的六个点
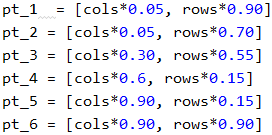
将六个点做成点集
![]()
将传入的图片复制一张,之后将其由灰度图转为RGB图
![]()
由彩色图转为灰度图后,再使用灰度图转到彩色图,图像不会变成彩色的,转前与转后的区别的通道的变化


画圈
![]()
展示
![]()

之后会返回我们工具类中的另一个方法filter_region()
![]()
3.4.2 filter_region()

首先我们看传入的参数
- image 图像
- vertices 点集
之后我们搞一个与图像大小相同的全0的numpy.ndarry
![]()
我们看一下mask的shape

![]()
之后进入判定,如果mask的shape的长度为2那么进入分支,进入分支后使用cv2.fillPoly为图像绘制有填充的多边形,参数
- mask 要绘制的图像
- vertices 点集
- 255 要填充的颜色(白色)
绘制完之后使用cv_show()展示出来

我们现在的mask是这样的

最后返回图像与mask的与运算

白色(255)与其他值做与运算结果为其他值,黑色(0)与其他值做与运算结果为黑色,我们下面做两个例子
- 白色(255)与100与运算
11111111 = 255
01100100 = 100
01100100 = 100
- 黑色(0)与100与运算
00000000 = 0
01100100 = 100
00000000 = 0
也就是说现在我们return的图像,除了在mask中白色的部分有内容,其余部分全部为黑色

由于我们只关注白色车位的区域,别的地方我们不关注,所以就过滤掉

3.4.3 select_region()
filter_region获得返回值后,select_region也走到了最后一步,select_region的返回值就是filter_region的返回值

3.5 park_test()
3.5.1 img_process()
我们看一下返回值的样子

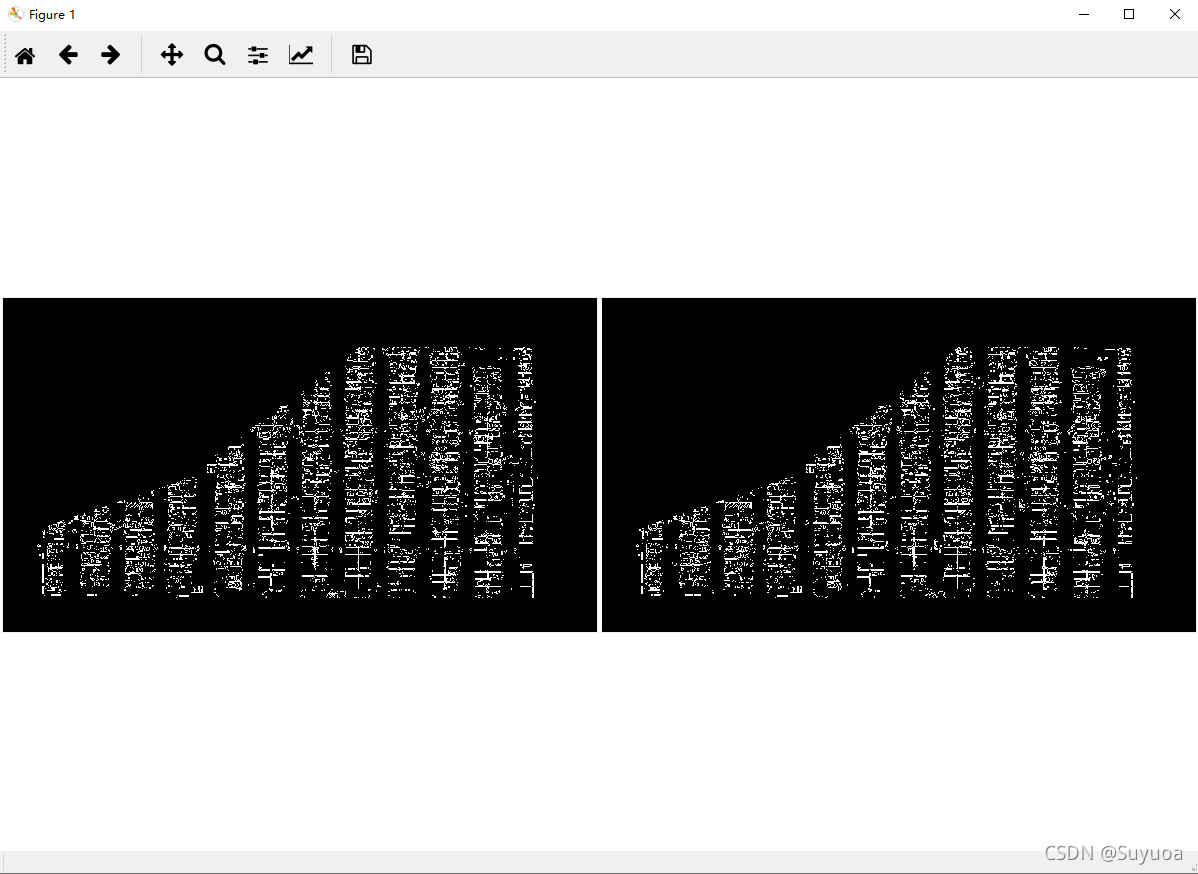
之后我们对上面的结果使用工具类中的hough_lines方法
![]()
这个方法使用的是cv2.HoughLinesP这个方法,这个方法是专门找图像中的直线的,涉及到的参数如下
- image 要找直线的图像
- rho 距离精度
- theta 角度精度
- threshod 阈值,图像上更多的是看似直线的曲线,现在我们有若干个点,我们拟合成一条直线,拟合后的直线还能连到阈值个数的点我们就认为这条线是一条直线,这个阈值指定的越大,我们得到的线就会越少
- minLineLength 线的最短长度,比这个短的都会被忽略
- MaxLineCap 两条直线之间的最大间隔,小于此值系统会判定两条临近的直线为一条直线
这个方法的使用详情 python opencv检测直线 cv2.HoughLinesP_Snoopy_Dream-CSDN博客_cv2.houghlinesp
- HoughLines与HoughLinesP的用法一样,HoughLinesP的运算速度比HoughLines更快

