All database users know about regular aggregate functions which operate on an entire table and are used with a GROUP BY clause. But very few people use Window functions in SQL. These operate on a set of rows and return a single aggregated value for each row.
所有数据库用户都知道在整个表上运行并与GROUP BY子句一起使用的常规聚合函数。 但是很少有人在SQL中使用Window函数。 它们对一组行进行操作,并为每行返回一个汇总值。
The main advantage of using Window functions over regular aggregate functions is: Window functions do not cause rows to become grouped into a single output row, the rows retain their separate identities and an aggregated value will be added to each row.
与常规的聚合函数相比,使用Window函数的主要优点是:窗口函数不会导致行被分组为单个输出行,各行保留其各自的标识,并且将聚合值添加到每一行。
Let’s take a look at how Window functions work and then see a few examples of using it in practice to be sure that things are clear and also how the SQL and output compare to that for SUM() functions.
让我们看一下Window函数的工作原理,然后看一些在实际中使用它的示例,以确保一切都清楚,以及SQL和输出与SUM()函数的比较。
As always be sure that you are fully backed up, especially if you are trying out new things with your database.
一如既往,请确保已完全备份,尤其是在尝试使用数据库进行新操作时。
窗口功能介绍 (Introduction to Window functions)
Window functions operate on a set of rows and return a single aggregated value for each row. The term Window describes the set of rows in the database on which the function will operate.
窗口函数对一组行进行操作,并为每行返回一个汇总值。 术语窗口描述了该功能将在其上运行的数据库中的行集。
We define the Window (set of rows on which functions operates) using an OVER() clause. We will discuss more about the OVER() clause in the article below.
我们使用OVER()子句定义Window(函数在其上运行的行的集合)。 我们将在下面的文章中讨论有关OVER()子句的更多信息。
窗口功能的类型 (Types of Window functions)
SUM(), MAX(), MIN(), AVG(). COUNT()
SUM(),MAX(),MIN(),AVG()。 计数()
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
RANK(),DENSE_RANK(),ROW_NUMBER(),NTILE()
LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
LAG(),LEAD(),FIRST_VALUE(),LAST_VALUE()
句法 (Syntax)
window_function ( [ ALL ] expression )
OVER ( [ PARTITION BY partition_list ] [ ORDER BY order_list] )
争论 (Arguments)
window_function
Specify the name of the window function
window_function
指定窗口功能的名称
ALL
ALL is an optional keyword. When you will include ALL it will count all values including duplicate ones. DISTINCT is not supported in window functions
所有
ALL是可选关键字。 当包含ALL时,它将计算所有值,包括重复的值。 窗口功能不支持DISTINCT
expression
The target column or expression that the functions operates on. In other words, the name of the column for which we need an aggregated value. For example, a column containing order amount so that we can see total orders received.
表达
函数所作用的目标列或表达式。 换句话说,我们需要一个汇总值的列的名称。 例如,包含订单金额的列,以便我们可以查看已收到的总订单。
OVER
Specifies the window clauses for aggregate functions.
过度
指定聚合函数的窗口子句。
PARTITION BY partition_list
Defines the window (set of rows on which window function operates) for window functions. We need to provide a field or list of fields for the partition after PARTITION BY clause. Multiple fields need be separated by a comma as usual. If PARTITION BY is not specified, grouping will be done on entire table and values will be aggregated accordingly.
PARTITION BY partition_list
定义窗口功能的窗口(窗口功能在其上运行的行的集合)。 我们需要在PARTITION BY子句之后提供分区的字段或字段列表。 多个字段通常需要用逗号分隔。 如果未指定PARTITION BY,则将对整个表进行分组,并且值将相应地汇总。
ORDER BY order_list
Sorts the rows within each partition. If ORDER BY is not specified, ORDER BY uses the entire table.
ORDER BY order_list
对每个分区中的行进行排序。 如果未指定ORDER BY,则ORDER BY使用整个表。
例子 (Examples)
Let’s create table and insert dummy records to write further queries. Run below code.
