这个是在期末考试复习前,自己对整本书的部分复习,参考的资料有王道的视频、课本和老师上课时用到的PPT。
不同学校考试侧重点不同,一下是本学校喜欢的出题点,仅供参考。
选择、填空和判断:这个需要积累,考的很细,多些题目做做,如果时间来不及,就找一些总结,把总结看了后,就去做题,在做题的过程中去记忆。当然,刚开始做题,会有很多不会,这就要去找课本或者上网搜索,要看懂这个题目为什么这么写。
大题部分出题方向:
1.IEEE754计算题,将一个小转化为标准形式(第二章后有练习题目,多做几道就可以了,不会的话,可以上网搜索详细的解答步骤)
2.给一个公式或图,让你说出这个是那种寻址方式(这个的话,就需要仔细的看那几个图,做做题)
3..磁盘:求磁盘存储了多少信息、道密度、位密度(这一部分可以主要是公式)
4.CPU和存储器画图(要掌握原理,知道有多少根数据线、多少根地址线,片选信号等)
计算机组成原理组成:
- 运算器、控制器、存储器、输入设备和输出设备
- 两种信息流:控制信息流和数据信息流
- 控制信息流包括指令信息、状态信息、时序信息,这些信息的组合产生各类控制信号,对数据进行加工处理,并控制数据信息的流向,实现计算机的各项功能。
- 区分机器语言(最抽象,机器能够直接执行的)、汇编语言、高级语言(c\java等编程语言
- CPI:一条指令所需的时钟周期数
- 磁带机速度比磁盘速度慢,原因是磁带上的数据采用顺序访问方式,而磁盘则采用随机访问方式
- 外围设备大体分为:输入设备、输出设备、外存设备、数据通信设备、过程控制设备共五大类
- 磁盘、磁带属于磁表面存储器,特点是存储容量大,位价格低,记录信息永久保存,但存取速度较慢,在计算机系统中作为辅助大容量存储器使用
第一章
- 软件分类: 系统软件:用来管理整个计算机系统(操作系统、数据库管理系统(DBMS)、标准程序库、网络软件、语言处理程序、服务程序 应用软件:按任务需要编制成的各种程序(抖音、王者、迅雷等)
- 硬件的发展:电子管à晶体管à中小规模集成电路à大规模、超大规模集成电路
- 机器字长:计算机一次整数运算所能处理的二进制位数
- “存储程序”的概念是指将指令以二进制代码的形式事先输入计算机的主存储器,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规模顺序执行其他指令,直至程序执行结束。
- 五大功能部件:
a) 输入设备:将信息转换成机器能识别的形式 b) 存储器:存放数据和程序 c) 运算器:算术运算、逻辑运算 d) 输出设备:将结果转换成人们熟悉的形式 e) 控制器:指挥程序运行在计算机系统中:软件和硬件在逻辑是等效的。软件实现:成本低、效率低。硬件实现:成本高、效率高。
- 冯诺依曼体系结构计算机特点:
a) 五大功能部件组成 b) 软件以二进制形式表示(软件包含程序和数据) c) 采用存储程序的工作方式、 所有的程序预先放在存储器中 指令采用串行执行方式 d) 指令和数据以同等地位存于存储器,可按地址寻访 e) 指令由操作码和地址码组成 f) 以运算器为中心(输入/输出设备与存储器之间的数据传送通过运算器完成) 现代计算机:一般以存储器为中心 - 各个硬件的细节
a) 主存储器: 存储体:数据在存储体内按地址存储 MAR(Memory Address Register)存储地址寄存器,反应存储单元的个数 MDR(Memory Data Register)存储数据寄存器,MDR位数=存储字长 ACC:累计计数器,存放操作数、运算的结果 MQ:乘商寄存器,进行乘、除法时用得到 X:通用寄存器,存放操作数 b) 运算器: ALU:算术逻辑单元,通过内部复杂的电路实现算术运算、逻辑运算 c) 控制器: CU:控制单元,分析指令,给出控制信号 执行指令 IR:指令寄存器,存放当前的指令 分析指令 PC:程序计数器,存放下一条指令地址,有自动加1功能 取指 - 多级层次结构
