最近项目中要使用NLP进行情感分析,作为一个Java程序员,对于NLP是一窍不通,就连python语言也是没入门。这可难坏了。
通过各种百度找资料,发现了这个帖子(链接如下:https://www.cnblogs.com/jclian91/p/10886031.html),参考这个帖子写了一个NLP的demo案例。其中参考的源代码和部分数据:https://github.com/renjunxiang/Text-Classification/blob/master/TextClassification/data/data_single.csv
我讲GitHub的代码拉到本地之后,用pycharm打开 下载好相关包之后运行,这里不得不说python的环境之多真是大坑,各种版本不匹配的问题以及版本问题导致的代码不兼容,哎,实在是大坑。
1. 首先看看经过我更改之后的python项目目录结构:
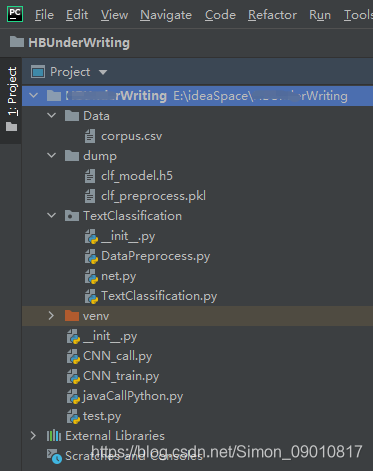
其中TextClassification中的代码就是上面GitHub上的,其中就有CNN训练的一些封装的代码。注意这个目录结构,因为后面Java调用python的时候我遇到的问题就在这。
2.python自身和依赖第三方包的版本
首先是python自己的版本,我选用的是anaconda
![]()
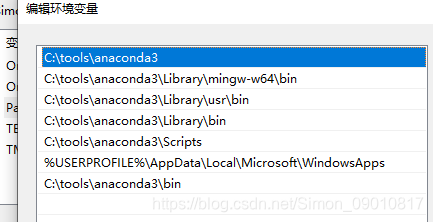
安装之后就是python3.8 注意安装的时候选择将路劲添加到环境变量中,自己配置过于繁琐。大概就是这样的:
其次是项目中依赖的第三方包:

主要就是这几个,这里特别说明的是keras是需要tensorflow的,所以还是间接需要tensorflow的包
具体的版本就是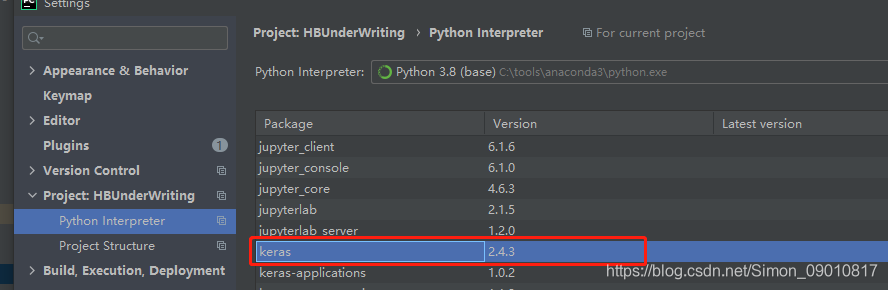
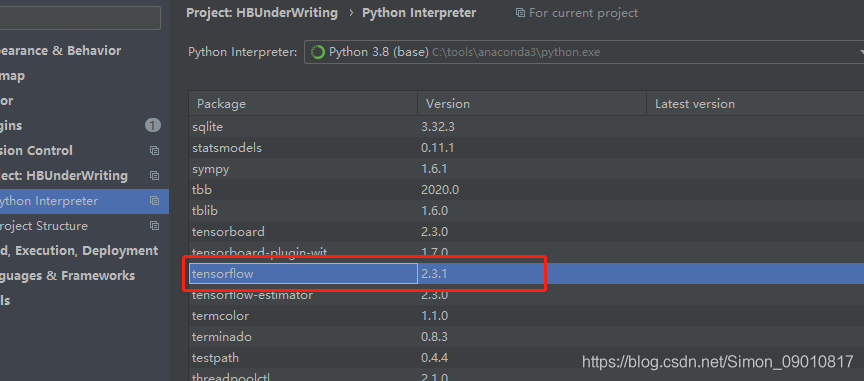
其他的版本下载最新版就可以 问题应该不大。
这里说下下载第三方包。在pycharm中下载很有可能下载不成功。即使是配置了豆瓣的镜像http://pypi.douban.com/simple
我用anaconda下载比较快速:
首先配置pip的全局镜像:
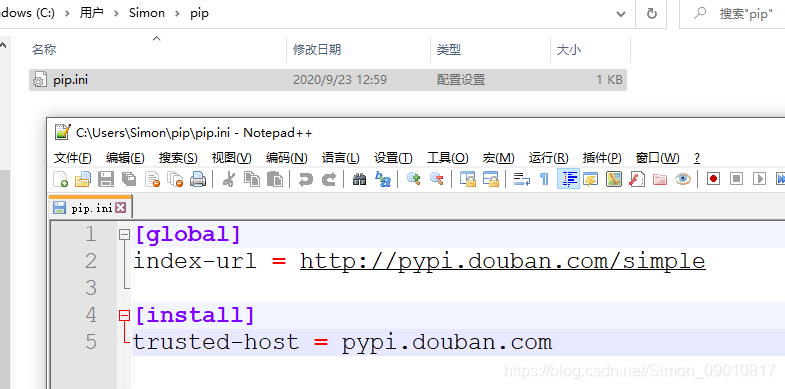
在用户目录下新建pip文件夹和pip.ini,pip文件内容如下:
[global]
index-url = http://pypi.douban.com/simple
[install]
trusted-host = pypi.douban.com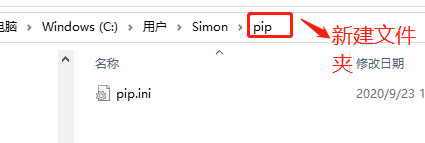
在anaconda安装目录下cmd 进行安装各自的依赖:

安装好之后就可以进行训练了。
整个训练序列化了两个文件,分别是封装类中的preprocess和model,这里需要用不同的序列化方式。
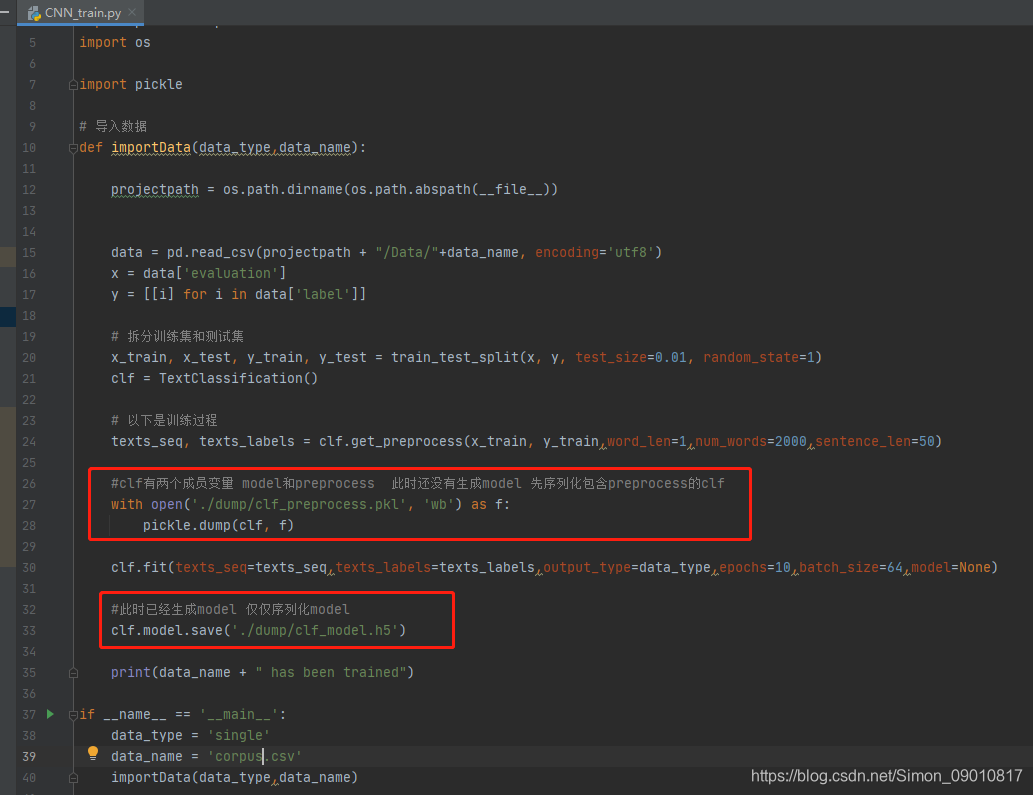
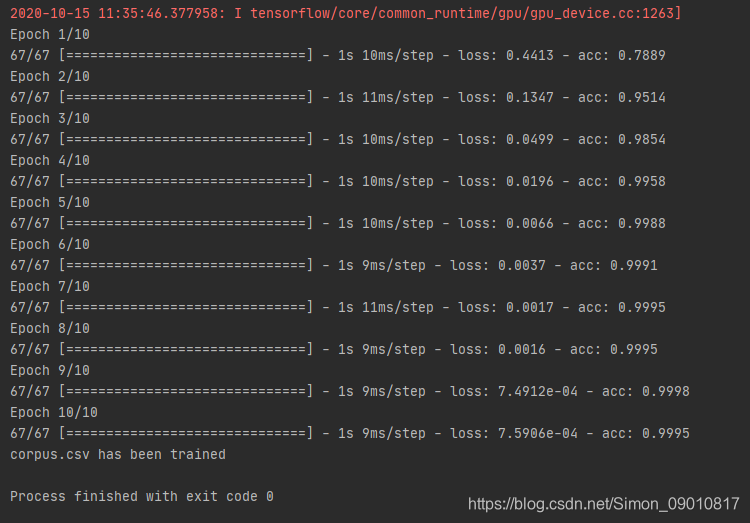
序列化成功之后,进行模型调用和预测:
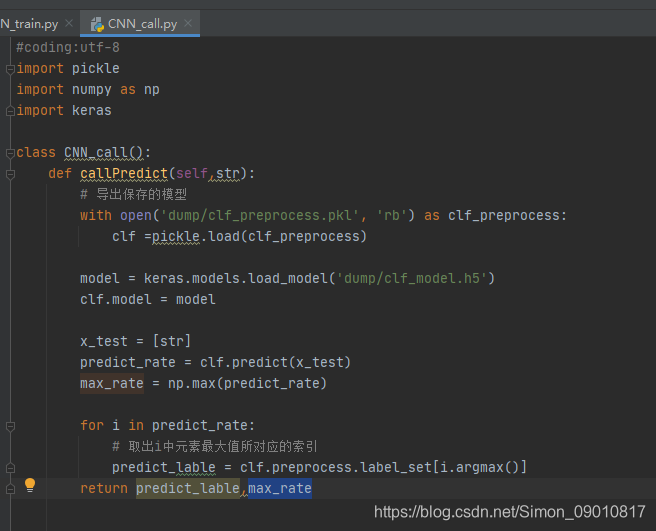
读取训练时保存的pkl和h5文件,类似与java中class对象的成员变量。再调用封装类的predict方法。
进行测试:
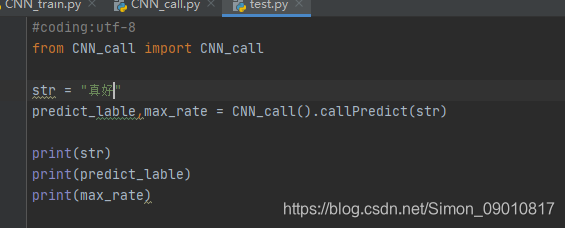
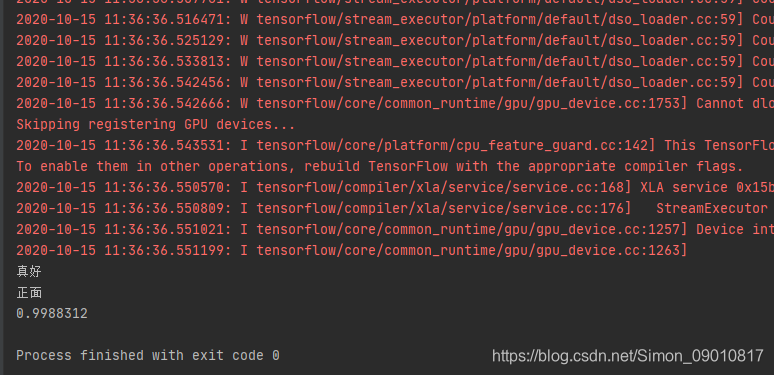
