全文检索
数据分类:
- 结构化数据: 固定格式,有限长度 比如mysql存的数据
- 非结构化数据:不定长,无固定格式 比如邮件,word文档,日志
- 半结构化数据: 前两者结合 比如xml,html
搜索分类:
- 结构化数据搜索:使用关系型数据库
- 非结构化数据搜索
顺序扫描
全文检索
什么是全文检索
全文检索是指: 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
搜索原理简单概括的话可以分为这么几步:
- 内容爬取,停顿词过滤比如一些无用的像"的",“了”之类的语气词/连接词
- 内容分词,提取关键词
- 根据关键词建立倒排索引
- 用户输入关键词进行搜索
倒排索引(反向索引)
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键。
简单理解,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时底层使用的就是倒排索引。
Elasticsearch 的倒排索引
正排索引是以文档的 ID 为关键字,表中记录文档中每个字的位置信息,查找时扫描表 中每个文档中字的信息直到找出所有包含查询关键字的文档。
倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。
有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。
所以总的来说,正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)
ElasticSearch简介
ElasticSearch(简称ES)是一个分布式、RESTful 风格的搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
官方网站: https://www.elastic.co/
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
搜索排名参考网站:https://db-engines.com/en/ranking/search+engine
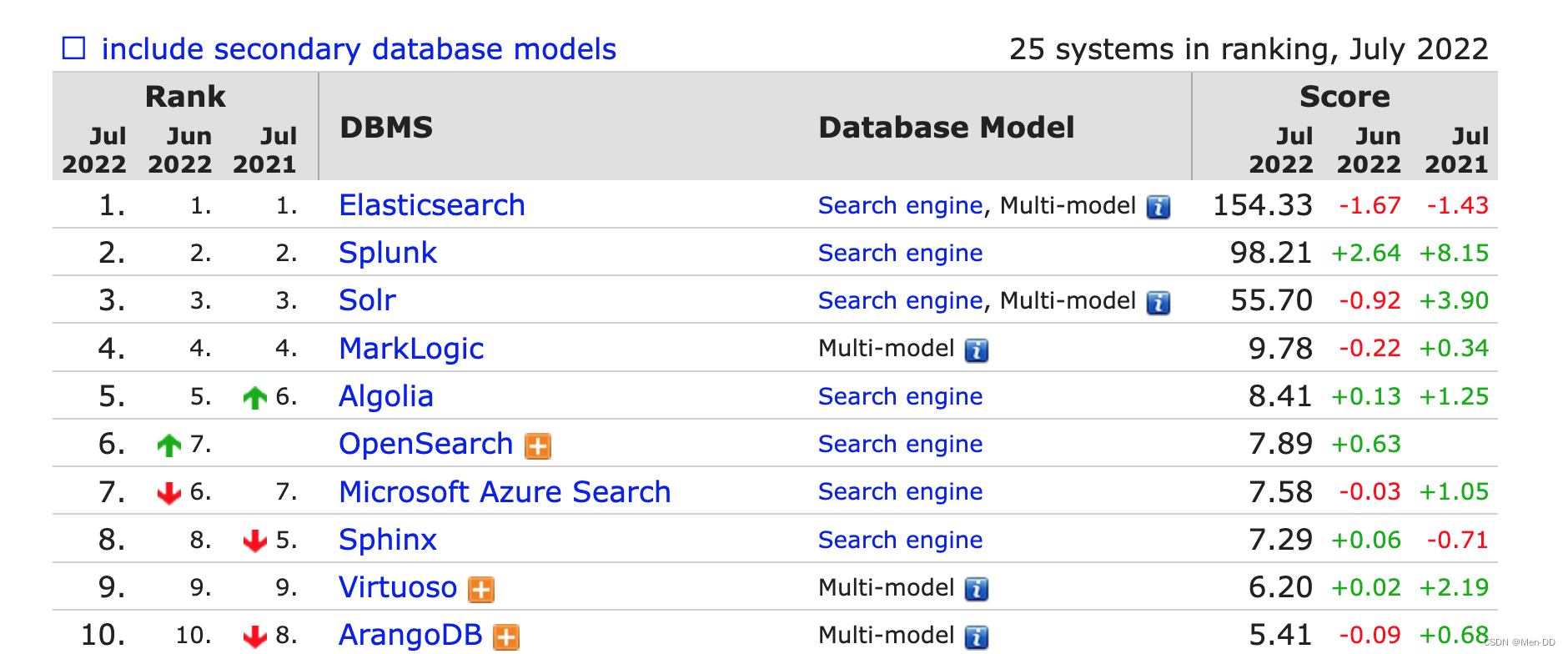
ElasticSearch版本特性
5.x新特性
- Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
- 支持Ingest节点/ Painless Scripting / Completion suggested支持/原生的Java REST客户端
- Type标记成deprecated, 支持了Keyword的类型
- 性能优化
内部引擎移除了避免同一文档并发更新的竞争锁,带来15% - 20%的性能提升
Instant aggregation,支持分片,上聚合的缓存
新增了Profile API
6.x新特性
- Lucene 7.x
- 新功能
跨集群复制(CCR)
索引生命周期管理
SQL的支持 - 更友好的的升级及数据迁移
在主要版本之间的迁移更为简化,体验升级
全新的基于操作的数据复制框架,可加快恢复数据 - 性能优化
有效存储稀疏字段的新方法,降低了存储成本
在索引时进行排序,可加快排序的查询性能
7.x新特性
- Lucene 8.0
- 重大改进-正式废除单个索引下多Type的支持
- 7.1开始,Security 功能免费使用
- ECK - Elasticseach Operator on Kubernetes
- 新功能
New Cluster coordination
Feature——Complete High Level REST Client
Script Score Query - 性能优化
默认的Primary Shard数从5改为1,避免Over Sharding
性能优化, 更快的Top K
8.x新特性
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type)
- 默认开启安全配置
- 存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text、text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效。
- 优化geo_point,geo_shape类型的索引(写入)效率:15%的提升。
- 技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关。
https://www.elastic.co/guide/en/elastic-stack/current/elasticsearch-breaking-changes.html
Elasticsearch vs Lucene
- Elasticsearch 完美封装了 Lucene 核心库,设计了友好的 Restful-API,开发者无需过多关注底层机制,直接开箱即用
- 分片与副本机制,直接解决了集群下性能与高可用问题。
- ES Server进程 3节点 raft (奇数节点)