让我们创建表并插入虚拟记录以编写进一步的查询。 运行以下代码。
CREATE TABLE [dbo].[Orders]
(
order_id INT,
order_date DATE,
customer_name VARCHAR(250),
city VARCHAR(100),
order_amount MONEY
)
INSERT INTO [dbo].[Orders]
SELECT '1001','04/01/2017','David Smith','GuildFord',10000
UNION ALL
SELECT '1002','04/02/2017','David Jones','Arlington',20000
UNION ALL
SELECT '1003','04/03/2017','John Smith','Shalford',5000
UNION ALL
SELECT '1004','04/04/2017','Michael Smith','GuildFord',15000
UNION ALL
SELECT '1005','04/05/2017','David Williams','Shalford',7000
UNION ALL
SELECT '1006','04/06/2017','Paum Smith','GuildFord',25000
UNION ALL
SELECT '1007','04/10/2017','Andrew Smith','Arlington',15000
UNION ALL
SELECT '1008','04/11/2017','David Brown','Arlington',2000
UNION ALL
SELECT '1009','04/20/2017','Robert Smith','Shalford',1000
UNION ALL
SELECT '1010','04/25/2017','Peter Smith','GuildFord',500
汇总窗口功能 (Aggregate Window Functions)
SUM()
和()
We all know the SUM() aggregate function. It does the sum of specified field for specified group (like city, state, country etc.) or for the entire table if group is not specified. We will see what will be the output of regular SUM() aggregate function and window SUM() aggregate function.
我们都知道SUM()聚合函数。 它为指定的组(例如城市,州,国家/地区等)或整个表(如果未指定组)执行指定字段的总和。 我们将看到常规SUM()聚合函数和窗口SUM()聚合函数的输出。
The following is an example of a regular SUM() aggregate function. It sums the order amount for each city.
以下是常规SUM()聚合函数的示例。 它汇总了每个城市的订单金额。
You can see from the result set that a regular aggregate function groups multiple rows into a single output row, which causes individual rows to lose their identity.
从结果集中可以看到,常规的聚合函数将多行分组为一个输出行,这会导致各个行失去其标识。
SELECT city, SUM(order_amount) total_order_amount
FROM [dbo].[Orders] GROUP BY city
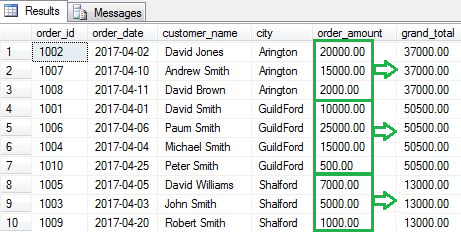
This does not happen with window aggregate functions. Rows retain their identity and also show an aggregated value for each row. In the example below the query does the same thing, namely it aggregates the data for each city and shows the sum of total order amount for each of them. However, the query now inserts another column for the total order amount so that each row retains its identity. The column marked grand_total is the new column in the example below.
窗口聚合函数不会发生这种情况。 行保留其身份,并且还显示每行的汇总值。 在下面的示例中,查询执行相同的操作,即汇总每个城市的数据并显示每个城市的总订单金额之和。 但是,查询现在为总订单金额插入另一列,以便每一行保留其标识。 在下面的示例中,标记为grand_total的列是新列。
SELECT order_id, order_date, customer_name, city, order_amount
,SUM(order_amount) OVER(PARTITION BY city) as grand_total
FROM [dbo].[Orders]
AVG()
AVG()
AVG or Average works in exactly the same way with a Window function.
AVG或平均值与窗口功能的工作方式完全相同。
The following query will give you average order amount for each city and for each month (although for simplicity we’ve only used data in one month).
以下查询将为您提供每个城市和每个月的平均订单金额(尽管为简单起见,我们仅使用一个月的数据)。
We specify more than one average by specifying multiple fields in the partition list.
我们通过在分区列表中指定多个字段来指定多个平均值。
It is also worth noting that that you can use expressions in the lists like MONTH(order_date) as shown in below query. As ever you can make these expressions as complex as you want so long as the syntax is correct!
还值得注意的是,您可以在列表中使用诸如MONTH(order_date)之类的表达式,如下面的查询所示。 只要语法正确,您就可以像以往一样使这些表达式变得复杂!