我们执行完这个方法后会得到两组直线(一张图一组)

我们创建一个line_images的空列表,由于我们是两张图,每一张图有对应的一组线,我们把他们压到一起然后分开遍历,之后调用park的draw_lines方法

3.6 Parking
3.6.1 draw_lines()

首先看参数
- image 传入的单张图像
- lines 图像对应的单组直线
- color=[255,0,0] 颜色默认为红色
- thickness=2 线宽为2
- make_copy 是否复制,默认为True
我们在主函数中没有复制make_copy,所以默认为True,我们复制了一张image图像

然后创建一个空的列表clean
![]()
之后进入判断,首先遍历一组线获得每条线,之后对每条线进行遍历,每条线的信息有(x1,y1)与(x2,y2)(起始点与终止点),我们提取出x1,y1,x2,y2,之后进入判断
- 条件1 终止点y值与起始点y值的距离(起始点与终止点的纵向距离) <= 1,这个条件是保证如果是横线不会太斜,筛选掉几乎所有的纵向线
- 条件2 25 <= 起始点与终止点的横向距离 <=50
如果满足以上两个条件,将线的信息进入到cleaned中并将其连成一条线画出来

- abs()会返回运算的绝对值
之后打印过滤过后线的数量,之后返回画好线的图像

3.7 park_test
3.7.1 img_process()
之后回到park_test,我画红框的地方是一张画好线的图像,我们把这个图像添加到line_images中,之后展示出来
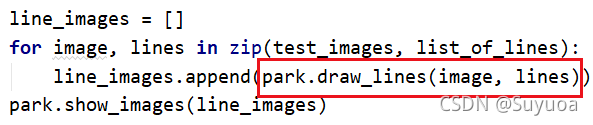
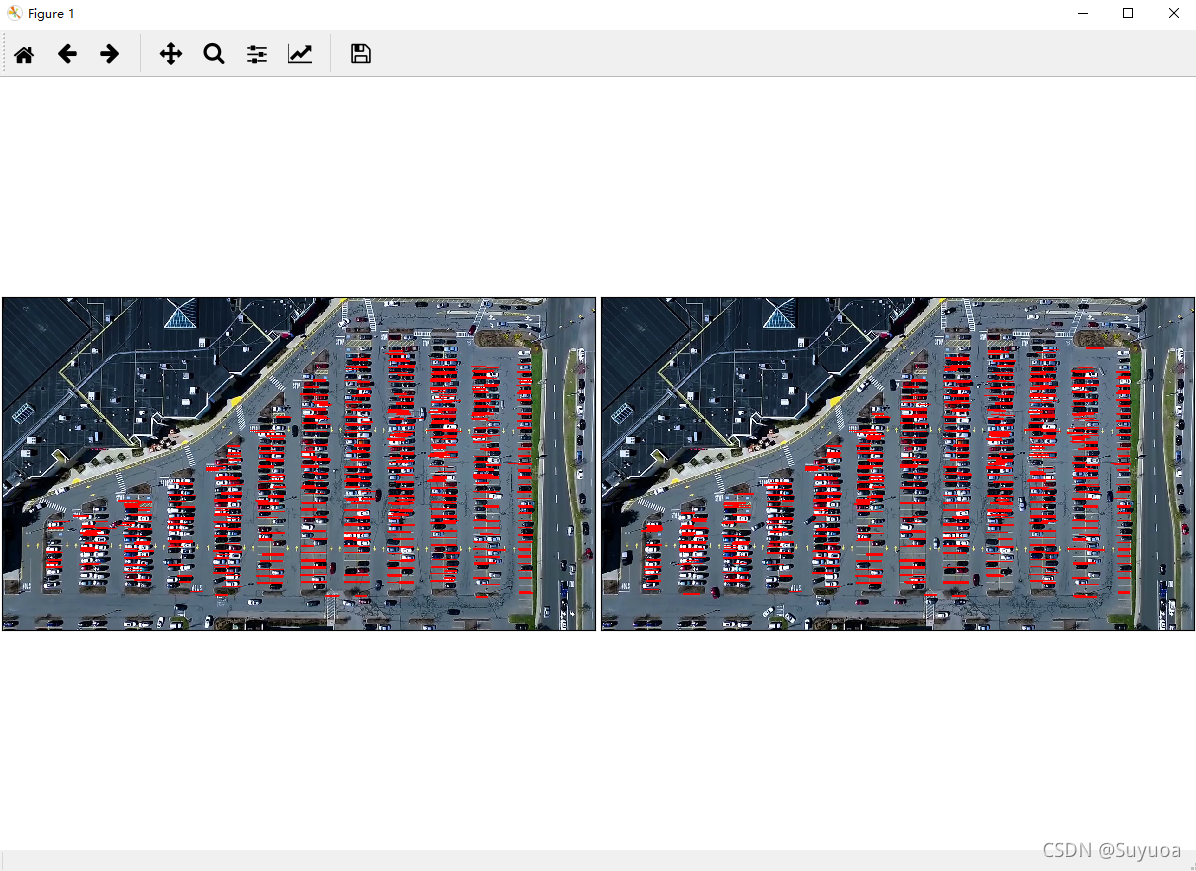
我们第一章图检测出来了588条线,第二章图检测出来了581条线

之后我们创建rect_images与rect_coords两个空列表
![]()
之后遍历两张图像与对应的线集,然后将元素传入park.identify_blocks()

3.8 Parking
3.8.1 identify_blocks()
这个太长了,我们就不截取全部了,先看传入的参数,图像与线集,make_copy默认为True,进入方法后先把图片复制下来

