本文主要讲述Kettle中参数的分类,并针对每一类参数的使用进行说明。
关于变量的使用介绍,请参考历史文章:Kettle变量和参数介绍系列文章1-变量的使用
参数的分类
在Kettle中参数主要可以分为2类,分别是位置参数(Argument)和命名参数(Parameter)。两者的表现形式如下图所示:
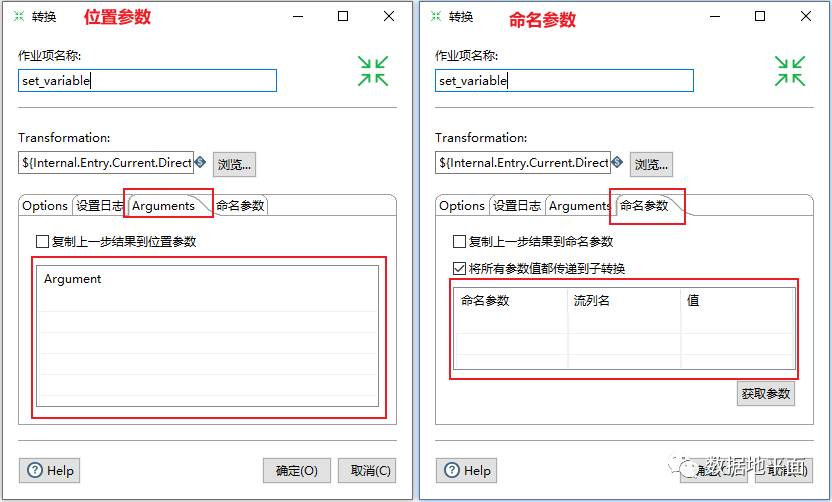
位置参数没有参数名称,只能通过参数的位置顺序进行识别,而命名参数有具体的参数名称,是通过参数名称进行识别的。因此,命名参数像变量一样,可以在有效范围内被多次使用;而位置参数只能被其后的步骤使用一次,或通过“设置变量”组件把其转化为变量。
参数的使用
1、遵循“外部赋值,内部使用”的原则
变量可以在脚本文件执行过程中进行动态创建和赋值,而参数和变量的最大不同就是,需要在脚本文件执行前指定参数值,然后才能在程序内部执行时进行使用,也就是我们常说的“传参”。
传参的好处就是,我们可以根据具体的业务需求动态地指定对应的参数值,而不需要重新去编辑脚本文件,操作相对简单,且有利于执行程序的稳定和复用。
当然,对于命名参数,为了程序的高效运行,我们可以给其指定常用的默认值。位置参数在日常的使用频次相对较低,目前不支持默认值设置。