- 数据分片 -》lucene实例分片和副本数 1个ES节点可以有多个lucene实例。也可以指定一个索引的多个分片
ElasticSearch vs Solr
Solr 是第一个基于 Lucene 核心库功能完备的搜索引擎产品,诞生远早于 Elasticsearch。
当单纯的对已有数据进行搜索时,Solr更快。当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
总结:
- Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
- Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
Elastic Stack介绍
在Elastic Stack之前我们听说过ELK,ELK分别是Elasticsearch,Logstash,Kibana这三款软件在一起的简称,在发展的过程中又有新的成员Beats的加入,就形成了Elastic Stack
ElasticSearch安装运行
下载并解压ElasticSearch
下载地址: https://www.elastic.co/cn/downloads/past-releases#elasticsearch
环境准备
运行Elasticsearch,需安装并配置JDK
设置$JAVA_HOME
各个版本对Java的依赖 https://www.elastic.co/support/matrix#matrix_jvm
Elasticsearch 从 5 需要Java 8以上的版本
Elasticsearch 从 6.5 开始支持Java 11
Elasticsearch 从 7.0 开始,内置了Java环境
Elasticsearch 比较耗内存,建议虚拟机4G或以上内存,jvm1g以上的内存分配
ES的jdk环境生效的优先级配置ES_JAVA_HOME>JAVA_HOME>ES_HOME
ElasticSearch文件目录结构
- bin: 脚本文件,包括启动elasticsearch,安装插件,运行统计数据等
- config: 配置文件目录,如elasticsearch配置、角色配置、jvm配置等
- jdk: java运行环境
- data: 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境需要修改
- lib: elasticsearch依赖的Java类库
- logs: 默认的日志文件存储路径,生产环境需要修改
- modules: 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等
- plugins: 已安装插件目录
主配置文件elasticsearch.yml
cluster.name
当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同。默认值elasticsearch,生产环境建议根据ES集群的使用目的修改成合适的名字。node.name
当前节点名称,默认值当前节点部署所在机器的主机名,所以如果一台机器上要起多个ES节点的话,需要通过配置该属性明确指定不同的节点名称。path.data
配置数据存储目录,比如索引数据等,默认值 $ES_HOME/data,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。path.logs
配置日志存储目录,比如运行日志和集群健康信息等,默认值 $ES_HOME/logs,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。bootstrap.memory_lock
配置ES启动时是否进行内存锁定检查,默认值true。
ES对于内存的需求比较大,一般生产环境建议配置大内存,如果内存不足,容易导致内存交换到磁盘,严重影响ES的性能。所以默认启动时进行相应大小内存的锁定,如果无法锁定则会启动失败。
非生产环境可能机器内存本身就很小,能够供给ES使用的就更小,如果该参数配置为true的话很可能导致无法锁定内存以致ES无法成功启动,此时可以修改为false。network.host
配置能够访问当前节点的主机,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。可以配置为0.0.0.0,表示所有主机均可访问。http.port
配置当前ES节点对外提供服务的http端口,默认值 9200discovery.seed_hosts
配置参与集群节点发现过程的主机列表,说白一点就是集群中所有节点所在的主机列表,可以是具体的IP地址,也可以是可解析的域名。cluster.initial_master_nodes
配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致。ES集群首次构建完成后,应该将集群中所有节点的配置文件中的cluster.initial_master_nodes配置项移除,重启集群或者将新节点加入某个已存在的集群时切记不要设置该配置项。
