写在之前
先来回顾一下ANTLR4是如何处理并分析输入流的。
语法文件
一个简单的类分析语法文件。
grammar Simple;
prog: classDef+ ; // match one or more class definitions
classDef
: 'class' ID '{' member+ '}' // a class has one or more members
{System.out.println("class "+$ID.text);}
;
member
: 'int' ID ';' // field definition
{System.out.println("var "+$ID.text);}
| 'int' f=ID '(' ID ')' '{' stat '}' // method definition
{System.out.println("method: "+$f.text);}
;
stat: expr ';'
{System.out.println("found expr: "+$ctx.getText());}
| ID '=' expr ';'
{System.out.println("found assign: "+$ctx.getText());}
;
expr: INT
| ID '(' INT ')'
;
INT : [0-9]+ ;
ID : [a-zA-Z]+ ;
WS : [ \t\r\n]+ -> skip ;
输入流的处理分析过程
我们从常见的main程序中截取一段:
ANTLRInputStream input = new ANTLRInputStream(System.in);
SimpleLexer lexer = new SimpleLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
SimpleParser parser = new SimpleParser(tokens);
parser.prog();
首先我们创建一个ANTLRInputStream,并从System.in获取到
输入流://System.in class T XYZ { int ; }创建一个Simple语法下的词法分析器lexer,并传入input。我们这一步将
input对照着Simple.tokens,在lexer通过词法分析,得出了映射关系。//Simple.tokens T__0=1 T__1=2 T__2=3 T__3=4 T__4=5 T__5=6 T__6=7 T__7=8 INT=9 ID=10 WS=11 'class'=1 '{'=2 '}'=3 'int'=4 ';'=5 '('=6 ')'=7 '='=8创建CommonTokenStream,我们将词法分析过后的tokens从lexer中取出,根据顺序排列起来成为
tokens的流。(其中可能丢弃了一些空白符号)最后我们将tokens放入Simple语法的Parser中,进行语法分析,从Prog文法规则开始解析。
修改错误信息
ANTLR4本身自带了ConsoleErrorListener,但有时候我们需要自定义错误信息,这时可以从BaseErrorListener那继承来,并重写syntaxError。
我们即将介绍两种自定义错误信息:
- 通过栈显示当前错误位置经过了哪几次语法判定。
- 显示当前错误行,并在出错的token下标记。
错误时显示规则栈调用
syntaxError的几个参数我们等会对照着运行结果细说。
注意recognizer可以强转成Parser、CommonTokenStream等多个类型。
//TestE_Listener.java
public static class VerboseListener extends BaseErrorListener {
@Override
public void syntaxError(Recognizer<?, ?> recognizer,
Object offendingSymbol,
int line, int charPositionInLine,
String msg,
RecognitionException e)
{
List<String> stack = ((Parser)recognizer).getRuleInvocationStack();
Collections.reverse(stack);
System.err.println("rule stack: "+stack);
System.err.println("line "+line+":"+charPositionInLine+" at "+
offendingSymbol+": "+msg);
}
}
需要注意parser需要去掉原有的ConsoleErrorListener,再实例化自定义的。
parser.removeErrorListeners(); // remove ConsoleErrorListener
parser.addErrorListener(new VerboseListener()); // add ours
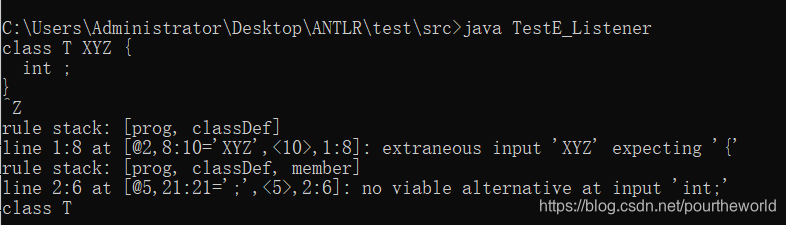
运行结果:
可以看到rule stack里,从prog->classDef规则匹配时发现出现了问题。
接下来我们一一解析各个参数。
- line:当前出错行。
- charPositionInLine:出错token首字符在当前行的位置。
- offendingSymbol:我们以
[@2,8:10='XYZ',< 10 >,1:8]为例。@2指的是XYZ这个token在整个tokens流里的位置,从0开始算,也就是第3个。8:10是指该token对应的源字符串从头到尾的字符位置。