SELECT order_id, order_date, customer_name, city, order_amount
,AVG(order_amount) OVER(PARTITION BY city, MONTH(order_date)) as average_order_amount
FROM [dbo].[Orders]
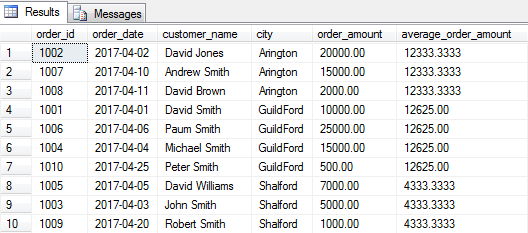
From the above image, we can clearly see that on an average we have received orders of 12,333 for Arlington city for April, 2017.
从上图可以清楚地看到,2017年4月,我们平均收到阿灵顿市的订单12,333。
Average Order Amount = Total Order Amount / Total Orders
= (20,000 + 15,000 + 2,000) / 3
= 12,333
平均订单金额=总订单金额/总订单
=(20,000 + 15,000 + 2,000)/ 3
= 12,333
You can also use the combination of SUM() & COUNT() function to calculate an average.
您还可以结合使用SUM()和COUNT()函数来计算平均值。
MIN()
MIN()
The MIN() aggregate function will find the minimum value for a specified group or for the entire table if group is not specified.
如果未指定组,则MIN()聚合函数将查找指定组或整个表的最小值。
For example, we are looking for the smallest order (minimum order) for each city we would use the following query.
例如,我们在寻找每个城市的最小订单(最小订单),我们将使用以下查询。
SELECT order_id, order_date, customer_name, city, order_amount
,MIN(order_amount) OVER(PARTITION BY city) as minimum_order_amount
FROM [dbo].[Orders]
MAX()
MAX()
Just as the MIN() functions gives you the minimum value, the MAX() function will identify the largest value of a specified field for a specified group of rows or for the entire table if a group is not specified.
正如MIN()函数为您提供最小值一样,MAX()函数将为指定的行组或整个表(如果未指定组)标识指定字段的最大值。
let’s find the biggest order (maximum order amount) for each city.
让我们找到每个城市的最大订单(最大订单量)。
SELECT order_id, order_date, customer_name, city, order_amount
,MAX(order_amount) OVER(PARTITION BY city) as maximum_order_amount
FROM [dbo].[Orders]
COUNT()
计数()
The COUNT() function will count the records / rows.
COUNT()函数将对记录/行进行计数。
Note that DISTINCT is not supported with window COUNT() function whereas it is supported for the regular COUNT() function. DISTINCT helps you to find the distinct values of a specified field.
请注意,窗口COUNT()函数不支持DISTINCT,而常规COUNT()函数则支持DISTINCT。 DISTINCT可帮助您查找指定字段的不同值。
For example, if we want to see how many customers have placed an order in April 2017, we cannot directly count all customers. It is possible that the same customer has placed multiple orders in the same month.
例如,如果我们想查看在2017年4月有多少客户下订单,则无法直接计算所有客户。 同一位客户可能在同一个月下了多个订单。
COUNT(customer_name) will give you an incorrect result as it will count duplicates. Whereas COUNT(DISTINCT customer_name) will give you the correct result as it counts each unique customer only once.
COUNT(customer_name)会给您不正确的结果,因为它将计算重复项。 COUNT(DISTINCT customer_name)将为您提供正确的结果,因为它只对每个唯一客户计数一次。
Valid for regular COUNT() function:
对常规COUNT()函数有效:
SELECT city,COUNT(DISTINCT customer_name) number_of_customers
FROM [dbo].[Orders]
GROUP BY city
Invalid for window COUNT() function:
对于窗口COUNT()函数无效:
SELECT order_id, order_date, customer_name, city, order_amount
,COUNT(DISTINCT customer_name) OVER(PARTITION BY city) as number_of_customers
FROM [dbo].[Orders]
The above query with Window function will give you below error.
上面带有Window函数的查询将给您以下错误。
Now, let’s find the total order received for each city using window COUNT() function.