3.8.1.1 过滤部分直线
创建一个空列表cleaned,然后遍历线集中的每条线,遍历每条线中的两个点,之后进入判定
- 条件1 终止点y值与起始点y值的距离(起始点与终止点的纵向距离) <= 1,这个条件是保证如果是横线不会太斜,筛选掉几乎所有的纵向线
- 条件2 25 <= 起始点与终止点的横向距离 <=50

这一步和上面操作一样,只是因为我们过滤过的线没有返回,所以在这里要再做一遍,我们正好在这里看一下clean是什么样子的
我截取了头和尾,我们可以看到总体是一个列表,列表中有若干元组


3.8.1.2 根据起始点的坐标进行排序

operator是python内置的库,我模拟一下是如何排列cleaned的
import operator
a = [(744, 337, 794, 337), (744, 291, 700, 291), (358, 540, 387, 540)]
b = operator.itemgetter(0,1)
list1 = sorted(a,key=b)
print(list1)![]()
如果我们在itemgetter中只写0,那么只对x1进行排序,如果相等就随机,如果写itemgetter(0,1),那么当x1相同时会按照y1的大小排列

首先我们创建空字典clusters,然后定义dIndex与clus_dist
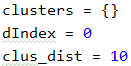
之后我们进入循环,循环次数为排序好的线集长度-1,,之后获取两个线的横坐标距离,如果获取的距离小于等于clus_dist(10)则进入分支
- if 分支: 如果clusters这个字典中没有key为dIndex的键值对,则创建一个以dIndex为键的键值对,键值对内容为空的列表,然后在列表中添加比较横坐标距离的两条直线
- else分支: dIndex + 1
上面这个分支走完会进行下一轮循环,clusters的一个key中会找出横向距离少于10的所有临近线
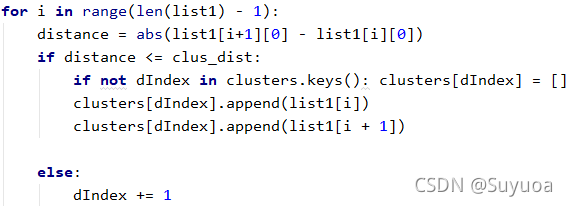
我们看一下此时的clusters