a) 微程序控制器硬连逻辑部件<微程序级>机器指令(指令系统)<传统机器级>操作系统级<操作系统级>语言处理程序作为软件资源的应用程序数学模型、算法应用程序<系统分析级用户程序级> b) 机器语言(0、1代码组成)—>汇编语言(符号语言,转化为机器语言)-->高级语言 c) 机器语言:一种用二进制代码表示的计算机语言,机器可以直接执行用机器语言编写的程序。 d) 汇编语言:一种用助记符表示的与机器语言一一对应的语言,用汇编语言编写的程序要经过汇编后才能执行。(汇编是一个操作) e) 高级语言:一种接近人类自然语言的与计算机结构无关的语言,用高级语言编写的程序要经过解释和编译才能执行。 - 区别编译程序、解释程序和汇编程序
a) 编译程序:编译程序是先完整编译后运行的程序,编译程序把高级语言程序作为输入,进行翻译转换,产生出机器语言的目标程序,然后让计算机去执行这个目标程序,得到计算结果,如C、C++等 b) 解释程序:一句一句翻译且边翻译边执行的程序,是高级语言翻译程序的一种,它将源语言书写的源程序作为输入,解释一句就提交给计算机执行一句,并不形成目标程序。如Python、JavaScript c) 汇编程序:汇编程序使用汇编语言编写的程序,与编译程序、解释程序完全不是一个概念。 d) 编译程序和解释程序最大区别在于:前者生成目标代码,而后者不生成 - 性能指标:
a) 主存储器: 总容量=存储单元个数*存储字长bit=存储单元个数*存储字长/8 Byte b) CPU: CPU主频:CPU内数字脉冲信号震荡的频率 CPU主频(时钟频率)=1/cpu时钟周期 CPI:执行一条指令所需的时钟周期数 执行一条指令的耗时=CPI*CPU时钟周期 CPU执行时间(整个程序的耗时)=CPU时钟周期数/主频=(指令条数*CPI)/主频 IPS:每秒钟执行多少条指令 IPS=主频/平均CPI FLOPS:每秒钟执行多少条浮点运算 c) 系统整体的性能指标 数据通路带宽:数据总线一次所能并行传送信息的位数 吞吐量:指系统在单位时间内处理请求的数量 响应时间:至用户向计算机发送一个请求,到系统对该请求做出相应并获得他所需要的结果的等待时间。 - 当描述存储器容量和文件大小的时候,K=2^10, M=2^20 ,G=2^30,T=2^40
- 描述频率、速率的时候:K=10^3,M=10^6,G=10^9,T=10^12
第二章
- 不同符号表示不同的权重
- 基数:每个数码位所用到的不同符号的个数,r进制的基数为r
- 真值:符合人类习惯的数字
- 机器数:数字实际存到机器里的形式,正负需要被“数字化”
原码:用尾数表示真值的绝对值,符号位“0/1”对应“正、负” 原码=补码尾数取反+1 反码:若符号位为0,则反码与原码相同;若符号位为1,则数值位全部取反。 补码:正数的补码=原码; 负数的补码=反码末位+1(要考虑进位) 负数的补码=原码数值位取反+1 移码:补码的基础上将符号位取反。注意:补码只能用于表示整数- 补码和移码的真值0只有一种表示形式
- 技巧:由[x]补快速求[-x]补的方法,符号位、数值位全部取反,末位+1
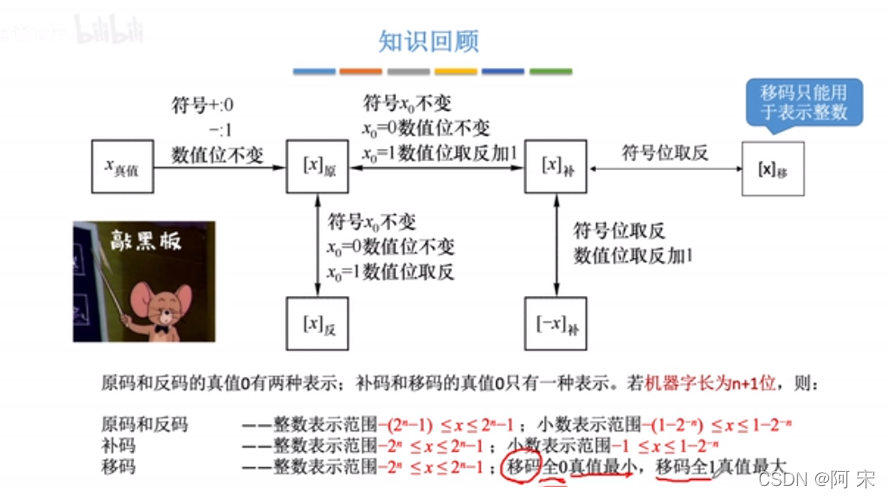
这个图来自王道网课中的截图
第三章 存储器
- 存储器分类:
a) 按存储介质分类: 半导体存储器:TTL(晶体管)、MOS 易失 磁表面存储器: 磁头、载磁体 非易失 b) 按存取方式分类: i. 存取时间与物理地址无关(随机访问) 随机存储器:在程序的执行过程中可读可写 ii. 存取时间与物理地址有关 顺序存取存储器 磁带 c) 存储内容可变性 i. 只读存储器(ROM):内容是固定不变的,即只能读出而不能写入 ii. 随机读写存储器(RAM):既能读出又能写入的半导体存储器 易失 d) 按在计算机中的作用分类 i. 主存储器:RAM(静态RAM,动态RAM)、ROM ii. 高速缓冲存储器(Chache) iii.辅助存储器 iv. 控制存储器 - 主存的技术指标
a) 存储容量:指一个存储器中可以容纳的存储单元总数。 b) 存取时间又称为存储器访问时间:存储器的访问时间,是指一次读操作命令发出到该操作完成,将数据读出到数据总线上所经历的时间。 通常,取写操作时间等于读操作时间,故称为存储区存取时间 c) 存取周期:连续启动两次读操作所需间隔的最小时间 通常,存储周期略大于存取时间 d) 存储器带宽:单位时间里存储器所存取的信息量,通常以位/秒做度量单位,带宽是衡量数据传输速率的重大技术指标 - 刷新只和行地址有关。
- SRAM(静态读写存储器)的优点是存取速度快,但存储容量不如DRAM(动态读写存储器)大。
- DRAM存储器中,输入缓冲器与输出缓冲器总是互锁的。这是因为读操作和写操作是互斥的,不会同时发生。
- DRAM芯片的逻辑结构与SRAM不同的是:
(1) 增加了行地址锁存器和列地址锁存器。 (2) 增加了刷新计数器和相应的控制电路。DRAM读出后必须刷新,而未读写的存储器也要定期刷新,而且要按行刷新,所以刷新计数器的长度等于行地址锁存器。书信操作与读/写才做是交替进行的,所以通过2选1多路开关提供刷新行地址或正常读/写的行地址。 (3) 一次读操作会自动刷新选中行中的所有存储位元 - DRAM刷新操作的三种方式:
a) 集中式刷新:DRAM的所有行在每一个刷新周期中都被刷新。 b) 分散式刷新:每一行的刷新插入到正常的读/写周期之中。 c) 异步式刷新:它将每一行的刷新都分开来,只要在规定的时间完成对每一行的刷新即可,(2ms/64)间隔进行一次刷新,这里的2ms是规定的,因为DRAM要求,至少2ms更新所有行一次。 - 存储器容量的扩充
a) 字长位数扩展:给定的芯片字长位数较短,不满足设计要求的存储字长,此时需要用多片给定芯片扩充字长位数。三组信号线中,地址线和控制线公用而数据线单独分开连接,所需芯片数计算公式为:d=设计要求的存储容量/已知芯片存储容量 b) 字存储容量扩展:给定的芯片存储容量较小(字数小),不满足设计要求的总存储容量,促使需要用多片给定芯片来扩充字数。三组信号组中给定芯片的地址总线和数据总线公用,控制总线R/-W公用,使能端EN不能公用,它由地址总线的高位段译码来决定片选信号。所需芯片数计算公式为:d=设计要求的存储容量/已知芯片存储容量 c) 存储器模块条:存储器通常以插槽用模块条形式供应市场。这种模块条常称为内存条,它们是在一个条状形的小印制电路板上,用一定数量的存储器芯片,组成一个存储容量固定的存储模块。然后通过它下部的插脚插到系统板专用插槽中,从而使存储器容量固定的存储模块得到扩充。 - 高级的DRAM结构
a) FPM-DRAM:快速页模式 b) CDRAM:带高速缓冲存储器 c) SDARM:同步型动态存储器 - 只读存储器ROM:与随机读/写的RAM不同,工作时只能读出,不能写入。其中存储的原始数据,必须在它工作以前写入。只读存储器由于工作可靠,保密性强,在计算机系统中得到广泛的应用。
a) 掩模ROM 是一个存储内容固定的ROM b) 可编程ROM两类 一次性编程的PROM 多次编程的EPROM:光擦除可编程刻度存储器,村纯内容可以根据需要写入,当需要更新时将原存储内容抹去,再写入新的内容 E2PROM:也写成EEPROM:电擦除可编程只读存储器 - FLASH存储器,也叫做闪速存储器,它是高密度非失易非性的读/写存储器。高密度意味着具有巨大比特数目的存储容量