现在,让我们使用窗口COUNT()函数查找每个城市收到的总订单。
SELECT order_id, order_date, customer_name, city, order_amount
,COUNT(order_id) OVER(PARTITION BY city) as total_orders
FROM [dbo].[Orders]
排名窗口功能 (Ranking Window Functions )
Just as Window aggregate functions aggregate the value of a specified field, RANKING functions will rank the values of a specified field and categorize them according to their rank.
就像Window聚合函数聚合指定字段的值一样,RANKING函数也会对指定字段的值进行排名,并根据它们的排名对其进行分类。
The most common use of RANKING functions is to find the top (N) records based on a certain value. For example, Top 10 highest paid employees, Top 10 ranked students, Top 50 largest orders etc.
RANKING函数最常见的用法是根据特定值查找前(N)个记录。 例如,排名前10位的高薪员工,排名前10位的学生,排名前50位的最大订单等。
The following are supported RANKING functions:
以下是受支持的RANKING函数:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE() RANK(),DENSE_RANK(),ROW_NUMBER(),NTILE()Let’s discuss them one by one.
让我们一一讨论。
RANK()
秩()
The RANK() function is used to give a unique rank to each record based on a specified value, for example salary, order amount etc.
RANK()函数用于基于指定的值(例如薪水,订单金额等)为每个记录赋予唯一的排名。
If two records have the same value then the RANK() function will assign the same rank to both records by skipping the next rank. This means – if there are two identical values at rank 2, it will assign the same rank 2 to both records and then skip rank 3 and assign rank 4 to the next record.
如果两个记录具有相同的值,则RANK()函数将通过跳过下一个等级来为两个记录分配相同的等级。 这意味着–如果在等级2上有两个相同的值,它将为两个记录分配相同的等级2,然后跳过等级3并将等级4分配给下一个记录。
Let’s rank each order by their order amount.
让我们按订单数量对每个订单进行排名。
SELECT order_id,order_date,customer_name,city,
RANK() OVER(ORDER BY order_amount DESC) [Rank]
FROM [dbo].[Orders]
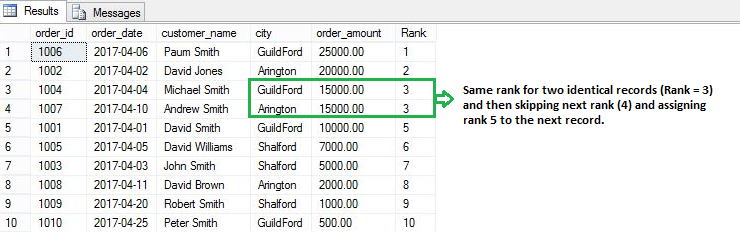
From the above image, you can see that the same rank (3) is assigned to two identical records (each having an order amount of 15,000) and it then skips the next rank (4) and assign rank 5 to next record.
从上面的图像中,您可以看到将相同的等级(3)分配给两个相同的记录(每个订单的订单量为15,000),然后跳过下一个等级(4)并将等级5分配给下一个记录。
DENSE_RANK()
DENSE_RANK()
The DENSE_RANK() function is identical to the RANK() function except that it does not skip any rank. This means that if two identical records are found then DENSE_RANK() will assign the same rank to both records but not skip then skip the next rank.
DENSE_RANK()函数与RANK()函数相同,只是它不跳过任何等级。 这意味着,如果找到两个相同的记录,则DENSE_RANK()将为两个记录分配相同的等级,但不会跳过然后跳过下一个等级。
Let’s see how this works in practice.
让我们看看这在实践中是如何工作的。
SELECT order_id,order_date,customer_name,city, order_amount,
DENSE_RANK() OVER(ORDER BY order_amount DESC) [Rank]
FROM [dbo].[Orders]
As you can clearly see above, the same rank is given to two identical records (each having the same order amount) and then the next rank number is given to the next record without skipping a rank value.
从上面您可以清楚地看到,相同的排名被赋予两个相同的记录(每个具有相同的订购量),然后下一个排名编号被赋予下一个记录,而不会跳过排名值。
ROW_NUMBER()
ROW_NUMBER()
The name is self-explanatory. These functions assign a unique row number to each record.
