CPU负载均衡之loadavg计算
前言
本文分析关于loadavg 使用、计算相关内容(基于kernel 4.9),如下图: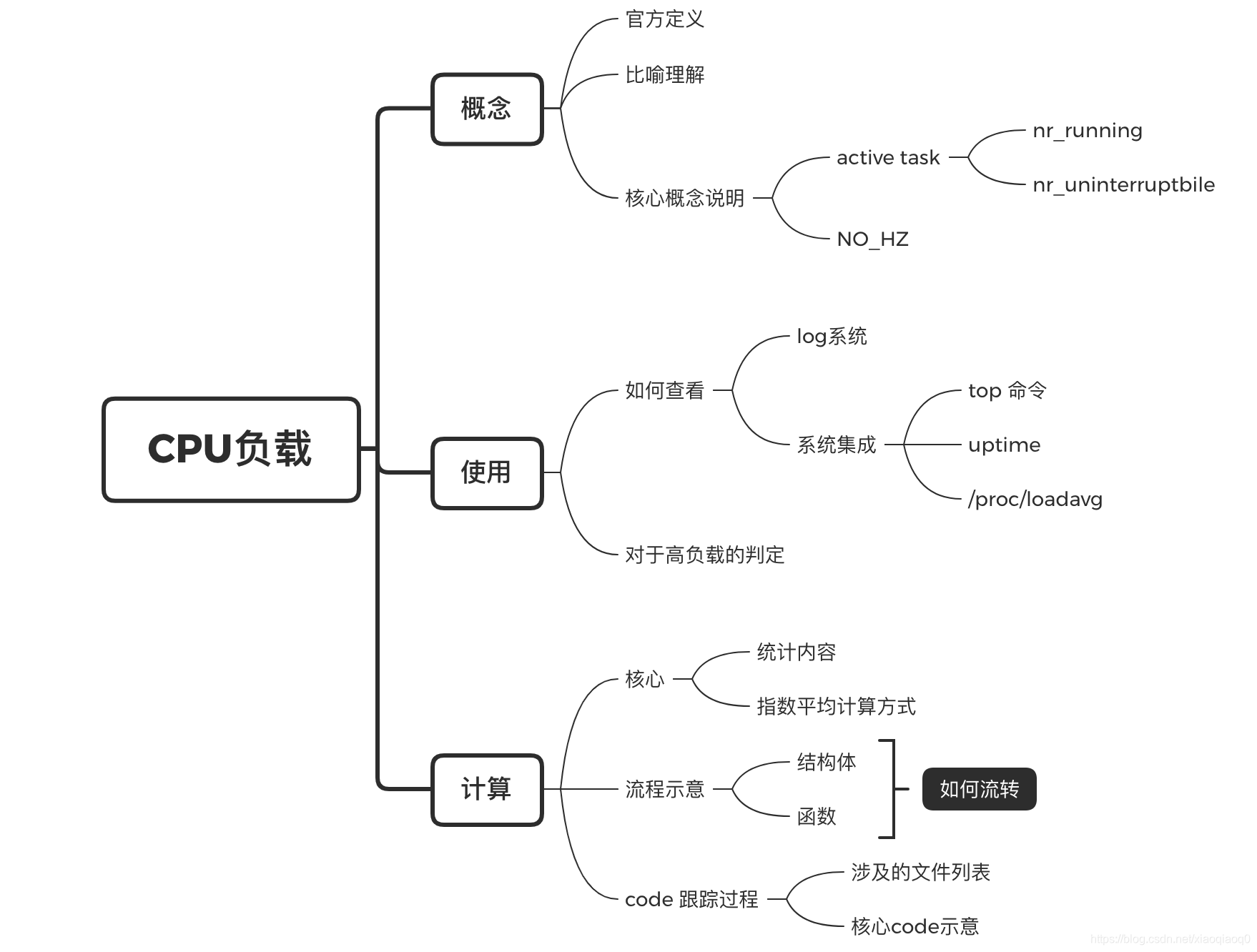
其中重点介绍CPU负载计算过程相关内容(源码网站参考:opengrok 和 bootlin);
文章目录
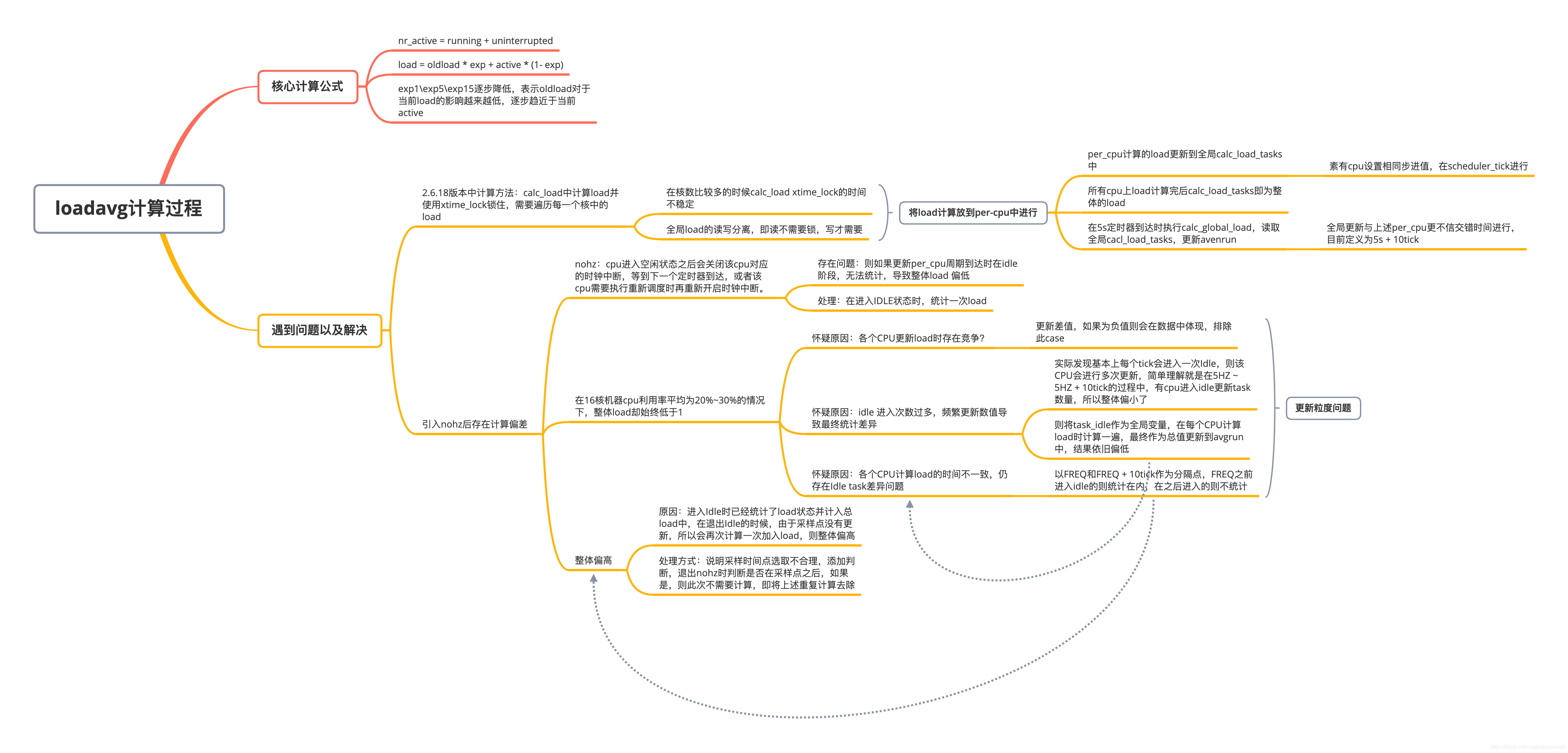
1. CPU负载
负载:当前队列中排队的Task+正在running的Task数量之和与CPU能力的比值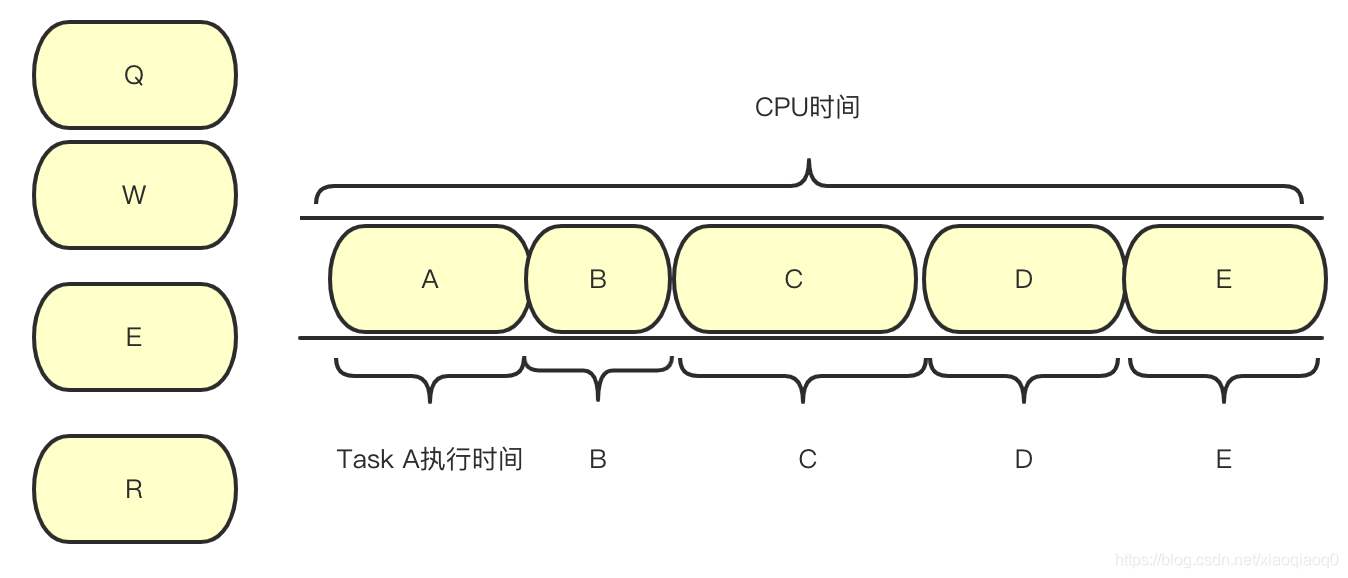
1.1 一个味道很重的比喻
这个概念又一个很形象的比喻:
- 游乐场很好玩,人超多,对应Task;
- 只有一个厕所(也可能有2、3、4个),对应CPU的核数;
- 一旦节假日去到游乐场,就会发现厕所排了很长的队;
这种情况就是满负载了,嗯,有内个味儿了!!!
1.2 核心概念说明
| name | 说明 |
|---|---|
| active task | 对应每个CPU上nr_running和nr_uninterruptible的task,在runqueue结构体中维护 |
| clac_load_tasks | 对应所有CPU中active的task之和 |
| avnrun | sched中提供数组,用于记录和计算1、5、15分钟时的平均负载值,与直观的load显示比值为2048 |
| NO_HZ | kernel中定义的系统频率,倒数即1s的节拍数,每个节拍提供中断用于各类task使用,NO_HZ即在CPU空闲时关闭周期性的中断 |
2. loadavg使用
2.1 查看CPU 负载