- 双端口存储器:同一个存储器具有两组相互独立的读写控制电路(空间并行技术)
a) 无冲突读写控制:当两个端口的地址不相同时,在两个端口进行读写操作,一定不会发生冲突。 b) 有冲突的读写控制:当两个端口同时存取存储器同意存储单元时,便发生冲突。 片上的判断逻辑决定对哪个端口优先进行读写操作,而对另一个被延迟的端口置低电平,即暂时关闭此端口。通过延迟端口BUSY - 多模块交叉存储器 (时间并行技术)
a) 存储器的模块化组织:一个由若干模块组成的主存储器是线性编址的。这些地址在各模块中如何安排,有两种方式:一种是顺序方式,一种是交叉方式。 b) 顺序方式:某模块进行存取时,其他模块不工作,优点是某一模块出现故障时,其他模块可以照常工作,通过增添模块来扩充冲存储器容量比较方便。缺点是各模块串行工作,存储器的带宽受到了限制。 c) 多模块交叉存储器:连续地址分布在相邻的不同模块内,同一个模块内的地址都是不连续的。优点是对连续字的成块传送可实现多模块流水式并行存取,大大提高存储器的带宽。使用场合为成批数据读取 。
老师上课所用PPT的截图
cache的功能:高速缓冲存储器,解决CPU和主存之间的数度不匹配问题,全由硬件调度,对用户透明,一般采用高速的SRAM构成
CPU与cache之间的数据交换是以字为单位,而cache与主存之间的数据交换是以块为单位,块内地址完全相同。
命中率与Cache的容量和块长有关。
块长取一个存取周期内从主存调出的信息长度。
直接映射方式:是一种多对一的映射关系,但一个主存块只能拷贝到cache的一个特定行位置上去。优:硬件简单,成本低。缺:中途概率高(抖动),每一个主存只有一个固定的行位置可存放。还有可能产生冲突。
每个缓存块i可以和若干个主存块对应
每个主存块j只能和一个缓存块对应
Cache的行号i和主存的块号j有如下函数关系:i=j mod m(m为cache中的总行数)
全相联映射方式:带全部块地址(块号)和块内容(字)一起保存的方法,可使主存的一个块直接拷贝到cache中的任意一行上。优:冲突概率小,空间利用率高。缺:比较器电路难于设计和实现,成本高,适用于小容量cache采用。为了快速检索,指令中的块号与cache中所有行的标记同时在比较器中惊醒比较。
组相联映射方式:是直接映射方式和全相联映射方式的折中方案 ,速度比较快,命中率也比较高。cache分组,组间采用直接映射方式,组内采用全相联的映射方式 Cache分成u组,每组v行,m=u*v(m为cache中的总行数 组号 q=j mod u
多层次CPU中,靠近CPU,要求高速度,可以采用直接相连,或者是路数比较少的组相联,中间层次,可以采用组相联。距离CPU最远的cache层次,可以采用全相联的方式,速度要求低,利用率要求高。
替换策略:
LFU(最不经常使用 Least Frequently Used)算法:将一段时间内被访问次数最少的那行数据换出
LRU(近期最少使用 Least Recently Used)算法:将近期内长久未被访问过的行换出
随即替换:从特定的行位置中随机地选取一行换出即可,容易实现,速度快,命中率和cache的工作效率不高
cache的写操作策略:由于cache的内容只是主存部分内容的拷贝,它应当与主存内容保持一致。而CPU对cache的写入更改了cache的内容。
a) 写回法:当CPU写cache命中时,只修改cache的内容,而不立即写入主存;只有当此行被换出时才写回主存。未命中时,将此块整个拷贝到cache后对其修改,统一留到换出时写回,可能存在不一致的隐患。 b) 全写法:当写cache命中时,cache与主存同时发生写修改,因而较好地维护了cache和主存的内容一致性。未命中时,只能直接向主存进行写入。 优:cache中每行无需设置一个修改位,以及相应的判断逻辑。缺:cache对CPU向主存的写操作无高速缓冲功能,降低了cache的功效 c) 写一次法:基于写回法并结合全写法的写策略:写命中与未命中的处理方法与写回法基本相同,只是第一次写命中时要同时写入主存辅助存储器:
特点:比直接与CPU交换信息 磁表面存储器的技术指标 a) 记录密度: 道密度Dt,位密度Db b) 存储容量:C=n*k*s c) 平均寻址时间:寻道时间+等待时间 d) 数据传输率:Dr=Db*V 位密度*旋转速度
第四章指令系统
- 指令:是要计算机执行某种操作的命令。
- 从计算接组成的层次结构来说,计算机的指令有微指令、机器指令和宏指令之分。
微指令:微程序机的命令,属于硬件 宏指令:有若干条机器指令组成的软件指令,属于软件 机器指令:介于微指令与宏指令之间,通常简称指令,每一条指令可以完成一个独立的算数运算或逻辑运算 - 指令系统:一台计算机所有机器指令的集合
- 复杂指令系统计算机,简称CISC:不易调试维护,而且由于采用了大量使用频率很低的复杂指令而造成硬件资源浪费。
- 精简指令系统计算机,简称RISC,便于VLSI(超大规模集成电路)技术实现的精简指令系统计算机。
特点(采用流线技术):简单而统一格式的指令译码 大部分指令可以单周期执行 只有LOAD/STORE可以访问存储器 简单的寻址方式 采用LOAD延迟技术 三地址指令格式 较多的寄存器 对称的指令格式 - 对指令系统性能的要求:
a) 完备性:是指汇编语言编写各种程序是,指令系统直接提供的指令足够使用,而不必用软件实现。完备性要求指令系统丰富、功能齐全、使用方便 b) 有效性:是指利用该指令系统所编写的程序能够高效率的运行。高效率主要表现在程序占据存储空间小,执行速度快。 一般来说,一个功能更强、更完善的指令系统,必定有更好的有效性。 c) 规整性:包括指令系统的对称性、匀齐性、指令格式和数据格式的一致性。 对称性:在指令系统中所有的及存储器和存储器单元都可同等对待,所有的指令都可使用各种寻址方式, 匀齐性:一种操作性质的指令可以支持各种数据类型, 指令格式和数据格式的一致性:指令长度和数据长度有一定的关系,以方便处理和存取。例如指令长度和数据长度通常是字节长度的整数倍。 d) 兼容性:系列机各机种之间具有相同的基本结构和共同的基本指令集,因而指令系统是兼容的,即各机种上基本软件可以通用。只能做到“向上兼容“,即低档机上运行的软件可以在高档机上运行。 - 指令字长:一个指令字中包含二进制代码的位数
- 机器字长:指计算机能直接处理的二进制数据的位数
- 指令字长度等于机器字长度的指令,称为单字长指令
指令字长度等于半个机器字长度的指令,称为半字长指令
指令字长度等于两个机器字长度的指令,称为双字长指令

- 设某等长指令字机器的指令长度为16位,包括4位基本操作码字段和三个4位地址字段,则三地址指令15条,二地址指令14条,一地址指令31条,零地址指令16条
- RR 寄存器-寄存器类型,RS 寄存器-存储器类型 SS 存储器-存储器类型,速度由慢到快
- 一般的数据类型:
地址数据:地址实际上也是一种形式的数据 数值数据:计算机中普遍使用的三种类型的数值数据 字符数据:文本数据或字符串,目前广泛使用ASCLL码 逻辑数据:一个单元中有几位二进制bit项组成,每个bit的值可以是1或0.当数据以这种方式看待时,称为逻辑性数据。 - 寻址方式:形成操作数有效地址的方法
- 指令寻址方式:顺序寻址方式和跳跃寻址方式
- 数据寻址方式:形成操作数的有效地址的方法(寻址过程就是把操作数寻址方式,变换为操作数的有效地址的过程)
- 隐含寻址:
立即寻址:指令执行阶段不访存 直接寻址:有效地址=形式地址 间接寻址:需要多次访存 寄存器寻址: 寄存器间接寻址:有效地址在寄存器中,操作数在存储器中,执行阶段需要访存 偏移寻址:基址寻址:可扩大寻址范围,有利于多道程序;相对寻址、变址寻址 堆栈寻址:先进后出,进栈减一,出栈加一
第五章CPU
- CPU的功能:
指令控制(程序的顺序控制) 操作控制(一条指令有若干操作信号实现) 时间控制(指令各个操作实施时间的定时) 数据加工(算术运算和逻辑运算)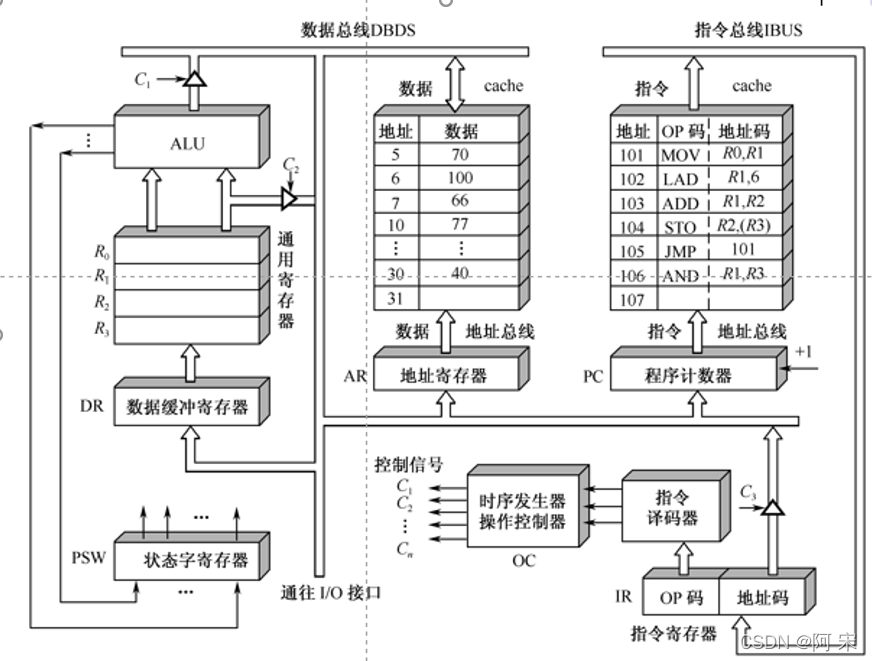
- 指令周期:指取指令、分析指令到执行完该指令所需的全部时间
- CPU周期通常又称时钟周期:通常把一条指令周期划分为若干个机器周期,每个机器周期完成一个基本操作。 CPU读取一个指令字的最短时间来规定CPU周期
- CPU周期,称为机器周期,又称时钟周期,内存中读取一个指令字的最短时间来规定CPU周期。
- 一个CPU周期又包含有若干个T周期。T周期为计算机操作的最小时间单位。
- 一条指令所需的最短时间为两个CPU周期。
- MOV是一条RR型指令,指令周期是两个CPU周期,寄存器寻址。
单字长,二地址。 - 取数指令LAD,是一条RS型指令,指令周期是三个CPU周期(在DBUS上进行了地址传送和数据传送),直接寻址,寄存器寻址。单字长,二地址。
- ADD是一条RR型指令,指令周期是两个CPU周期,寄存器寻址。单字长,二地址。
- STO是一条RS型指令,指令周期是两个CPU周期,寄存器寻址,寄存器间接寻址(选择(R3)=30做数据存储器的地址单元)。单字长,二地址。
- JMP指令周期是两个CPU周期,直接寻址。单字长,二地址。
- 控制方式:控制不同操作序列时序信号的方法。分为:同步控制方式、异步控制方式、联合控制方式
- 微命令的编码方法:直接表示方法、编码表示法、混合表示法
- 机器指令的操作码转换成初始为地址的方式只要有两种:计数器的方式、多路转移的方式
第六章总线
- 总线:连接各个部件的信息传输线,是各个部件共享的传输介质
- 总线上信息的传送:串行(支持的距离长)、并行(支持的距离短)
- 总线的分类:
a) 内部总线:CPU内部连接各个寄存器及运算器部件之间的总线 b) 系统总线:外部总线。CPU和计算机系统中其他高速功能部件相互连接的总线。 数据总线:双向 与机器字长、存储字长有关 地址总线:单向 与存储地址、I/O地址有关 控制总线:有出、有入 c) I/O总线:中低速I/O设备相互连接的总线 传输方式:串行通信总线、并行通信总线 - 总线的特性
物理特性:总线的物理连接方式(根数、插头、插座形状,引脚排列方式) 电气特性:传输方向和有效的电平范围 功能特性:每根线的功能:地址、数据、控制 时间特性:规定了每根总线在什么时间有效 - 总线的性能指标
a) 总线宽度:总线本身所能达到的最高传输速率。(同时可以传输的,根数越多,传输的位数越多) b) 标准传输率:每秒传输的最大字节数(MBps:每秒传输了多少百万字节) c) 始终同步/异步:同步、不同步 d) 总线复用:地址线与数据线共用(为了减少芯片管脚数,芯片封装体系减少) e) 信号线数:地址线、数据线和控制线的总和 f) 总线控制方式:突发、自动、仲裁、逻辑、计数(用什么方式控制总线的传输) g) 其他指标:负载能力(这条总线上可以挂载多少I/O设备) - ISA-->EISA-->VESA-->PCI-->AGP-->RS-232-USB
- 通道:具有特殊功能的处理器,由通道对I/O统一管理
- DMA:直接存储器 访问
- 总线接口—信息传送方式:
串行传送:适应于长距离,只需要一条传输线,成本比较低廉,但速度慢

并行传送:每一数据位需要一条传输线,一般采用电位传送
分时传送:总线复用或是共享总线的部件分时使用总线
- 总线上的模块:
主设备(模块) 对总线有控制权 从设备(模块) 响应从设备发来的总线命令 - 仲裁方式:
a) 集中式仲裁: i.菊花链查询方式 距离总线仲裁器越近优先级越高,越远越低 优点:结构简单易扩充设备 缺点:对电路故障敏感,优先级固定 ii.计数器定时查询方式 每次计数可以从“0”开始,也可以从中止点开始。如果从“0”开始,各设备的优先次序与链式查询法 相同,优先级的顺序是固定的。如果从中止点开始,则每个设备使用总线的优先级相等。计数器的 处置也可以用程序来设置,这就可以方便的改变优先次序,显然这种灵活性是以增加线数为代价。 iii.独立请求方式 对优先次序的控制灵活。可以预先固定,也可以通过程序改变优先次序,还可以用屏蔽某个请求的 办法,不响应来自无效设备的请求。 优点:响应时间快,对优先次序控制灵活 b) 分布式仲裁:以优先级仲裁策略为基础 - 总线传输周期:
a) 请求总线:主模块申请,总线仲裁决定 b) 总线仲裁:判断哪个先执行 c) 寻址阶段:主模块向从模块给出地址和命令 d) 信息传送:主模块和从模块交换数据 e) 状态返回(或错误报告):主模块撤销有关信息 - 定时:指事件出现在总线上的时序关系
- 同步定时:
a) 同步定时具有较高的传输频率 b) 当各个功能模块存取时间相差较大时,会大大损失总线效率 c) 同步定时适用于总线长度较短、各功能模块存取时间比较接近的情况。这是因为同步方式对任何功能模块的通信都给予同样的时间安排。由于同步总线必须按最慢的模块来设计公共时钟,当各个模块寻去时间相差很大时,会大大损失总线效率。 - 异步定时:
a) 在异步定时协议中,后一事件出现在总线上的时刻取决于前一事件的出现,即建立在应答或互锁机制基础上。在这种系统中,不需要统一的公共时钟信号。总线周期的长度是可变的。 b) 从设备:受主设备控制 c) 异步定时的优点时总线周期长度可变,不把响应时间强加到功能模块上,因而允许快速和慢速的功能模块都能连接到同一总线上,但这以增加总线的复杂性和成本为代价。 - 当代流行的标准总线追求与结构、CPU、技术无关的开发标准。其总线内部结构包含:数据传送总线(由地址线、数据线、控制线组成)、仲裁总线、中断和同步总线、公用线
- PCI总线是当前实用的总线。是一个高带宽且与处理器无关的标准总线,又是重要的层次总线。采用同步定时和集中式仲裁策略,并具有自动配置能力。
第八章输入输出系统
- 输入/输出控制方式:
主要有程序实现:程序查询方式、程序中断方式 主要有硬件实现:DMA方式、通道方式 - 程序查询方式:CPU和I/O设备串行工作,分散连接
- 中断方式、DMA方式:CPU和I/O设备 并行工作
- I/O指令 CPU指令的一部分
- 通道指令 通道自身的指令:指出数组的首地址、传送字数、操作命令
- I/O设备编制方式:(1)统一编制 用取数、存数指令(2)不统一编制(单独编址):有专门的I/O指令
- 联络方式:立即响应、异步工作采用应答信号、同步工作采用同步时标
- I/O设备与主机的连接方式:辐射式连接、总线连接(便于增删设备)
- 程序查询方式:是一种最简单的输入输出方式,数据在CPU和外围设备之间
- 程序中断方式:I/O工作在自身准备的时候,CPU不查询,在与主机交换信息时,CPU暂停现行程序。
- DMA方式 (直接内存访问方式):是一种完全由硬件执行I/O交换的工作方式,DMA控制器从CPU完全接管对总线的控制,数据交换不经过CPU,而直接在内存和外围设备之间进行,以高速传送数据。
a) 主存和I/O之间有一条直接数据通道 b) 不中断现行程序 c) 周期挪用 d) 适用于内存和高速外围设备之间大批数据交换场合。 - 通道方式:DMA方式的出现已经减轻了CPU对I/O操作的控制,是的CPU的效率有显著的提高,而通道的出现则
- 中断服务程序的流程