这个名字是不言而喻的。 这些函数为每个记录分配唯一的行号。
The row number will be reset for each partition if PARTITION BY is specified. Let’s see how ROW_NUMBER() works without PARTITION BY and then with PARTITION BY.
如果指定了PARTITION BY,则将为每个分区重置行号。 让我们看看ROW_NUMBER()如何在没有PARTITION BY的情况下,然后再与PARTITION BY一起工作。
ROW_ NUMBER() without PARTITION BY
ROW_ NUMBER()无PARTITION BY
SELECT order_id,order_date,customer_name,city, order_amount,
ROW_NUMBER() OVER(ORDER BY order_id) [row_number]
FROM [dbo].[Orders]
ROW_NUMBER() with PARTITION BY
ROW_NUMBER(),PARTITION BY
SELECT order_id,order_date,customer_name,city, order_amount,
ROW_NUMBER() OVER(PARTITION BY city ORDER BY order_amount DESC) [row_number]
FROM [dbo].[Orders]
Note that we have done the partition on city. This means that the row number is reset for each city and so restarts at 1 again. However, the order of the rows is determined by order amount so that for any given city the largest order amount will be the first row and so assigned row number 1.
请注意,我们已经在city上完成了分区。 这意味着将为每个城市重置行号,因此将从1重新开始。 但是,行的顺序由订单量确定,因此对于任何给定的城市,最大的订单量将是第一行,因此分配的行号为1。
NTILE()
NTILE()
NTILE() is a very helpful window function. It helps you to identify what percentile (or quartile, or any other subdivision) a given row falls into.
NTILE()是一个非常有用的窗口函数。 它可以帮助您确定给定行属于哪个百分位(或四分位数,或任何其他细分)。
This means that if you have 100 rows and you want to create 4 quartiles based on a specified value field you can do so easily and see how many rows fall into each quartile.
这意味着如果您有100行,并且要基于指定的值字段创建4个四分位数,则可以轻松地进行操作,并查看每个四分位数中有多少行。
Let’s see an example. In the query below, we have specified that we want to create four quartiles based on order amount. We then want to see how many orders fall into each quartile.
让我们来看一个例子。 在下面的查询中,我们指定了要基于订单金额创建四个四分位数。 然后,我们要查看每个四分位数中有多少个订单。
SELECT order_id,order_date,customer_name,city, order_amount,
NTILE(4) OVER(ORDER BY order_amount) [row_number]
FROM [dbo].[Orders]
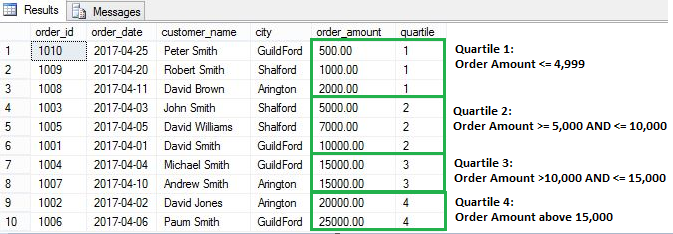
NTILE creates tiles based on following formula:
NTILE根据以下公式创建图块:
No of rows in each tile = number of rows in result set / number of tiles specified
每个图块中的行数=结果集中的行数/指定的图块数
Here is our example, we have total 10 rows and 4 tiles are specified in the query so number of rows in each tile will be 2.5 (10/4). As number of rows should be whole number, not a decimal. SQL engine will assign 3 rows for first two groups and 2 rows for remaining two groups.
这是我们的示例,总共有10行,并且在查询中指定了4个图块,因此每个图块中的行数将为2.5(10/4)。 因为行数应该是整数,而不是小数。 SQL引擎将为前两组分配3行,为其余两组分配2行。
价值窗口功能 (Value Window Functions )
Value window functions are used to find first, last, previous and next values. The functions that can be used are LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
值窗口函数用于查找第一个,最后一个,上一个和下一个值。 可以使用的函数是LAG(),LEAD(),FIRST_VALUE(),LAST_VALUE()
LAG() and LEAD()
LAG()和LEAD()
LEAD() and LAG() functions are very powerful but can be complex to explain.
