一、简答题(笔试面试常见)
1、MySQL常见的三种存储引擎(InnoDB、MyISAM、Memory)的区别。
数据库存储引擎是数据库底层软件组织,进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能, MySQL的核心就是存储引擎。
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 没有 | 有 |
| 事务安全 | 支持 | ||
| 支持外键 | 支持 | ||
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B树索引 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | 支持 | |
| 全文索引 | 支持 | ||
| 集群索引 | 支持 | ||
| 数据缓存 | 支持 | 支持 | |
| 索引缓存 | 支持 | 支持 | 支持 |
| 数据可压缩 | 支持 | ||
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入的速度 | 低 | 高 | 高 |
InnoDB:
- InnoDB提供了事务处理、回滚、崩溃修复能力和多版本并发控制的事务安全。靠后版本的MySQL的默认存储引擎就是InnoDB。
- 支持自动增长(AUTO_INCREMENT)。自动增长列的值不能为空,并且值必须唯一。
- 支持外键(FOREIGN KEY)。外键所在的表叫做子表,外键所依赖的表叫做父表。父表中被字表外键关联的字段必须为主键。当删除、更新父表中的某条信息时,子表也必须有相应的改变,这是数据库的参照完整性规则。
- InnoDB中,创建的表的表结构存储在.frm文件中。数据和索引存储在innodb_data_home_dir和innodb_data_file_path定义的表空间中。
- 优点:提供了良好的事务处理、崩溃修复能力和并发控制。适合频繁的更新、删除操作的数据库
- 缺点:读写效率较差,占用的数据空间相对较大。
MySIAM:
- MyISAM的表存储成3个文件。文件的名字与表名相同。拓展名为frm、MYD、MYI。frm文件存储表的结构;MYD文件存储数据;MYI文件存储索引。
- MyISAM表格可以被压缩,而且它们支持全文搜索。在进行updata时进行表锁,并发量相对较小。
- MyISAM的索引和数据是分开的,MyISAM缓存在内存的是索引,不是数据,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引。
- 优点:查询数据相对较快,适合大量的select,可以全文索引。
- 缺点:不支持事务,不支持外键,并发量较小,不适合大量update。
Memory:
- Memory使用存储在内存中的内容来创建表,而且数据全部放在内存中。
- 每个基于Memory存储引擎的表实际对应一个磁盘文件。该文件的文件名与表名相同,类型为frm类型。该文件中只存储表的结构。而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。
- Memory用到的很少,因为它是把数据存到内存中,如果内存出现异常就会影响数据。如果重启或者关机,所有数据都会消失。
- 它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。
- 优点: 数据处理速度快,很快的读写速度
- 缺点: 安全性不高,不能建太大的表
2、数据库事务的四个特性及含义。
- 原子性(Atomicity)
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 - 一致性(Correspondence)
在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。 - 隔离性(Isolation)
隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。 - 持久性(Durability)
在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
3、数据库三范式是什么?
第一范式(1NF):列不可拆分 , 即无重复的域。
特点:有主关键字、主键不能为空、主键不能重复,字段不可以再分。第二范式(2NF):有唯一标识 ,即每个表有且仅有一个主关键字,其他数据元素与主关键字一一对应。
特点:满足第一范式的前提下,消除部分函数依赖第三范式(3NF):引用主键 ,即每列数据都与主键直接相关,不能有其他依赖关系
特点:不存在非主属性对码的传递性依赖以及部分性依赖
范式:经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式
说明:关系型数据库有六种范式。一般说来,数据库只需满足第三范式(3NF)就行了。
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
4、数据库支持的SQL数据类型常用的有哪些?
(1)字符串类型:
- char: 固定长度存储数据
- varchar: 按变长存储数据
- text :当你需要存储非常大量的字符串时使用
(2)数值类型:
- bigint :大整数。从 -2 ^ 63 到 2^63 -1 的整型数据(所有数字)。
- int :普通。从 -2 ^ 31到 2^31 - 1 的整型数据(所有数字)。
- smallint:小整数。 从 -2 ^ 15 到 2^15 - 1的整数数据。
- tinyint: 很小整数。从 0 到 255 的整数数据。
- float:单精度浮点数
- double:双精度浮点数
(3)时间/日期类型:
- date:‘YYYY-MM-DD’ 。从1000-01-01到9999-12-31。
- datetime:‘YYYY-MM-DD HH:MM:SS’或’YYYYMMDDHHMMSS’。从1000-01-01 00:00:00到9999-12-31 23:59:59。
- timestamp:格式同datetime。从19700101 080001 到2038年某个时刻。并且以UTC(世界标准时间)进行存储,即timestamp会随设置的时区而变化。
- time:‘HH:MM:SS’。从-838:59:59到838:59:59。
- year:从1901到2155
5、 SQL数据类型varchar和char的区别?