a) 保护现场:1)程序断点服务:中断隐指令完成 2)寄存器内容的保护:进栈指令 b) 终中断服务:对不同的I/O设备具有不同内容的设备服务 c) 恢复现场 出栈指令 d) 中断返回 中断返回指令 e) 中断服务程序 f) 中断源、中断服务程序(入口地址) g) 向量中断、中断向量、中断向量表 h) 查询中断 - 中断向量:当CPU响应中断时,有硬件直接产生一个固定的地址(即向量地址)由向量地址指出每个中断源设备的中断服务程序入口,这种方法称为向量中断。
单级中断:所有中断源属于同一级,离CPU越近,优先级越高。不允许中断现行的中断服务程序 多级中断:允许级别更高的中断源中断现行的中断服务程序 宏观上CPU和I/O并行工作 微观上CPU中断现行程序位I/O服务8259中断控制器是一个集成电路芯片,它将中断接口与优先级判断等功能汇集于一身,常用于微型机系统
多个8259进行级联以处理多达64个中断请求。在这种情况下,允许有一个主中断控制器和多个从中断控制器。
优先级选择方式有四种: 完全嵌套方式:是一种固定优先级方式,连至IR0的设备优先级最高,IR7的优先级最低。这种固定优先级方式对级别低的中断级别低的中断不利,在有些情况下低级别的中断请求可能一直不能被处理 轮换优先级方式A:每个级别的中断保证有机会被处理,将给定的中断级别处理后,立即把它放到最低级别的位置上去 轮换优先级方式B:要求CPU可在任何时间规定最优优先级,然后顺序地规定其他IR线上地优先级 查询方式:由CPU访问8259的中断状态寄存器,一个状态字能表示出正在请求中断的最高优先级IR线,并能表似乎出中断请求是否有效。8259提供了两种屏蔽方式:
简单屏蔽方式,提供8位屏蔽字,每位对应着各自的IR线。被置位的任一位则禁止了对应IR线上的中断 特殊屏蔽方式,允许CPU让来自低优先级的外设中断请求去中断高优先级的服务程序。当8位屏蔽位的某位置置“0”时,例如屏蔽字为11001111,说明IR4和IR5线上的中断请求可中断任何高级别的值中断服务程序- 8259中断控制器的不同工作方式是通过编程来实现的。CPU送出一系列的初始化控制字和操作控制字来执行选定的操作。
- DMA(直接存储器访问方式)是为了在主存储器与I/O设备间高速交换批量数据而设置的
基本思想:通过硬件控制实现主存与I/O设备间的直接数据传送,在传送过程中,无需CPU的干预。数据传送狮子啊DMA 控制器控制下进行的 优点:速度快。有利于发挥CPU的效率 - DMA传送方式
1) 停止CPU访问内存 优点:控制简单,适用于数据传输率很高的设备进行成组传送 缺点:在DMA控制器访内阶段,内存的效能没有充分发挥,相当一部分内存工作周期是空闲的。这是 因为,外围设备传送两个数据之间的间隔一般总是大于内存存储周期,即使高速I/O设备也是如此。 2) 周期挪用方式:DMA控制器与主存储器之间传送一个数据,占用(窃取)一个CPU周期,即CPU暂停工 作一个周期,然后继续执行程序。 3) DMA与CPU交替访内 如果CPU的工作周期比内存存取周期长很多,可以采用该方法 总线控制权的转移速度快,DMA效率高 - DMA控制器按其组成结构,分为选择型和多路型两类
- 通道是一个特殊功能的处理器,他有自己的指令和程序专门负责数据输入输出的传输控制,从而使CPU将“传输控制”的功能下放给通道,CPU只负责“数据处理”功能。这样,通道与CPU分时使用内存,实现了CPU内部的数据处理与I/O设备的平行工作。 通道有两种类型:选择通道和多路通道。
- 通用I/O接口标准
并行I/O标准接口SCSI:小型计算机系统接口的简称,是一个高速只能接口,可以混接磁盘、光盘、磁带机、打印机以及通信设备 串行I/O标准接口IEEE1394:数据传送的高速性,实时性,体积小易安装,连接方便 - 串行与外设之间是串行,其余都是并行