下面这个图只是一部分

我们这一步的目的是找列,所以我们关注的是键而不是值

之后创建一个rect的空字典,赋值i为0
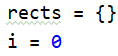
之后遍历clusters,clusters是上面创建的字典,键为dIndex,值为一个列表,列表内容为比较横坐标的两条线

第一步我们提取clusters的key号键的值赋值为all_list,之后我们使用set去掉列表中重复的内容,然后使用list返回一个新的列表,我们看一下all_list与cleaned

下面这个是循环第一轮的结果

cleaned的结果意思是我一列中包含的横线的内容,之后对cleaned进行判断
如果我一列中超过了5条横线,那么进入分支,进入分支后以横线起始点的y值大小对cleaned进行排序,排序之后我们选择最小的y值赋值为avg_y1,最大的y值赋值为avg_y2,之后定义avg_x1与avg_x2都为0,之后遍历cleaned,将起始点的所有x值加和赋值为avg_x1,将终止点的所有x值加和赋值为avg_x2,之后将起始点的平均x值赋值给avg_x1,终止点的平均x值赋值给avg_x2,然后把(平均起始点x值,最小y值,平均终止点x值,最大y值)做成一个元组然后赋值给rects的i这个键,然后i自加

- 我们如果连接(avg_x1,avg_y1)(avg_x2,avg_y2)这两个点,这条线是一条斜线
我们此时的i就是len(rects)就是图像中的列数,我们看一下结果
![]()
两张图的结果都是12

3.8.1.5 画出列矩形
这个buff是根据图像做出的微调,我们刚刚获取到了两个点,现在我们对x进行微调后,画出列矩形,然后返回绘制好矩形的new_image与包含矩形左上角点与右下角点的字段rects

到这我们工具类中的identfy_blocks()就结束了,我们返回park_test看一下结果
3.9 park_test
3.9.1 img_process()
将获得到的返回值分别放入rect_images与rect_coords的空列表中
- 因为是两张图,所以要放在列表中

之后展示图像


我们继续向下看

创建delineated与spot_pos两个空列表
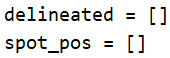
遍历test_images(原图)与rect_coords(矩形角点字典),进入循环后调用工具类中的darw_parking方法

3.10 Parking
3.10.1 draw_parking()
这个也很长,不展示了,先看传入的参数
- image 原图
- rects 矩形角点字典
- make_copy 是否赋值
- color 颜色
- thickness 线宽
- save 是否保存
![]()
进入方法后复制一张原图

定义gap,spot_dict,tot_spots三个值,后面会用到gap是每一列中横线的间距

一共是12列,对应12个键,我们对每个点的位置做微调,后面会调现在还没调

遍历矩形角点,对每个角点进行微调

把微调后的新矩形画出来
![]()
我们取y值的距离,然后整除15.5,之后将这个值变为整形赋给num_splits,这个值是每列的行数
![]()
之后循环行数次,y1是微调后起始点的y值,我们将这个值加上i个间距,然后赋值给y,然后在(起始点x,y),(终止点x,y)画一条横线

这样我们就会画出这样的横线,每一条横向的长度相同,每一条横线相互平行
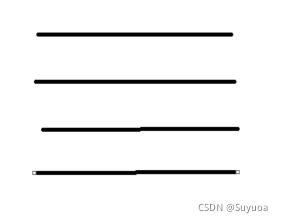
之后进入判定,如果key >0且key<rects长度-1,这个的意思就是不算第0条线,其余全算,过滤之后平均起始点与终止点的x,然后画竖线

之后再进入一个判定,这次是rects中的第0列和最后一列,第0列与最后一列的车位我们算作 行数+1,其余的我们算作 2倍的(行数+1),因为其余列一行能放两辆车,然后将每一行的车位数都加在一起得到tot_spot(总车位数)

- 这里注意我们是顶着上面for循环的,我们每一轮的num_splits获取的值是不一样的
之后我们进入判定

- 如果当前是第0列或最后一列,我们进入循环,循环次数为每一列的行数+1,我们获取spot_dict,这个现在还是空字典,然后我们将起始点y+行数*间距,然后将spot_dict的值置为(起始点x值,y,终止点x值,y+gap),键位cur_len + 1