char的长度是不可变的,而varchar的长度是可变的
例如:
char(10):如果存进去的是‘python’,那么char所占的长度依然为10,除了字符’python’外,后面补4个空格。当你输入的字符大于指定的数时,它会截取超出的字符。取出数据需要用trim()去掉多余的空格。
varchar(10):如果存进去的是‘python’,就立马把长度变为6了。varchar类型的实际长度是它的值的实际长度+1。取出数据需不需要去除空格。
char长度固定,存取速度快。占用空间大。
varcgar节省空间。
6、SQL 约束有哪几种并解释含义(eg:NOT NULL、UNIQUE等)?
| 约束 | 含义 |
|---|---|
| NOT NULL | 某列非空 |
| UNIQUE | 某列的每行必须具有唯一的值 |
| PRIMARY KEY | 主键 |
| DEFAULT | 规定默认值 |
| CHECK | 保证列中的值符合指定的条件 |
| FOREIGN KEY | 外键 |
| AUTO_INCREMENT | 自动增长 |
7、数据库内连接、左连接、右连接有什么区别?
对于以下两个表table1和table2进行操作:
左连接:
以左边的表为准,没有的置为空
select * from table1 left join table2 on (table1.id=table2.id);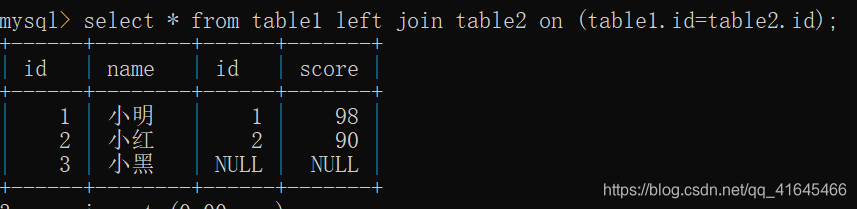
右连接:
以右边的表为准,没有的置为空
select * from table1 right join table2 on (table1.id=table2.id);
内连接:
显示两个表中共有的
select * from table1 inner join table2 on (table1.id=table2.id);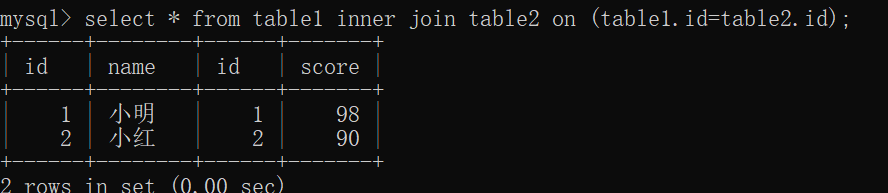
8、 SQL语句查询时如何实现分页?
limit 实现分页查询
# 在表table1中查询,从第1行开始,查询3条信息
select * from table1 limit 3
# 在表table1中查询,从第3行开始,查询4条信息
select * from table1 limit 2,4
9、什么是SQL注入?
SQL注入是一种主要在Web应用程序上执行的攻击,在SQL注入中,攻击者通过Web表单等输入接口注入部分恶意SQL。这些注入的语句发送到Web应用程序后面的数据库服务器,可能会执行不需要的操作,例如提供对未经授权的人的访问或删除或读取敏感信息等。
SQL注入漏洞可能会影响使用SQL数据库(如MySQL,Oracle,SQL Server或其他)的任何网站或Web应用程序。犯罪分子可能会利用它来未经授权访问用户的敏感数据:客户信息,个人数据,商业机密,知识产权等。SQL注入攻击是最古老,最流行,最危险的Web应用程序漏洞之一。
10、数据库怎么优化查询效率?