模型跑通了,传参预测也能做了。接下来就需要在Java项目中进行调用了。这里就卡住了。
首先我在网上找了相关的资料,发现Java调用python有两种方法,第一种即使使用jython,这种方法我试过了,对于引用第三方依赖包的python项目支持的不好,我照着https://www.cnblogs.com/nuccch/p/8435693.html这篇帖子做了,在jython中添加了第三方依赖的路径到系统环境变量中依然不行。后来又看到是因为我的python项目是3.8的版本,这个jython的下载的是2.7.2的版本,所以我想下载对应jython3的版本,结果网上几乎没有,唯一一个github上的jython3项目还没有人用过,最后果断放弃了第一张方式。第二种就是简单粗暴的 Runtime.getRuntime().exec(),我就是用这种实现的。
首先贴代码:
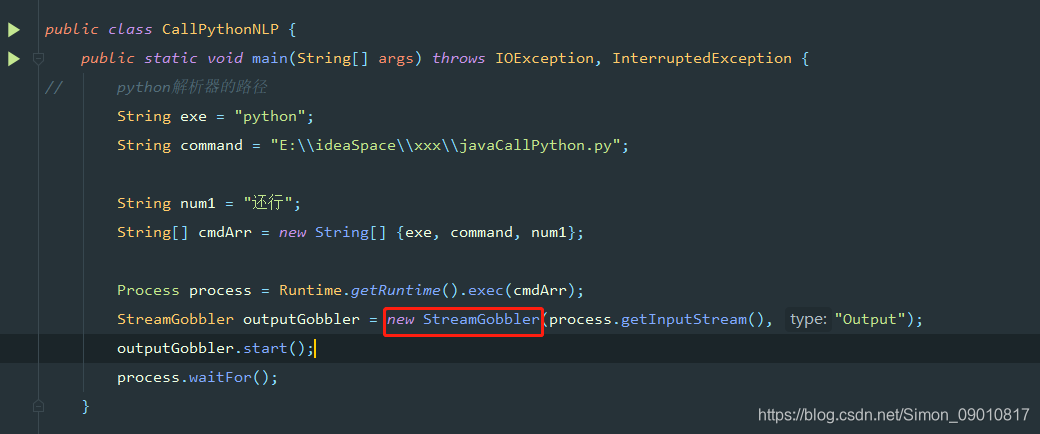
这里的自定义类是开启了一个线程,注意要在子线程中,不然就得不到返回值。
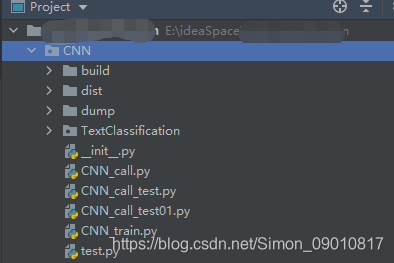
我之前将项目代码放在一个目录下,而没有直接放在项目下,导致训练的保存的模型load进代码找不到对应的mode,因为python加载文件成clf对象之后,类似一个class对象,这个时候它发现类路径不在Lib中,即使是在项目子目录下也没识别(我是这么理解的)
原来的 目录结果是这样的: CNN_train、CNN_call都是子目录CNN下 ,所以load pkl文件一直走不过去
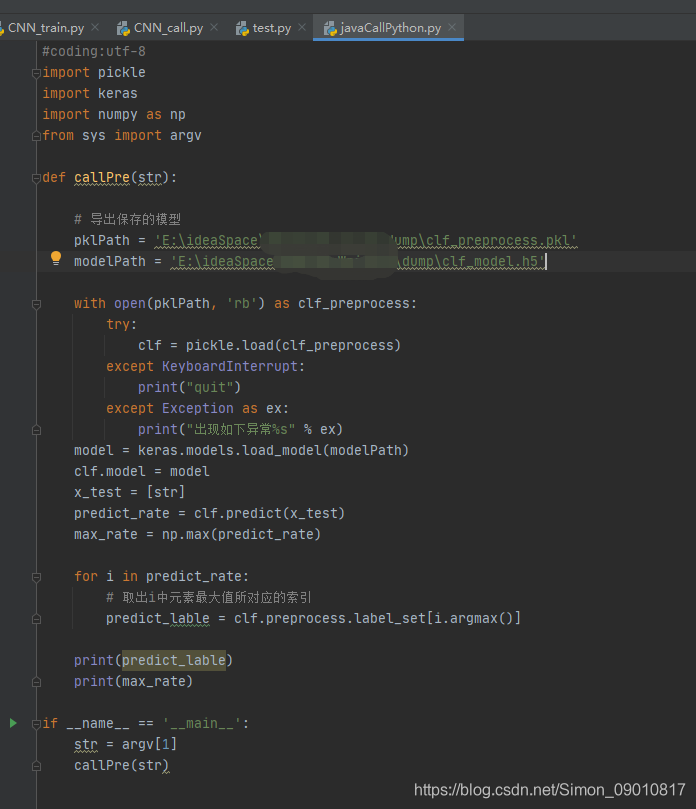
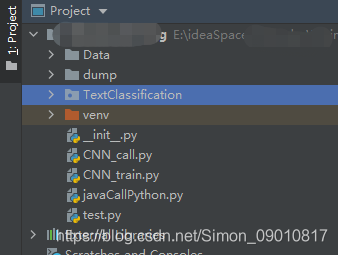
现在把代码放到项目目录下 去除子目录,就能直接掉通了:
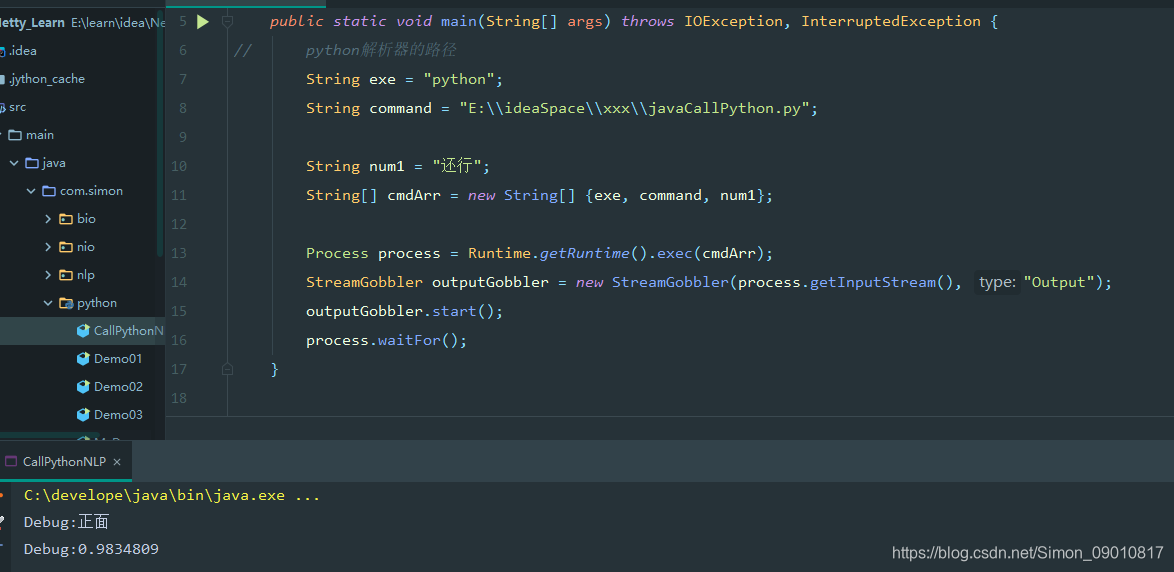
Java调用结果:
相关代码:
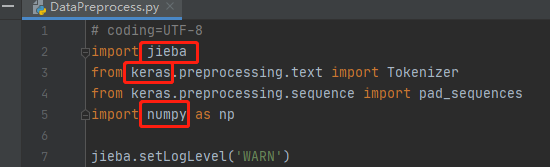
DataPreprocess.py
# coding=UTF-8
import jieba
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
jieba.setLogLevel('WARN')
class DataPreprocess():
def __init__(self, tokenizer=None,
label_set=None):
self.tokenizer = tokenizer
self.num_words = None
self.label_set = label_set
self.sentence_len = None
self.word_len = None
def cut_texts(self, texts=None, word_len=1):
"""
对文本分词
:param texts: 文本列表
:param word_len: 保留最短长度的词语
:return:
"""
if word_len > 1:
texts_cut = [[word for word in jieba.lcut(text) if len(word) >= word_len] for text in texts]
else:
texts_cut = [jieba.lcut(one_text) for one_text in texts]
self.word_len = word_len
return texts_cut
def train_tokenizer(self,