- Linux、android的debug系统已经很好的集成了loadavg功能,再出现ANR、SWT等异常时,抓取的log信息中均会有当时loadavg情况;
- 可以通过系统提供命令查看
- cat /proc/loadavg
- uptime
- dumpsys cpuinfo
- top (top中没有显示loadavg)
2.2 CPU负载数据的分析说明
- 三个数值分别代表:1分钟、5分钟、15分钟内的平均负载;
- 一个核满负载为1,一般的4核CPU满负载就是4,也存在只有一个核但是负载为3的情况,这说明CPU成为了block点;
- 可以看到的是统计的最小粒度为1min,其实这个统计主要代表一个趋势性的说明,即偶尔出现满负载并不可怕,如果一直长时间持续,则说明或者系统出现问题或者系统与HW资源不匹配了;
- 按照以往经验,如果负载一直维持在70%以内,那说明系统整体状况还是比较健康的,但是并不说明系统没有问题(可能这70%是异常task造成的)
- DVFS就是根据这个负载情况调节频率和电压的;
3. 负载计算
核心计算步骤如下三步:
计算每个CPU当前活跃task数量:active task = nr_running和nr_uninterruptible
在update的周期到来时,将nr_active更新到全局变量calc_load_tasks中;
根据oldload和当前活跃task计算新负载:newload = load * exp + active * (FIXED_1 - exp);
3.1 流程示意
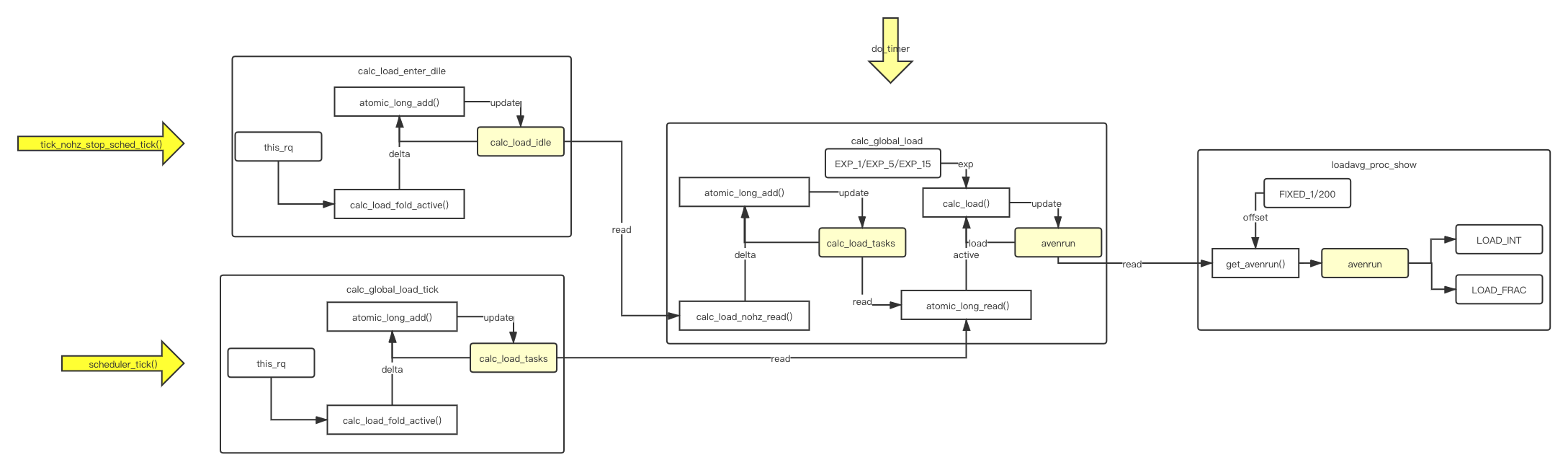
上述图示展示了整个数据更新的过程,如下详细解释说明下:
- 涉及的数据:
active:每个CPU上的运行Task