现在这个点的位置实际上是这样的,这一步是确定每个车位的角点

- 其余列的处理与上面的处理相似,我就简单画一下每个点的位置

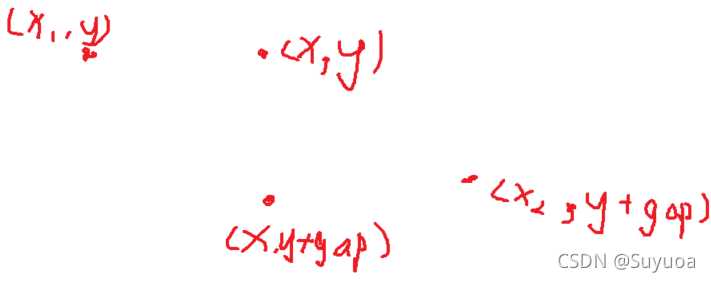
上面这四个点是一行两个车位的角点
之后打印出全部车位与当前车位,这个实际上两个值应该是相似的
![]()
如果保存(默认为保存),我们会保存new_image名为with_parking.jpg,然后返回new_image(画好线的图片)与spot_dict(车位角点的字典)

到此我们draw_parking()结束,现在返回park_test
3.11 park_test
3.11.1 img_process()

将上面两个返回值分别保存起来,然后我们看一下两张画好线的图片

之后我们提取第二张图的车位角点字典,然后查看它的长度(一共有多少个车位)

![]()
- 提取第二张图的原因是第二张图画的好,如果还在这个位置拍摄停车场,我们认定有555个车位
之后我们使用pickle.dump把车位角点信息存储起来,这样我们下次读取车位信息我们直接读这个文件就行了,而不用再进行一次图像预处理

我们看一下pickle.dump的参数
- final_spot_dict 要存储的内容
- handle 要存储到的文件
- protocol 存储的协议,这个是可选参数,我们就用这个就完了,在读数据的时候保持和写数据时相同就可以了
之后我们使用park中的save_images_for_cnn()
![]()
4 获取数据
4.1 Parking
4.1.1 save_images_for_cnn()
我们先看传入的参数
- image 第1张图像
- spot_dict 车位角点字典
- folder_name 文件夹目录
进入方法后,遍历车位角点集的值,然后提取出每个值赋值到(x1,y1,x2,y2)元组中,如果x1,y1,x2,y2中有浮点数对其取整,之后对图片进行裁剪,把车位的图像菜蔬来,然后放大两倍,把值对应的键赋值给spot_id,然后确认文件名称,之后打印出来,然后存储

我们在cnn_data这个文件夹中会保存555张车位的图片

这个函数没有返回值,调用完之后我们回到park_test
4.2 park_test
4.2.1 img_process()

执行完save_images_for_cnn()后返回final_spot_dict(车位点集),至此img_process()结束
5 训练模型代码 train.py
这个属于人工智能范畴,在我的另一个专栏中会有介绍
https://blog.csdn.net/potato123232/category_11202555.html
在本项目中这一步的结果是会训练出carl.h5这个模型
5.1 导入库

numpy是我测试时用的,os是python自带的搞路径的库,其余都是keras这个库中的方法
我当前keras版本为2.4.3,使用pip install keras就可以安装了

tensorflow中也有keras这个库,如果有tensorflow我们在代码的最前面加上
import tensorflow.keras as keras
就可以使用keras了
如果这样做keras这个库是继承tensorflow的,我当前的tensorflow的版本为2.3.0
![]()
tensorflow-gpu的windows下的安装方式
1.安装tensorflow_potato123232的博客-CSDN博客
如果是linux或者mac与windows的安装方式相似
如果设备中没有GPU(显卡),我们也可以使用tensorflow的cpu,cpu不需要安装显卡驱动,cuda,cudnn
5.2 定义两个变量
![]()
- file_train 训练集数量
- files_validation 验证集数量
5.3 确定训练集图片数量与测试集数量
数据都是从上面获取的数据中挑出来的
5.3.1 训练集
我们在train_data/train中有两个文件夹

empty是没被占用的停车位图片

occupied是被占用的停车位图片

此时我们指定路径为train_data/train,然后使用os.listdir获取empty与occupied这两个文件夹,之后分别遍历两个文件夹下的所有文件,每遍历到一个文件files_train就+1

- os.walk()会返回一个迭代器,使用next遍历os.walk的结果
5.3.2 测试集

测试集中也有empty和occupied两个文件夹,empty内容为空闲的车位照片,occupied为占用的车位照片,测试集的照片与训练集的照片不相同
用同样的方法确认测试集数量