texts_cut=None,
num_words=2000):
"""
生成编码字典
:param texts_cut: 分词的列表
:param num_words: 字典按词频从高到低保留数量
:return:
"""
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(texts=texts_cut)
num_words = min(num_words, len(tokenizer.word_index) + 1)
self.tokenizer = tokenizer
self.num_words = num_words
def text2seq(self,
texts_cut,
sentence_len=30):
"""
文本转序列,用于神经网络的ebedding层输入。
:param texts_cut: 分词后的文本列表
:param sentence_len: 文本转序列保留长度
:return:sequence list
"""
tokenizer = self.tokenizer
texts_seq = tokenizer.texts_to_sequences(texts=texts_cut)
del texts_cut
texts_pad_seq = pad_sequences(texts_seq,
maxlen=sentence_len,
padding='post',
truncating='post')
self.sentence_len = sentence_len
return texts_pad_seq
def creat_label_set(self, labels):
'''
获取标签集合,用于one-hot
:param labels: 原始标签集
:return:
'''
label_set = set()
for i in labels:
label_set = label_set.union(set(i))
self.label_set = np.array(list(label_set))
def creat_label(self, label):
'''
构建标签one-hot
:param label: 原始标签
:return: 标签one-hot形式的array
eg. creat_label(label=data_valid_accusations[12], label_set=accusations_set)
'''
label_set = self.label_set
label_zero = np.zeros(len(label_set))
label_zero[np.in1d(label_set, label)] = 1
return label_zero
def creat_labels(self, labels=None):
'''
调用creat_label遍历标签列表生成one-hot二维数组
:param label: 原始标签集
:return:
'''
label_set = self.label_set
labels_one_hot = [self.creat_label(label) for label in labels]
return np.array(labels_one_hot)
net.py
from keras.models import Model
from keras.layers import Dense, Embedding, Input
from keras.layers import Conv1D, GlobalMaxPool1D, Dropout