calc_load_idle:在cpu进入idle时更新此值,避免进入idle后没有中断,在update周期到来时无法更新
calc_load_tasks:全局变量,记录所有Task sum,实际做指数平均的active;
avenrun:每个period计算出来的最终load,/proc/loadavg即读取这个值;
- 更新时机
每次shcedule_tick调用calc_load_fold_active,在到达更新时机(即5s)时获取每个CPU的running和uninterruptible数值,更新每个CPU的active;
每次tick_nohz_stop_sched_tick()进入Idle时调用calc_load_enter_idle获取当前CPU的active更新到calc_load_idle,提供给到之后使用;
每次do_timer调用在到达更新时机(即5s+10tick)时根据calc_load_tasks、EXP(权重)、当前load计算新的load值;
所谓更新时机,可参照这个图: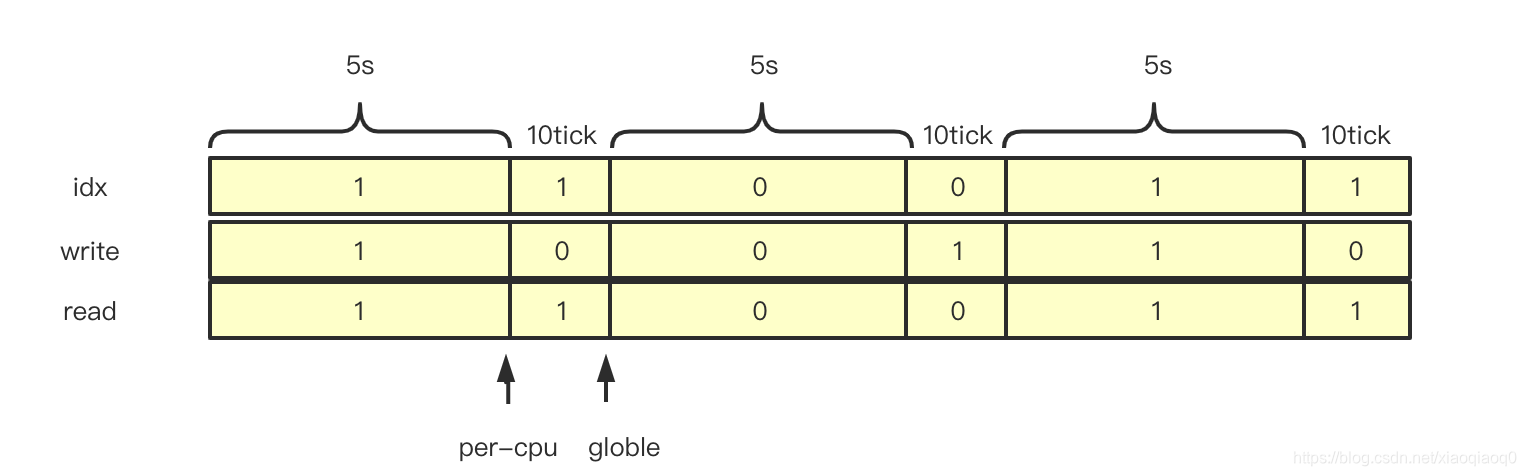
3.2 code跟踪
3.2.1 文件目录:
| id | 路径 |
|---|---|
| 1 | /kernel/fs/proc/loadavg.c |
| 2 | /kernel/kernel/shcedule/loadavg.c |
| 3 | /kernel/sched/sched.h |
| 4 | /kernel/sched/core.c |
| 5 | /kernel/timer/timekeeping.c |
3.2.2 loadavg 显示流程
所有loadavg的使用其实都是基于/proc/loadavg,首先将这里做为入口:
//ps:这里应该是基于5.72的,核心步骤不影响
static int loadavg_proc_show(struct seq_file *m, void *v){
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);//获取avnrun
//写入loadavg,分别计算整数部分和小数部分
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
idr_get_cursor(&task_active_pid_ns(current)->idr) - 1);//这里就是最后last_pid
return 0;
}
static int __init proc_loadavg_init(void){
proc_create_single("loadavg", 0, NULL, loadavg_proc_show);
return 0;}//创建节点,显示内容为loadavg_proc_show
fs_initcall(proc_loadavg_init);//系统启动时fs_initcall中注册init函数
- 在系统启动的时候将proc_loadavg_init启动起来;
- 核心函数为获取avenrun,然后分别计算整数部分和小数部分;
这里需要理解的几个概念:
avnrun,这个是从sched中直接获取过来的,中间经过一个简单转换(添加了10.24)
nr_running 理解为number of runnable task
LOAD_IN 右移11位,即取高位
LOAD_FRAC 取低11位,运算乘100
定义如下:
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
#define LOAD_INT(x) ((x) >> FSHIFT) //计算整数
#define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100)//计算小数
3.2.3 avenrun 计算
- proc下的avenrun数组是从sched下的avenrun经过运算得到的:
void get_avenrun(unsigned long *loads, unsigned long offset, int shift)
{
loads[0] = (avenrun[0] + offset) << shift;
loads[1] = (avenrun[1] + offset) << shift;
loads[2] = (avenrun[2] + offset) << shift;
//则对于运算来说就是添加了一个offset,即2048 / 200 / 2048=0.005 , 负载只取小数点后2位,所以添加了一个类似于四舍五入操作;
}
- 在code中搜索,avenrun数组的计算赋值操作,即每个周期的计算load操作:
- loadavg.c中calc_global_load函数中,完整计算;
则可以很直观的看到avenrun(load average array)是通过calc_load相关函数更新的,此部分为详细计算过程:
- loadavg.c中calc_global_load函数中,完整计算;
/*
* calc_load - update the avenrun load estimates 10 ticks after the
* CPUs have updated calc_load_tasks.