5.3.3 显示训练集与测试集照片个数
![]()
![]()
5.4 定义训练所需参数

- img_width 图像宽度
- img_height 图像高度
- train_data_dir 训练数据路径
- validation_data_dir 测试(验证)数据路径
- nb_train_samples 训练数据个数
- nb_validation_samples 测试(验证)数据个数
- batch_size 一次放多少数据
- epochs 训练轮数
- num_classes 训练类别
5.5 使用VGG模型

到这一步会自动下载一个文件,如果有请求失败多试几次就可以了
5.6 减少层
选中前10层,前10层不参与训练
由于我们使用的是预训练模型,我们想让模型简单一点,所以减少10层
![]()
5.7 改变输出层
我们将模型的输出层提取出来定义为x,然后我们查看一下x的情况

![]()
之后我们将输出层定义为Flatten

![]()
最后我们更改其为2分类,激活函数为softmax的dense层作为输出层

5.8 新建神经网络
我们之后的神经网络就为model_final,我们下面训练也是使用model_final进行训练的,我们现在看一下这个网络的概况
![]()


5.9 编译神经网络

- loss 损失值
- optimizer 优化器
- lr 学习速率
- momentum 动量值
- metrics 指标
5.10 图像增强
首先是训练数据增强

- rescale 归一化,因为图像的值区间是[0,255]所以一般就为1/255
- horizontal_flip 是否水平翻转
- fill_mode 填充模式
- zoom_range 缩放比例
- width_shift_range 水平方向平移幅度
- height_shift_range 垂直方向平移幅度
- rotation_range 数据提升时图片随机转动的角度
详情可见 tensorflow中图像增强的方法详解 - 帅帅的飞猪 - 博客园
然后是测试数据增强

5.11 数据集合
训练集

- target_size 目标尺寸
- batch_size 一次传多少数据
- class_mode 这个我们现在设置为分类
测试集

5.12 定义训练节点
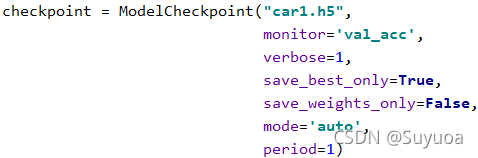
- 模型名称carl.h5
- monitor 监控指标
- verbose 信息展示模式
- save_best_onle 是否只储存最好的
- save_weights_only 是否只储存权重
- mode 评判准则
- period 周期,每几个epoch存一次
详情参考 ModelCheckpoint详解_you 是 mine-CSDN博客
5.13 定义提前中止该轮训练

- monitor 监测数据
- min_delta 增幅或减小阈值
- patience 容忍程度
- verbose 信息展示模式
- mode 评判准则
详情参考 [深度学习] keras的EarlyStopping使用与技巧_小墨鱼的专栏-CSDN博客_earlystopping
5.14 训练

5.15 保存
![]()
此时我们就得到了 carl.h5 这个模型文件,之后我们会调用它,下面我们就按主函数park_test执行的顺序来分析了
6 读取模型
6.1 Park_test
6.1.1 keras_model()
我们现在回到main中执行keras_model
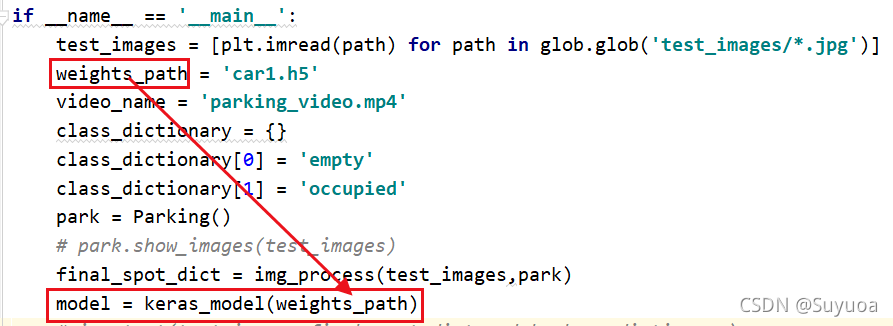