LEAD()和LAG()函数非常强大,但解释起来可能很复杂。
As this is an introductory article below we are looking at a very simple example to illustrate how to use them.
由于这是下面的介绍性文章,我们正在看一个非常简单的示例来说明如何使用它们。
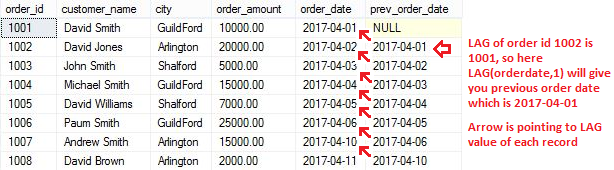
The LAG function allows to access data from the previous row in the same result set without use of any SQL joins. You can see in below example, using LAG function we found previous order date.
LAG函数允许访问同一结果集中的前一行数据,而无需使用任何SQL连接。 您可以在下面的示例中看到,我们使用LAG函数找到了先前的订购日期。
Script to find previous order date using LAG() function:
使用LAG()函数查找先前订单日期的脚本:
SELECT order_id,customer_name,city, order_amount,order_date,
--in below line, 1 indicates check for previous row of the current row
LAG(order_date,1) OVER(ORDER BY order_date) prev_order_date
FROM [dbo].[Orders]
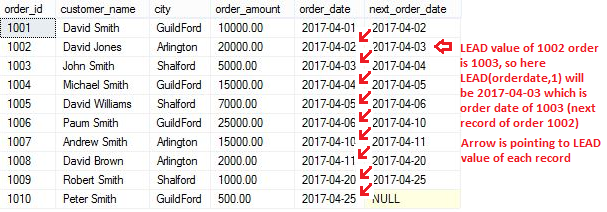
LEAD function allows to access data from the next row in the same result set without use of any SQL joins. You can see in below example, using LEAD function we found next order date.
LEAD函数允许访问同一结果集中的下一行数据,而无需使用任何SQL连接。 您可以在下面的示例中看到,我们使用LEAD函数找到了下一个订单日期。
Script to find next order date using LEAD() function:
使用LEAD()函数查找下一个订单日期的脚本:
SELECT order_id,customer_name,city, order_amount,order_date,
--in below line, 1 indicates check for next row of the current row
LEAD(order_date,1) OVER(ORDER BY order_date) next_order_date
FROM [dbo].[Orders]
FIRST_VALUE() and LAST_VALUE()
FIRST_VALUE()和LAST_VALUE()
These functions help you to identify first and last record within a partition or entire table if PARTITION BY is not specified.
如果未指定PARTITION BY,则这些函数可帮助您识别分区或整个表中的第一条记录和最后一条记录。
Let’s find the first and last order of each city from our existing dataset. Note ORDER BY clause is mandatory for FIRST_VALUE() and LAST_VALUE() functions
让我们从现有数据集中找到每个城市的第一和最后顺序。 注意ORDER BY子句对于FIRST_VALUE()和LAST_VALUE()函数是必需的
SELECT order_id,order_date,customer_name,city, order_amount,
FIRST_VALUE(order_date) OVER(PARTITION BY city ORDER BY city) first_order_date,
LAST_VALUE(order_date) OVER(PARTITION BY city ORDER BY city) last_order_date
FROM [dbo].[Orders]
From the above image, we can clearly see that first order received on 2017-04-02 and last order received on 2017-04-11 for Arlington city and it works the same for other cities.
从上面的图像中,我们可以清楚地看到阿灵顿市于2017-04-02收到的第一笔订单和2017-04-11所收到的最后订单,其他城市也一样。
有用的链接 (Useful Links)
- Backup Types & Strategies for SQL Databases SQL数据库的备份类型和策略
- TechNet Article on the OVER Clause TechNet关于OVER条款的文章
- MSDN Article On DENSE_RANK MSDN文章DENSE_RANK
本的其他精彩文章 (Other great articles from Ben)
| How SQL Server selects a deadlock victim |
| How To Use Window Functions |
| SQL Server如何选择死锁受害者 |
| 如何使用视窗功能 |
翻译自: https://www.sqlshack.com/use-window-functions-sql-server/