2、在哪里使用参数
位置参数和流字段(数据流中的字段)的使用类似,区别就是其是在程序执行前赋值的。
命名参数的使用和变量类似,在Kettle中带有“$”符号的输入框基本都可以使用,需要注意的是其使用范围,只能在程序执行中引用,像数据库连接配置等场景就不能使用。
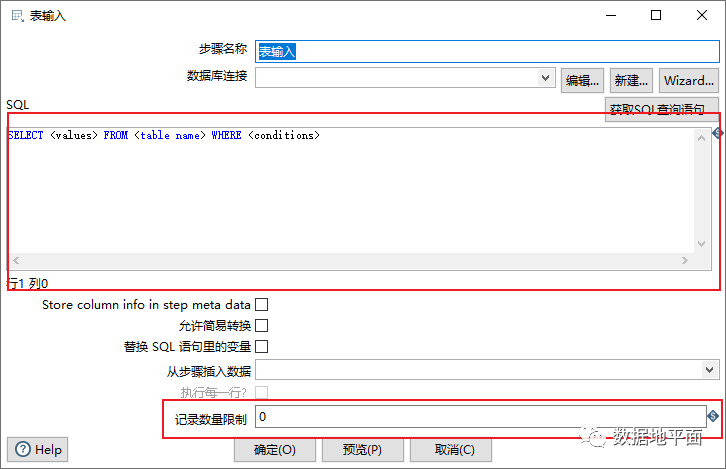
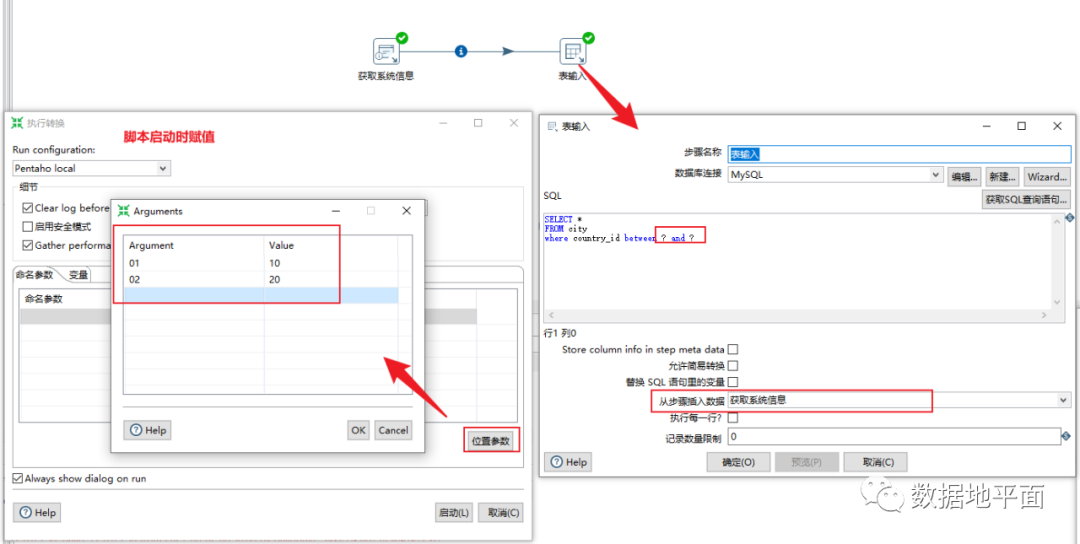
例如“表输入”组件,SQL输入框和记录数量限制输入框都可以使用变量和命名参数,其中SQL输入框内容包含变量和命名参数时,必须勾选“替换SQL语句里的变量”这句话。
下面将具体讲解下每种参数的具体使用方法。
位置参数
1、设置位置参数
位置参数只能在转换文件中设置。
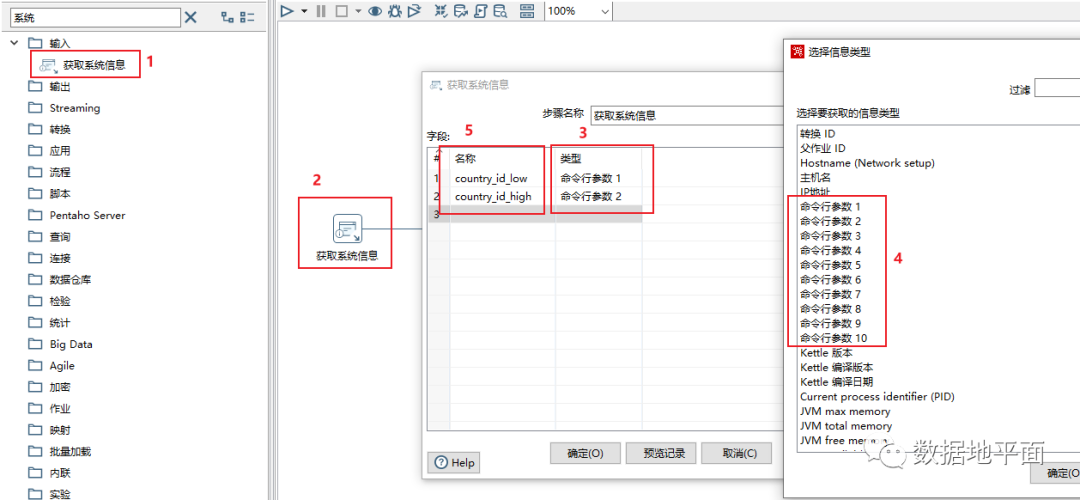
在输入对象中找到"获取系统信息"组件,把其拖到工作区后双击打开,点击"类型"下的输入框,选择"命令行参数";在"名称"处我们可以给位置参数起一个业务名称,以便帮助我们更好地理解参数的业务含义,但这个名称仅相当于数据流中的字段名称,并不能像变量或命名参数一样去直接引用;在一个转换文件中最多可以设置10个位置参数。