def CNN(input_dim,
input_length,
vec_size,
output_shape,
output_type='multiple'):
'''
Creat CNN net,use Embedding+CNN1D+GlobalMaxPool1D+Dense.
You can change filters and dropout rate in code..
:param input_dim: Size of the vocabulary
:param input_length:Length of input sequences
:param vec_size:Dimension of the dense embedding
:param output_shape:Target shape,target should be one-hot term
:param output_type:last layer type,multiple(activation="sigmoid") or single(activation="softmax")
:return:keras model
'''
data_input = Input(shape=[input_length])
word_vec = Embedding(input_dim=input_dim + 1,
input_length=input_length,
output_dim=vec_size)(data_input)
x = Conv1D(filters=128,
kernel_size=[3],
strides=1,
padding='same',
activation='relu')(word_vec)
x = GlobalMaxPool1D()(x)
x = Dense(500, activation='relu')(x)
x = Dropout(0.1)(x)
if output_type == 'multiple':
x = Dense(output_shape, activation='sigmoid')(x)
model = Model(inputs=data_input, outputs=x)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['acc'])
elif output_type == 'single':
x = Dense(output_shape, activation='softmax')(x)
model = Model(inputs=data_input, outputs=x)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
else:
raise ValueError('output_type should be multiple or single')
return model
if __name__ == '__main__':
model = CNN(input_dim=10, input_length=10, vec_size=10, output_shape=10, output_type='multiple')
model.summary()
TextClassification.py
# coding=UTF-8
from .DataPreprocess import DataPreprocess
from .net import CNN
import numpy as np
class TextClassification():