![]()
这个就是使用keras方法读取我们训练好的模型
7 图像预测
7.1 Park_test
7.1.1 img_test()
现在我们就要使用模型对图片进行预测了,参数都为上面的返回值
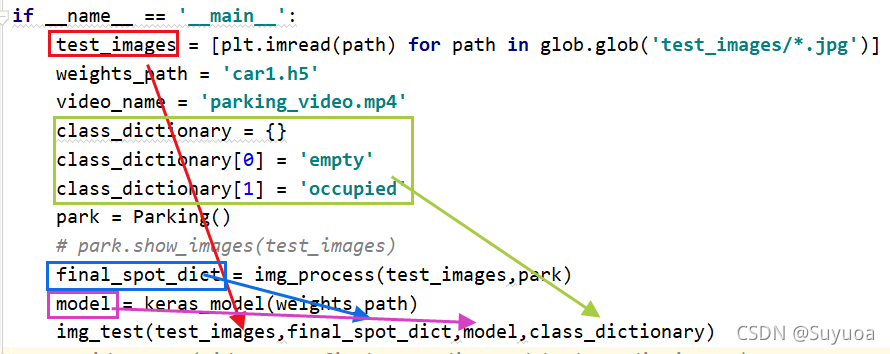
由于要对两张图片分别进行预测,我们我们搞一个for循环

进入循环后使用工具类中的predict_on_image(),与上面参数不同的是predict_on_image()只接收单张图像
7.2 Parking
7.2.1 predict_on_image()
这个也比较长,不整体展示了
先看参数
- image 单张图像
- spot_dict 车位点集
- model 模型
- class_dictionary 分类
- make_copy 是否复制
- color 颜色
- alpha 权重,下面做图像融合用的
![]()
进入方法后先复制两张图片

这两张内容相同,地址不同
定义两个整形变量,初始值为0

之后遍历点集的所有值,进入循环后all_spots自加,然后提出每个点的内容,之后取整,然后裁剪,之后把照片大小变为48*48,然后调用自身的make_prediction()

7.2.2 make_prediction()

进入方法后对图像进行归一化,然后使用np.expand_dims扩展数组形状,只有对图像及逆行扩展我们才能使用模型进行预测,我们下面做一个np.expand_dims的例子
import numpy as np
a = np.array([[1,2],[3,4]])
print(a)
print(a.shape)
print(type(a))
print()
c = np.expand_dims(a,axis=0)
print(c)
print(c.shape)
print(type(c))
print()
c = np.expand_dims(a,axis=1)
print(c)
print(c.shape)
print(type(c))
如果axis=0,那么我在0的位置上加一个维度,如果axis=1,那么我就在1的位置上加一个维度,也可以往后加数,同理
项目中我们使用np.expand_dims就是在0的位置给图像加上一个维度
![]()
之后我们就对增维的图像做预测了,我们把每一步的结果显示出来

由于我们是二分类问题,所以我们会获得两个值,第一个值是这个图是空着的概率,第二个值是这个值被被占用的概率,我们取这两个值的对大值的索引,然后把这个索引套到class_dictionary,就会的出来我们相应的标签,然后返回这个标签

7.2.3 predict_on_image()
此时我们回到predict_on_image(),现在我们获取了每个车位的情况(label)
如果我们识别到这个车位是空的,就在overlay这张图上画上空车位对应的矩形框,然后cnt_empty(空车位数量)+1