*
* Called from the global timer code.
*/
void calc_global_load(unsigned long ticks)
{
unsigned long sample_window;
long active, delta;
sample_window = READ_ONCE(calc_load_update);
//没到更新时间5s + 10tick 则退出
if (time_before(jiffies, sample_window + 10))
return;
/*
* Fold the 'old' NO_HZ-delta to include all NO_HZ CPUs.
*/
//这里首先会去读取load idle 的值,并将其更新到calc_load_tasks;
delta = calc_load_nohz_read();
if (delta)
atomic_long_add(delta, &calc_load_tasks);
//获取active,实质就是读取calc_load_tasks
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
//根据权重运算avenrun
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
//周期更新;
WRITE_ONCE(calc_load_update, sample_window + LOAD_FREQ);
/*
* In case we went to NO_HZ for multiple LOAD_FREQ intervals
* catch up in bulk.
*/
//这里是用来cover一种情况,存在多个周期(n * 5s)在Idle,则一直没有更新;
calc_global_nohz();
}
/*
* a1 = a0 * e + a * (1 - e)
*/
static inline unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{
unsigned long newload;
//核心计算公式:
newload = load * exp + active * (FIXED_1 - exp);
//如果新增active比之前的完整还多,则newload + 1,体现趋势
if (active >= load)
newload += FIXED_1-1;
return newload / FIXED_1;
}
这里的核心内容就是计算avenrun,即获取到active的和,使用指数平均的公式计算最终的load:
- 确认已经达到了统计时间,默认为5*HZ+10tick
- 获取active数量,直接读取calc_load_tasks(所有增加的和);
- 更新数组内容,通过公式计算:a1 = a0 * e + a * (1 - e) ,则这个公式:
- 分别在1、5、15分钟的条件下历史load的权重是不断增加的,也就是说新增加的active数量对于越久时间的统计影响越小(1884、2014、2037)
- 新增加的active task的影响是慢慢变缓的,即时间越久,整体计算出来的数据越趋向于active_task
3.2.4 计算active
在code中搜索,active的计算赋值操作为:
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
是直接读取的calc_load_tasks,更新这个变量的位置:
- atomic_long_add(delta, &calc_load_tasks),每次scheduler_tick时检测到达更新周期时add;
- delta = calc_load_fold_idle(),进入idle更新到数组中,在do_timer进入global计算时更新;
/*
* Called from scheduler_tick() to periodically update this CPU's
* active count.