def __init__(self):
self.preprocess = None
self.model = None
def get_preprocess(self, texts, labels, word_len=1, num_words=2000, sentence_len=30):
# 数据预处理
preprocess = DataPreprocess()
# 处理文本
texts_cut = preprocess.cut_texts(texts, word_len)
preprocess.train_tokenizer(texts_cut, num_words)
texts_seq = preprocess.text2seq(texts_cut, sentence_len)
# 得到标签
preprocess.creat_label_set(labels)
labels = preprocess.creat_labels(labels)
self.preprocess = preprocess
return texts_seq, labels
def fit(self, texts_seq, texts_labels, output_type, epochs, batch_size, model=None):
if model is None:
preprocess = self.preprocess
model = CNN(preprocess.num_words,
preprocess.sentence_len,
128,
len(preprocess.label_set),
output_type)
# 训练神经网络
model.fit(texts_seq,
texts_labels,
epochs=epochs,
batch_size=batch_size)
self.model = model
def predict(self, texts):
preprocess = self.preprocess
word_len = preprocess.word_len
sentence_len = preprocess.sentence_len
# 处理文本
texts_cut = preprocess.cut_texts(texts, word_len)
texts_seq = preprocess.text2seq(texts_cut, sentence_len)
return self.model.predict(texts_seq)
def label2toptag(self, predictions, labelset):
labels = []
for prediction in predictions:
label = labelset[prediction == prediction.max()]
labels.append(label.tolist())
return labels
def label2half(self, predictions, labelset):
labels = []
for prediction in predictions:
label = labelset[prediction > 0.5]
labels.append(label.tolist())
return labels
def label2tag(self, predictions, labelset):
labels1 = self.label2toptag(predictions, labelset)
labels2 = self.label2half(predictions, labelset)