- 储存引擎选择:如果数据表需要事务处理,应该考虑使用 InnoDB,因为它完全符合 ACID 特性。如果不需要事务处理,使用默认存储引擎 MyISAM 是比较明智的
- 对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描
- 应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
- Update 语句,如果只更改 1、2 个字段,不要 Update 全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志
- 对于多张大数据量(这里几百条就算大了)的表 JOIN,要先分页再 JOIN,否则逻辑读会很高,性能很差。
二、数据库操作
1、创建数据库表employees, 包含的信息有:
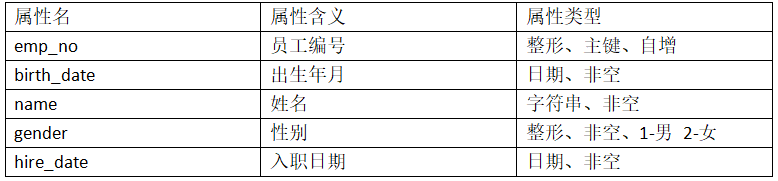
create table employees(
emp_no int primary key auto_increment,
birth_date date not null,
name varchar(20) not null,
gender int not null,
hire_date date not null);
2、批量插入数据如下:
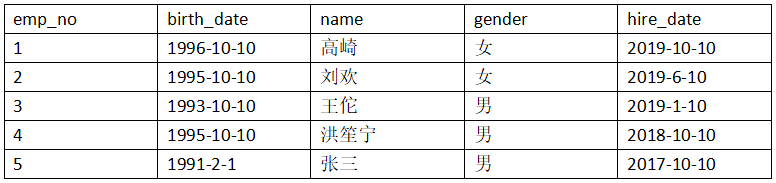
insert into employees(birth_date,name,gender,hire_date)
values('1996-10-10','高崎',2,'2019-10-10'),
('1995-10-10','刘欢',2,'2019-6-10'),
('1993-10-10','王佗',1,'2019-1-10'),
('1995-10-10','洪笙宁',1,'2018-10-10'),
('1991-2-1','张三',1,'2017-10-10');
3、更新高崎的出生日期为1996-12-12
update employees set birth_date='1996-12-12' where name='高崎';
4、统计员工总人数:
select count(*) as total_employees from employees;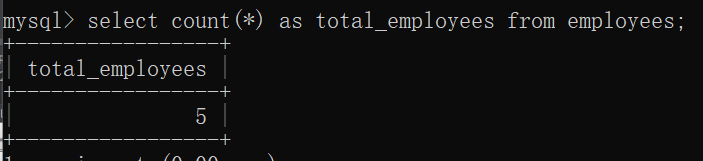
5、统计入职时间超过2年的员工姓名
select name from employees where year(now())-year(hire_date)>2;
6、查找最晚入职员工的所有信息
select * from employees where hire_date = (select max(hire_date) from employees);
三、数据库操作,对于如下数据库表



#1、查询students表中的所有记录的sname、ssex和class列
select sname,ssex,class from students;
#2、查询教师所有的单位即不重复的depart列。
select distinct depart from teachers;
#3、查询students表的所有记录。
select * from students;
#4、查询scores表中成绩在60到80之间的所有记录。
select * from scores where degree between 60 and 80;
#5、查询scores表中成绩为85,86或88的记录。
select * from scores where degree in(85,86,88);
#6、查询students表中“95031”班或性别为“女”的同学记录
select * from students where class=95031 or ssex='女';
#7、以class降序查询students表的所有记录。
select * from students order by class desc;
#8、以cno升序、degree降序查询scores表的所有记录。
select * from scores order by cno,degree desc;
#9、查询“95031”班的学生人数。
select count(*) as 95031_count from students where class=95031;
#10、查询‘3-105’号课程的平均分。
select avg(degree) as avg_degree from scores where cno='3-105';
#11、查询scores表中至少有5名学生选修的并以3开头的课程的平均分数。
#先列出3开头的所有的课程和平均分,再在这些课程中选出超过5个的,用group by进行分组
select cno,avg(degree) from scores where cno like'3%' group by cno having count(cno)>=5;
#12、查询最低分大于70,最高分小于90的sno列。
select sno from scores group by sno having max(degree)<90 and min(degree)>70;
#13、查询成绩最高的前5名学生
select * from scores order by degree desc limit 5;
#14、查询scores表中的最高分的学生学号和课程号。
# select sno, cno from scores order by degree desc limit 1;如果有好几个,这种方法就不对
select sno, cno from scores where degree=(select max(degree) from scores);
#15、查询scores中选学一门以上课程的同学中分数为非最高分成绩的记录
# where:直接对表里的数据进行筛选
#having: 对于分组后的内容再进行筛选,就是group by 后必用 having
select * from scores group by sno having count(cno)>1 and degree != max(degree);
#16、查询95033班和95031班全体学生的记录
select * from students where class =95033 or class =95031;
#17、查询存在有85分以上成绩的课程cno
select cno from scores group by cno having degree > 85;
#18、查询student表中不姓'王'的同学记录
select * from students where sname != (select * from students where sname like '王%');
#19、查询所有任课教师的tname和depart
select tname,depart from teachers;
#20、查询所有学生的sname、cno和degree列。
#sname,cno,degree没有在一个表中,所以将表scores和表students进行连接
select sname,cno,degree from scores left join students on scores.sno=students.sno;
select sname,cno,degree from students,scores where student.sno=scores.sno
#21、查询成绩在85到90分之间的学生姓名name、班级class和成绩degree
select sname,class,degree from scores left join students on scores.sno=students.sno where degree between 85 and 90;
#22、查询操作系统成绩最高的学生名和学生分数。
select sname,degree from scores left join students on scores.sno=students.sno group by degree having degree=(select max(degree) from scores where cno='3-245');
#23、查询李军选修的课程名称。
#三个表连接
select distinct cname from (scores left join courses on scores.cno=courses.cno) left join students on scores.sno=students.sno where sname='李军';