一、 基本框架
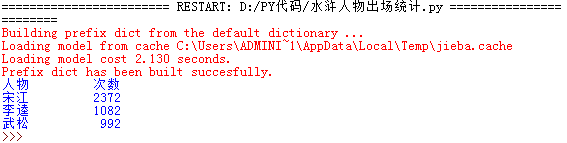
以统计水浒传人物出场次数为例,列出出场次数最高的前三名。
import jieba #引用中文分词库
txt = open("shuihu.txt","r",encoding="gb18030").read() #读取文件,注意编码
excludes = {"两个","一个"} #通过不断优化排除结果中的无用词
words = jieba.lcut(txt) #中文分词
counts = {} #用于保存结果的字典
for word in words: #遍历方法统计词频
if len(word) == 1:
continue
else:
counts[word]=counts.get(word,0) + 1 #巧用get
for word in excludes: #排除无用词
del counts[word]
items = list(counts.items()) #将结果转为列表形式
items.sort(key=lambda x:x[1],reverse=True) #以词频从高到低排序
print("{:<10}{:^5}".format("人物","次数")) #打印表头
for i in range(3): #打印出场次数前三名
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
输入:
输出:
二、 优化
以三国演义为例,将同一人物的不同称呼进行合并统计,使用if…elif…else
输入:

输出: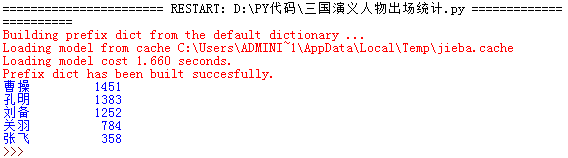
版权声明:本文为aieraisiji原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。