labels = []
for i in range(len(predictions)):
if len(labels2[i]) == 0:
labels.append(labels1[i])
else:
labels.append(labels2[i])
return labels
CNN_call.py
#coding:utf-8
import pickle
import numpy as np
import keras
class CNN_call():
def callPredict(self,str):
# 导出保存的模型
with open('dump/clf_preprocess.pkl', 'rb') as clf_preprocess:
clf =pickle.load(clf_preprocess)
model = keras.models.load_model('dump/clf_model.h5')
clf.model = model
x_test = [str]
predict_rate = clf.predict(x_test)
max_rate = np.max(predict_rate)
for i in predict_rate:
# 取出i中元素最大值所对应的索引
predict_lable = clf.preprocess.label_set[i.argmax()]
return predict_lable,max_rate
CNN_train.py
#coding:utf-8
from TextClassification import TextClassification
from sklearn.model_selection import train_test_split
import pandas as pd
import os
import pickle
# 导入数据
def importData(data_type,data_name):
projectpath = os.path.dirname(os.path.abspath(__file__))
data = pd.read_csv(projectpath + "/Data/"+data_name, encoding='utf8')
x = data['evaluation']
y = [[i] for i in data['label']]
# 拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.01, random_state=1)
clf = TextClassification()
# 以下是训练过程
texts_seq, texts_labels = clf.get_preprocess(x_train, y_train,word_len=1,num_words=2000,sentence_len=50)
#clf有两个成员变量 model和preprocess 此时还没有生成model 先序列化包含preprocess的clf
with open('./dump/clf_preprocess.pkl', 'wb') as f:
pickle.dump(clf, f)
clf.fit(texts_seq=texts_seq,texts_labels=texts_labels,output_type=data_type,epochs=10,batch_size=64,model=None)
#此时已经生成model 仅仅序列化model
clf.model.save('./dump/clf_model.h5')