< 10 >指的是词法符号的index,可以回顾上面的Simple.tokens。最后的1:8和开头的1:8含义相同。 - msg则是经过判断后的出错信息显示。
标记出错的token
offendingSymbol我们将它强转成Token类型,为了获取它的开始与结束的字符位置。- 如何从CommonTokenStream提取出最初的System.in的输入流呢。
我们先从CommonTokenStream中提取出TokenSource,也就是lexer里token与Input的映射;
再提取出它原有的CharStream,也就是系统输入的System.in,它还没有经过lexer处理。
ANTLR4 API - 通过换行符我们将input切割,然后将出错的那行先打印出来。
- 在charPositionInLine之前的第二行输入空格。
- 然后通过从offendingSymbol转来的token,获取start,stop的Index,并给上标记。
- 特别需要注意在java中,
print和println差了个回车。
public static class UnderLineListener extends BaseErrorListener {
@Override
public void syntaxError(Recognizer<?, ?> recognizer,
Object offendingSymbol,
int line, int charPositionInLine,
String msg,
RecognitionException e)
{
System.err.println("line "+line+":"+charPositionInLine+" "+msg);
UnderLineError(recognizer, (Token)offendingSymbol, line, charPositionInLine);
}
protected void UnderLineError(Recognizer recognizer,Token offendingToken,int line,int charPositionInLine){
CommonTokenStream tokens=(CommonTokenStream)recognizer.getInputStream();
String input=tokens.getTokenSource().getInputStream().toString();
String lines[]=input.split("\n");
String errorLine=lines[line-1];
System.out.println(errorLine);
for(int i=0;i<charPositionInLine;++i) System.err.print(" ");
int start=offendingToken.getStartIndex();
int stop=offendingToken.getStopIndex();
if(start>=0&&stop>=0) for(int i=start;i<=stop;++i) System.err.print("^");
System.err.println();
}
}
运行结果: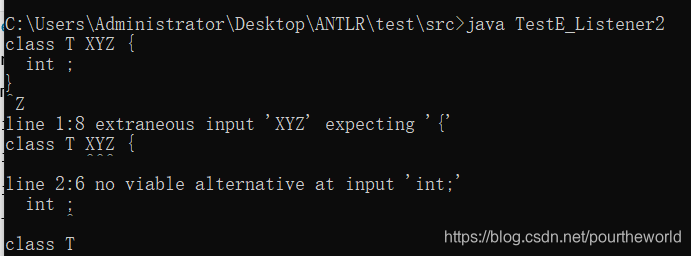
修改错误处理手段
ANTLR4在遇到错误时,往往会通过一些自动恢复的机制,使得匹配从错误中恢复过来。
但有时我们需要让它及时地停止并抛出异常,比如对于bash的处理。
词法异常跳出
因为对于输入流的匹配是从词法开始的,比如我们在Simple的语法顶一下,输入:
# class T { int i; }
我们需要让它在词法分析#的时候,就抛出异常。
于是我们自定义一个SimpleLexer,将它的自动恢复函数重写一遍,抛出异常。
public static class BailSimpleLexer extends SimpleLexer{
public BailSimpleLexer(CharStream input) { super(input); }
public void recover(LexerNoViableAltException e) {
throw new RuntimeException(e); // Bail out
}
}
在编写main函数的时候注意,将SimpleLexer改成BailSimpleLexer。
运行结果:
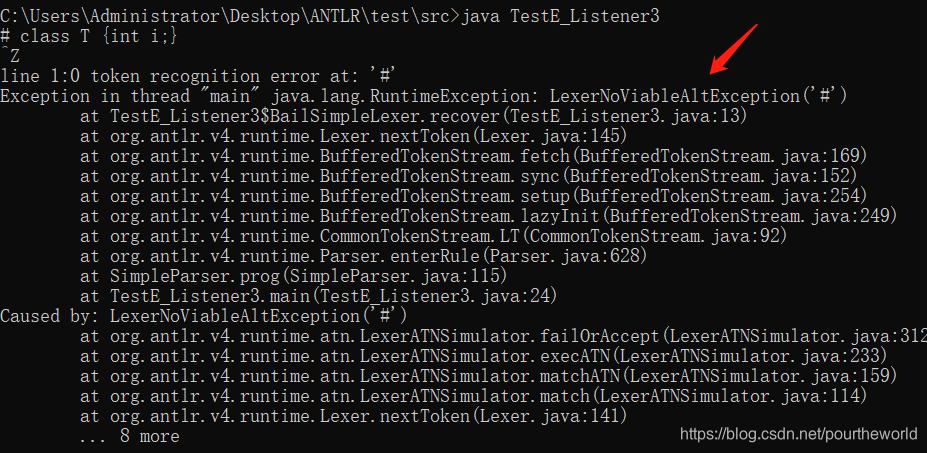
语法异常跳出
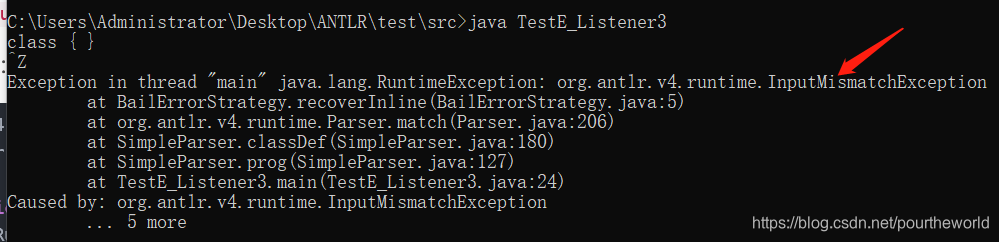
更常见的是语法匹配时,我们不需要自动恢复,而是抛出异常。
比如输入:
class {}
我们需要自定义DefaultErrorStrategy,这是针对Parser的。
一共有三个需要重写:句内恢复、子规则同步、其它恢复。
import org.antlr.v4.runtime.*;
public class BailErrorStrategy extends DefaultErrorStrategy{
@Override public Token recoverInline(Parser recognizer) throws RecognitionException{
throw new RuntimeException(new InputMismatchException(recognizer));
}
@Override public void sync(Parser recognizer){}
@Override public void recover(Parser recognizer,RecognitionException e){
throw new RuntimeException(e);
}
}
运行结果:
相当是句内恢复的异常抛出。