首先,新建一张表用于示例说明:
# 新建一张表A
create table A( id varchar(5), name varchar(5), salary float);
# 插入数据(包含要去除的重复记录)
insert into A VALUES
( '01', 'John', 3800),
('02','Tom',5000),
('02','Tom',10000),
('03','Sam',8600);
得到测试用的表如下: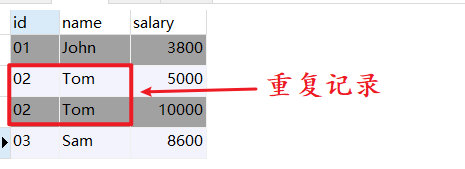
这里,我们定义的重复记录是:只要“name"的字段值重复就认为两条记录是重复的(单字段重复记录)。
----------------------------------------开始去重操作-------------------------------------------
第一种情况:去重所有的重复记录,只保留第一条
去重目标:当"name"的字段值有重复时,只保留第一条记录,删除其余所有重复记录。第一步: 按照‘name"字段分组并对组内每条记录进行编号:
select A.*, row_number() over( partition by name ) 工资排名
from A;

第二步:去重(即筛选出每个name的第一条记录,这样就排除了其他重复记录):
select *
from
(select A.*, row_number() over( partition by name ) 工资排名
from A) t
where 工资排名=1;
结果如下:
第二种情况: 去除指定条件的重复记录,只保留第一行
现在只去除"name"字段中'Tom"对应的重复记录,其他人是否有重复记录不用管。第一步:找出"Tom"的重复记录(按照name字段分组后”Tom"的第一条记录以外的其他记录)
select id,name,salary
from
(select A.*, row_number() over() 记录编号
from A
where name='Tom') t
where 记录编号 !=1;
得到结果如下: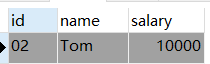
注意: 序号函数(row_number(), dense_rank(),rank())必须结合开窗函数“over()"使用,即使"over()"不带有任何参数(如本部分去重操作)。
第二步: 从原表中排除上一步得到的记录
select *
from A
where
(id,name,salary) NOT IN # 排除操作
(select id,name,salary
from
(select A.*, row_number() over() 记录编号
from A
where name='Tom') t
where 记录编号 !=1);
得到最终结果如下: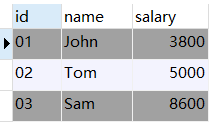
版权声明:本文为grandesucesso原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。