*/
void calc_global_load_tick(struct rq *this_rq)
{
long delta;
// now is befor update tick, do nothing
if (time_before(jiffies, this_rq->calc_load_update))
return;
// now is in update tick ,read the per-cpu nr_active
delta = calc_load_fold_active(this_rq, 0);
if (delta)
atomic_long_add(delta, &calc_load_tasks);
//normal update, is rq
this_rq->calc_load_update += LOAD_FREQ;
}
上述函数是per-cpu更新的位置;
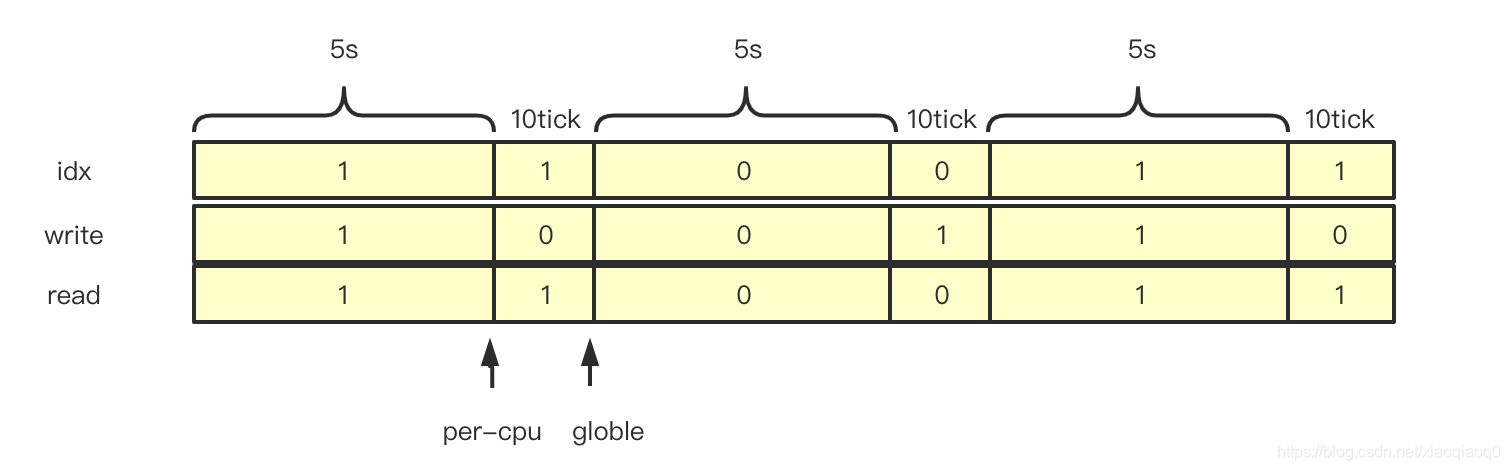
//进入idle的时候将数据更新到calc_load_idle数组中,需要根据idx和时间判断具体添加位置
void calc_load_enter_idle(void)
{
struct rq *this_rq = this_rq();
long delta;
// when the cpu is enter idle, update the load to calc_load_idle;
// we will use idx to choose if this load is used in this update tick;
delta = calc_load_fold_active(this_rq, 0);
if (delta) {
int idx = calc_load_write_idx();
atomic_long_add(delta, &calc_load_idle[idx]);
}
}
//决策添加的数组,这部分内容看下图理解会更方便
static inline int calc_load_write_idx(void)
{
int idx = calc_load_idx;
/*
* See calc_global_nohz(), if we observe the new index, we also
* need to observe the new update time.
*/
smp_rmb();
/*
* If the folding window started, make sure we start writing in the
* next idle-delta.