print(data_name + " has been trained")
if __name__ == '__main__':
data_type = 'single'
data_name = 'corpus.csv'
importData(data_type,data_name)
javaCallPython.py
#coding:utf-8
import pickle
import keras
import numpy as np
from sys import argv
def callPre(str):
# 导出保存的模型
pklPath = 'E:\ideaSpace\xxx\dump\clf_preprocess.pkl'
modelPath = 'E:\ideaSpace\xxx\dump\clf_model.h5'
with open(pklPath, 'rb') as clf_preprocess:
try:
clf = pickle.load(clf_preprocess)
except KeyboardInterrupt:
print("quit")
except Exception as ex:
print("出现如下异常%s" % ex)
model = keras.models.load_model(modelPath)
clf.model = model
x_test = [str]
predict_rate = clf.predict(x_test)
max_rate = np.max(predict_rate)
for i in predict_rate:
# 取出i中元素最大值所对应的索引
predict_lable = clf.preprocess.label_set[i.argmax()]
print(predict_lable)
print(max_rate)
if __name__ == '__main__':
str = argv[1]
callPre(str)test.py
#coding:utf-8
from CNN_call import CNN_call
str = "真好"
predict_lable,max_rate = CNN_call().callPredict(str)
print(str)
print(predict_lable)
print(max_rate)CallPythonNLP.java
package com.simon.python;
import java.io.*;
public class CallPythonNLP {
public static void main(String[] args) throws IOException, InterruptedException {
// python解析器的路径
String exe = "python";
String command = "E:\\ideaSpace\\xxx\\javaCallPython.py";
String num1 = "还行";
String[] cmdArr = new String[] {exe, command, num1};
Process process = Runtime.getRuntime().exec(cmdArr);
StreamGobbler outputGobbler = new StreamGobbler(process.getInputStream(), "Output");
outputGobbler.start();
process.waitFor();
}
}