修改JVM配置
修改config/jvm.options配置文件,调整jvm堆内存大小
vim jvm.options
-Xms4g
-Xmx4g
Xms 和 Xmx 设置成—样
Xmx不要超过机器内存的50%
不要超过30GB - https://www.elastic.co/cn/blog/a-heap-of-trouble
启动ElasticSearch服务
Linux ES不允许使用root账号启动服务,如果你当前账号是root,则需要创建一个专有账户
#为elaticsearch创建用户并赋予相应权限
adduser es
passwd es
chown -R es:es elasticsearch-17.3
#非root用户
bin/elasticsearch
# -d 后台启动
bin/elasticsearch -d
启动ES服务常见错误解决方案
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
vim /etc/security/limits.conf
末尾添加如下配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
改为如下配置
* soft nproc 4096
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者 单节点(集群单节点)
discovery.type: single-node
客户端Kibana安装
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
修改Kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://es.local.com:9200" ]
elasticsearch.username: xxxx
elasticsearch.password: xxxx
i18n.locale: "zh-CN" #Kibana汉化
运行Kibana
kibana也需要非root用户启动
bin/kibana
#后台启动
nohup bin/kibana &
访问Kibana: http://localhost:5601/
cat API
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index} #查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index} #查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息
安装分词器 安装和删除完插件后,需要重启ES服务才能生效
在线安装
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu
离线安装
本地下载相应的插件,解压,然后手动上传到elasticsearch的plugins目录,然后重启ES实例就可以了。
比如ik中文分词插件:https://github.com/medcl/elasticsearch-analysis-ik
测试
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}
创建索引时可以指定IK分词器作为默认分词器
PUT /es_app_products
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
热更新 IK 分词使用方法
https://github.com/medcl/elasticsearch-analysis-ik
{conf}/analysis-ik/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
ElasticSearch基本概念
关系型数据库 VS ElasticSearch
在7.0之前,一个 Index可以设置多个Types
目前Type已经被Deprecated,7.0开始,一个索引只能创建一个Type - '_doc'
传统关系型数据库和Elasticsearch的区别:
- Elasticsearch — Schemaless/相关性/高性能全文检索
- RDMS —-- 事务性 / Join
文档元数据
元数据,用于标注文档的相关信息:
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯—ld
- _source: 文档的原始Json数据
- _version: 文档的版本号,修改删除操作_version都会自增1
- _seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no
- _primary_term: _primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
ElasticSearch索引操作
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index.html