*/
//qyp :core, if per-cpu is calc load and then this perid idle update is used in next freq
if (!time_before(jiffies, calc_load_update))
idx++;
return idx & 1;
}
//在global更新的时候读取对应的数组内容;
static long calc_load_fold_idle(void)
{
int idx = calc_load_read_idx();
long delta = 0;
// use idx to choose the calc_load_idle, and return it
if (atomic_long_read(&calc_load_idle[idx]))
delta = atomic_long_xchg(&calc_load_idle[idx], 0);
return delta;
}
//读取idx
static inline int calc_load_read_idx(void)
{
return calc_load_idx & 1;
}
//退出idle的时候判断当前jiffies,即如果已经进入下个周期,则更新时间点
void calc_load_exit_idle(void)
{
struct rq *this_rq = this_rq();
// use the globle calc_load_update to forbidden the rq update tick is multi period no update
this_rq->calc_load_update = calc_load_update;
//if now is before per-cpu update tick : return
if (time_before(jiffies, this_rq->calc_load_update))
return;
//if now is before avnrun update tick : update the update tick,because we can not enter the tick to update it;
if (time_before(jiffies, this_rq->calc_load_update + 10))
this_rq->calc_load_update += LOAD_FREQ;
}
这个过程比较比较复杂,首先查看比较古老的版本,学习思想,再回来查看其设计方法:
- 实质:计算每个CPU上的nr_running和uninterrupt_sleep的数量,并返回;
- 过程中添加了一个记录idle状态的全局变量,用于更新当前的active数值,这里搞这么复杂实际上是为了解决进入IDLE后没有中断更新load的情况:
- 在进入Idle时,将load 数量更新到idle数组中;
- 到达更新点的时候,统一计算完整的idle数组中值,通过数组以及idx自增的方式判断实际的进入Idle时间以及是否需要计算;
- 退出idle时需要判断此时是否已经到达cpu计算load的时间点,如果已经到达,则更新update时间,避免重复计算 ;
3.2.4 这里有个很好玩的计算
对于可能存在的多个周期的idle情况,会调用到这里,这里就是会计算N个周期的load情况
通过数学公式计算可以发现其实N个周期后的计算公式为:
an = a0 * e^n + a * (1 - e) * (1 + e + … + e^n-1) [1]
= a0 * e^n + a * (1 - e) * (1 - e^n)/(1 - e)
= a0 * e^n + a * (1 - e^n)
所以这里会直接实现对应en的效果:
static void calc_global_nohz(void)
{
long delta, active, n;
// in globle update tick
if (!time_before(jiffies, calc_load_update + 10)) {
/*
* Catch-up, fold however many we are behind still
*/
//calc the period
delta = jiffies - calc_load_update - 10;
n = 1 + (delta / LOAD_FREQ);
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
//calc the n avenrun
avenrun[0] = calc_load_n(avenrun[0], EXP_1, active, n);
avenrun[1] = calc_load_n(avenrun[1], EXP_5, active, n);
avenrun[2] = calc_load_n(avenrun[2], EXP_15, active, n);
//update globle tick
calc_load_update += n * LOAD_FREQ;
}
/*
* Flip the idle index...
*
* Make sure we first write the new time then flip the index, so that
* calc_load_write_idx() will see the new time when it reads the new
* index, this avoids a double flip messing things up.
*/
smp_wmb();
calc_load_idx++;
}
上述函数是计算周期N的值,然后调用calc_load_n来计算上述公式:
static unsigned long
calc_load_n(unsigned long load, unsigned long exp,
unsigned long active, unsigned int n)
{
// math calc: n period = load * exp ^ n + active * (1-exp^n)
return calc_load(load, fixed_power_int(exp, FSHIFT, n), active);
}
那么en是怎么计算的呢?就在下边(通过右移减少计算次数):
static unsigned long
fixed_power_int(unsigned long x, unsigned int frac_bits, unsigned int n)
{
unsigned long result = 1UL << frac_bits;// * 2048
//use bit to calc e^n = e^1 * e^2 * e^4
if (n) {
for (;;) {
if (n & 1) {
//对应bit有则*x
result *= x;
result += 1UL << (frac_bits - 1);
result >>= frac_bits;
}
n >>= 1;
if (!n)
break;
//更新x x^2 x^4 .....
x *= x;
x += 1UL << (frac_bits - 1);
x >>= frac_bits;
}
}
return result;
}
问题记录
- 为什么avenrun计算的三个权重分别为1884、2014、2037,这个是如何决定的?

这里的系数是按照上述公式决定的即:2048 * (1 / e ^ (5s / period) ) - 为什么在5s一次的统计过程中要+10 tick,而且核心计算公式其实很简单,为什么流程要搞这么复杂?
A:- 由于存在多核情况,在计算各个核的load时和整体load更新时存在竞争,所以修改为在5HZ时各个CPU计算,而在+10tick之后更新给到AVGRUN;
- 由于存在nohz的情况,即IDLE时不会有中断更新计算load,所以要引入新的计算补足这一部分;
- 关于do_timer和scheduler_tick相关调度的整体逻辑是怎样的?
A: 实质就是在周期性中断到来的时候,调度对应函数检测是否到达更新周期进行计算;