之后我们将画框的和没画框的图融合一下,比例0.5,0.6
![]()
然后把字写上,分别是可用的车位(空车位数量)与全部车位数量

之后我们在这将是否保存设置为不保存了,但是无论是否保存都会展示并返回已经画完框,写完字的图片

到此我们的predict_on_image()就结束了,我们看一下效果

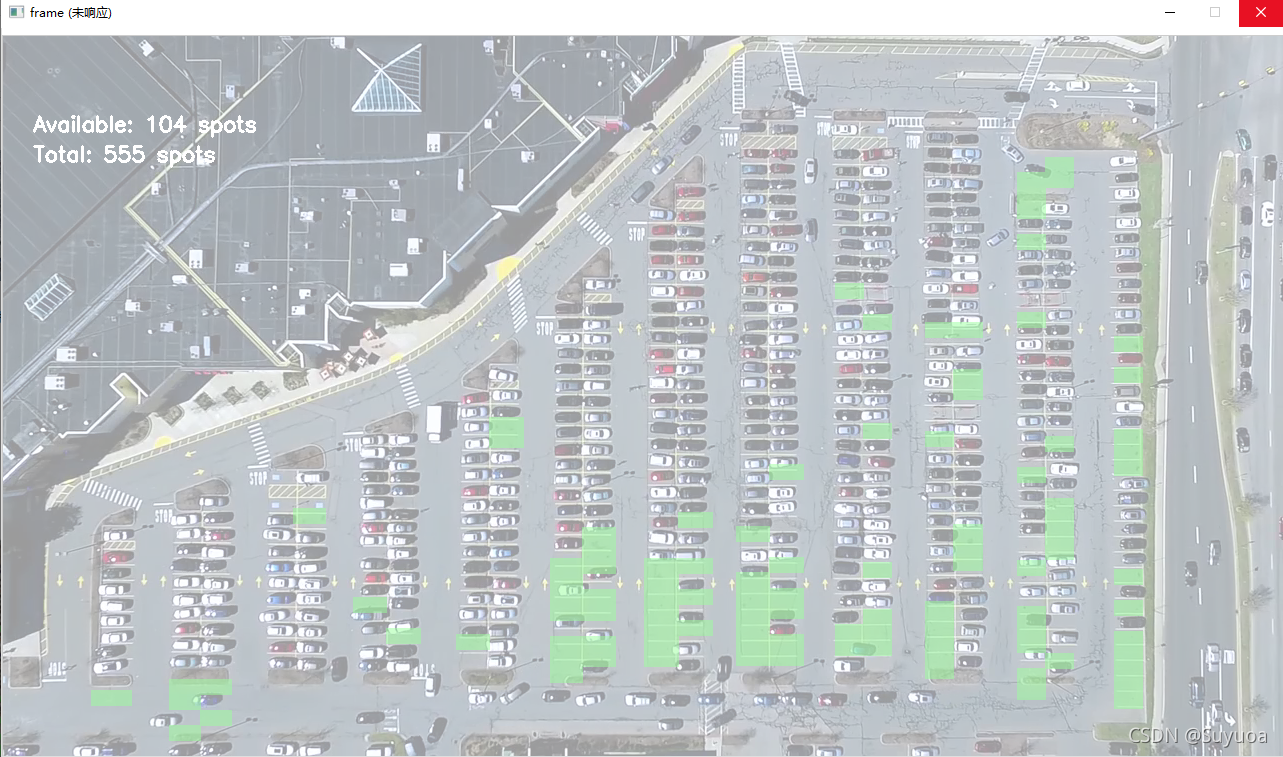
8 视频预测
8.1 Park_test
8.1.1 video_test()
使用video_test方法,与图片预测的方法参数不同的是把图片换成了视频
![]()

8.2 Parking
8.2.1 predict_on_video()
这个和预测图片相似,我们简单过一下
确认视频,定义参数

大循环,读图像,定义参数,复制图像

对每一个车位进行判定

- 这个也正是我们卡的原因,我们算1s60帧,一共555个车位,也就是说我们1s要预测33,300张图片
融合图像,写字,关视频

9 项目总结
9.1 流程图
我们就以检测图像做图了,因为视频与图像处理方式相同,我们花时间最多的是图像预处理,我们梳理一下图像预处理中每个函数的功能
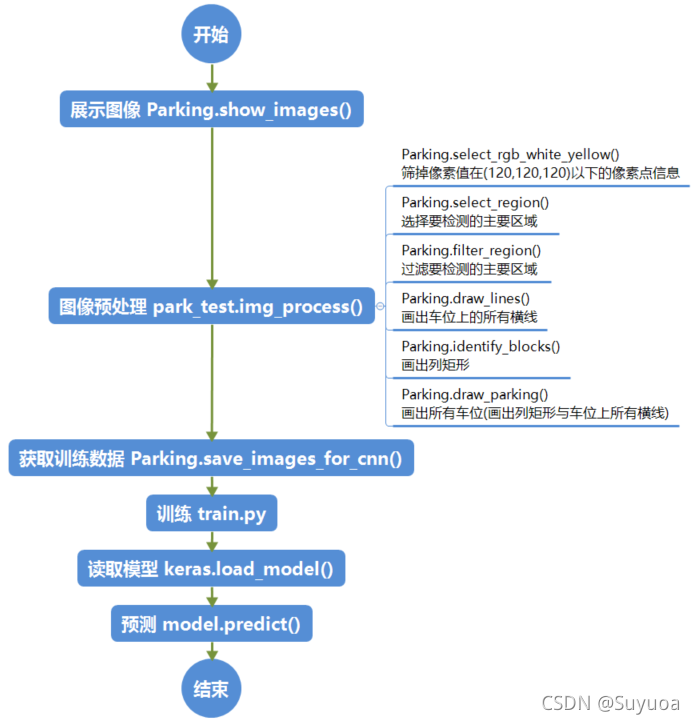
9.2 新了解的方法
- pickle 一共两个方法
- pickle.dump() 存储数据
- pickle.load() 读取数据,这个我们在这个项目中没用到
- np.expand_dims 扩展数组维度