2、使用位置参数
2.1 通过"?"匿名引用
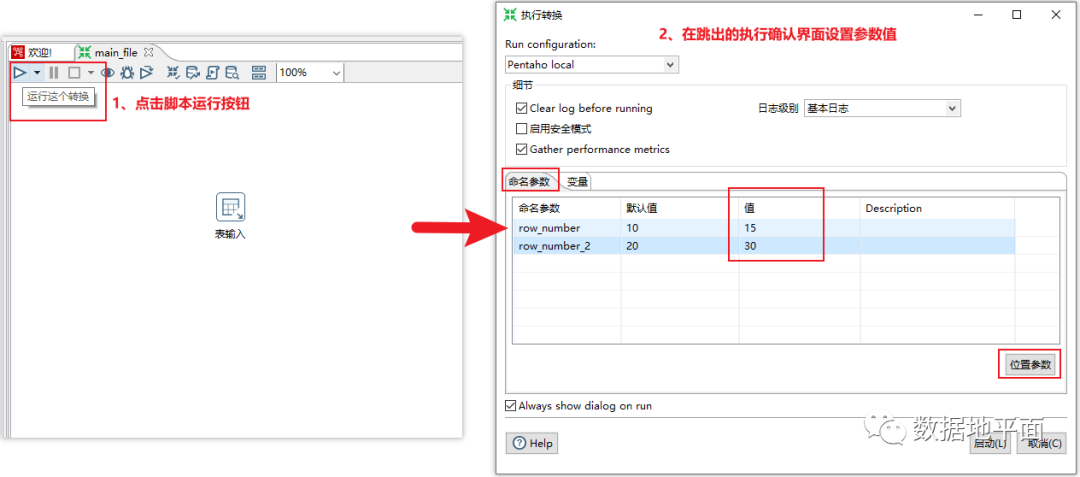
下图是一个简单的例子:通过"获取系统信息"组件设置2个位置参数,位置参数的值传递给后面的"表输入"组件,通过"?"匿名引用位置参数。
2.2 转换为变量使用
下图是一个作业文件的例子,首先使用位置参数来设置变量(前一个转换),然后再调用该变量(后一个转换)。通过把位置参数转换为变量,提升了参数值使用的灵活度。
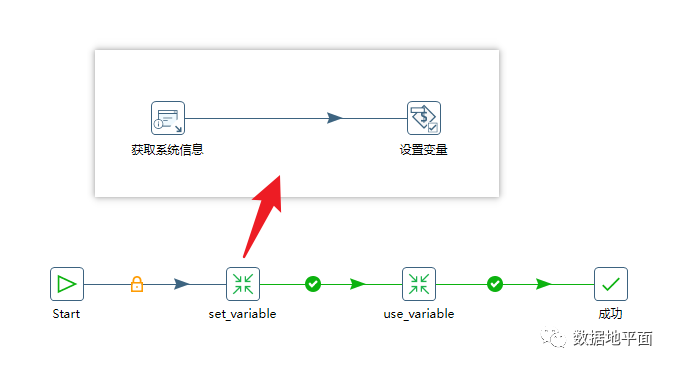
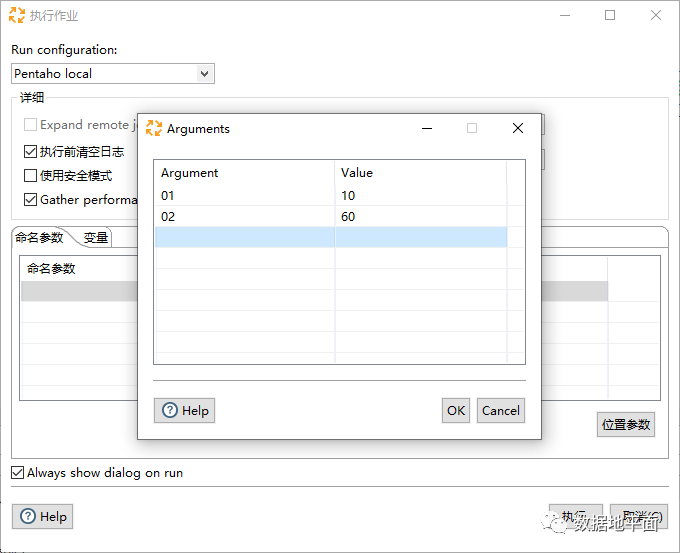
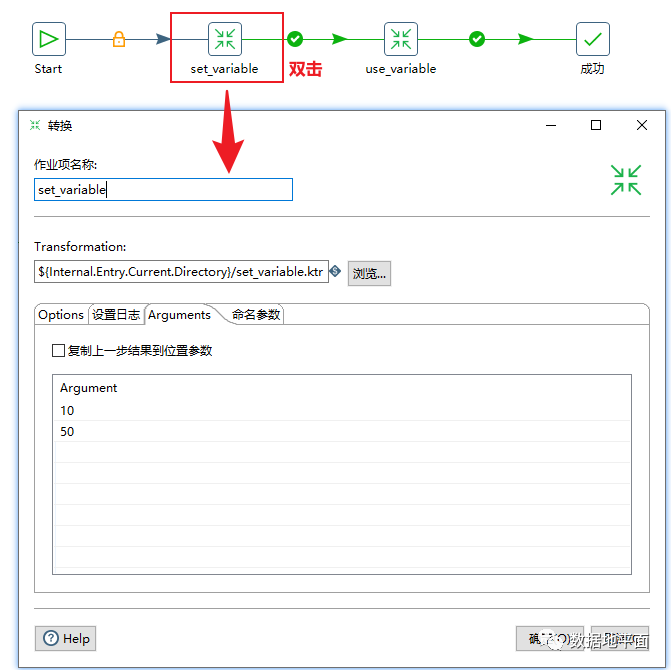
在本例中,位置参数是在转换中设置的,而该转换又是作业文件的一部分,因此位置参数的赋值有两种方式,分别是:1、在作业文件启动时赋值;2、在"转换"组件上赋值。如果两种赋值方式同时使用的话,最终第2种方式生效,即在作业文件启动时赋予的值会被覆盖。
在作业文件启动时赋值:
在"转换"组件上赋值:
3、命令行传递位置参数
下图是Windows下作业命令行举例,各部分的含义已经进行标注:

Windows下作业命令行举例:
D:cd \pdi-ce-9.2.0.0-290\data-integrationkitchen.bat /file:D:\job_file\main_file.kjb 10 30 /level:Basic > D:\job_file\main_file.log
Windows下转换命令行举例:
D:cd \pdi-ce-9.2.0.0-290\data-integrationpan.bat /file:D:\ktr_file\main_file.ktr 10 20 /level:Basic > D:\ktr_file\main_file.log
Linux下作业命令行举例:
./kitchen.sh -file=/etl_monitor/job_file/main_file.kjb 10 30 -level=Minimal >> D:\job_file\main_file.logLinux下转换命令行举例:
./pan.sh -file=/etl_monitor/ktr_file/main_file.ktr 10 30 -level=Minimal >> D:\job_file\main_file.log命名参数
1、设置命名参数
命名参数在转换文件和作业文件中均可以设置。
命名参数需要在"转换属性"或者"作业属性"里设置,操作方法基本一样。在新增命名参数时,命名参数的名称为必填项,默认值推荐填写;如果通过参数名称不太容易了解参数的业务含义,建议参数描述也填写下。以在转换脚本文件里设置为例,有两种常用的方式可以打开"转换属性"界面,如下所示:
方法1:
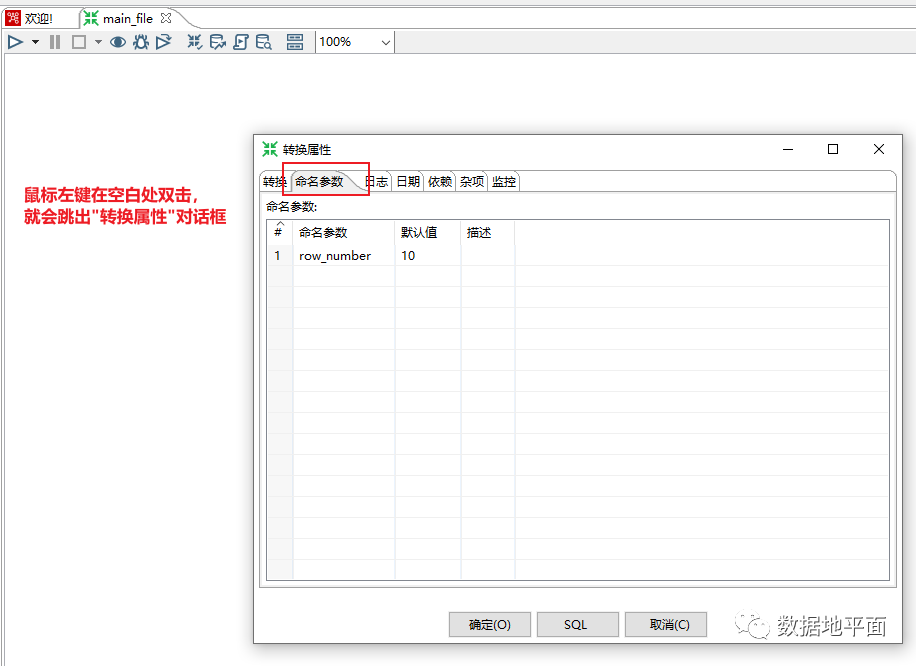
方法2:
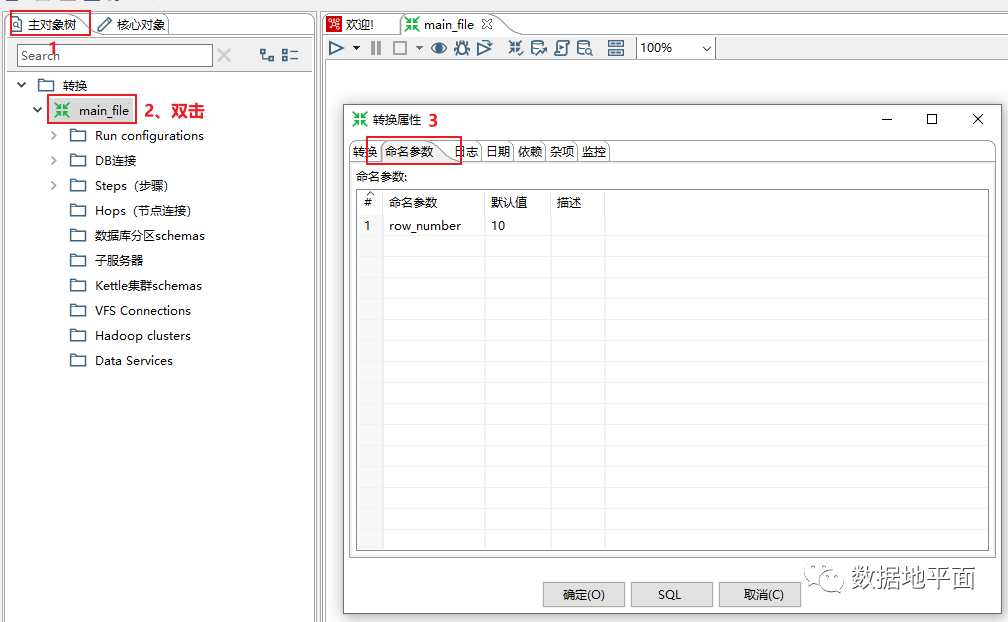
2、使用命名参数
命名参数在定义和赋值后就可以使用了,使用格式和和变量一样,为%%name%%或者${name},两者效果一样,其中name为参数的名称,Kettle默认使用${name}格式。
2.1 参数传递:父作业->子转换
默认情况下,命名参数的有效范围为当前转换或当前作业。但对于作业文件来说,在作业中定义的命名参数,是可以传递给其子转换的,只需要勾选"将所有参数值都传递到子转换"就可以了。
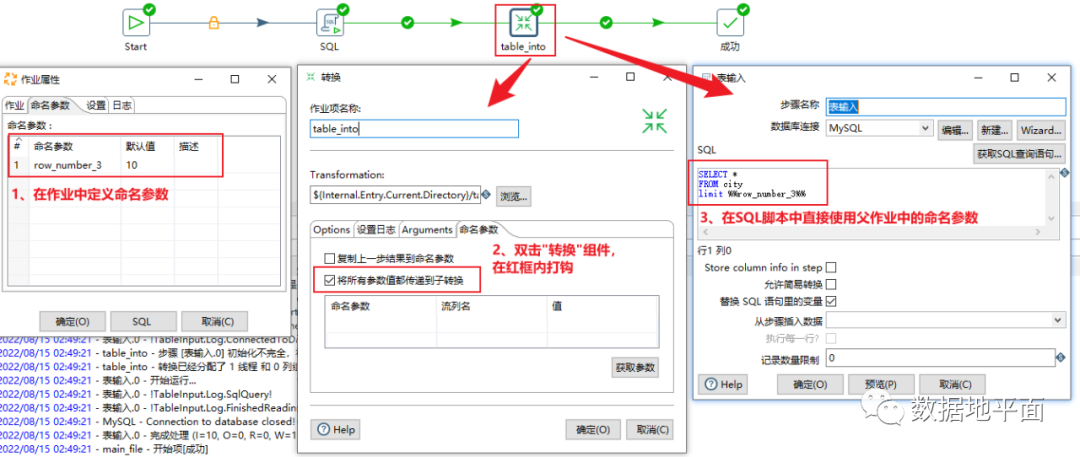
2.2 子转换中命名参数的赋值
如果在作业的子转换中有命名参数,那么如何给其赋值呢?这里总结了3种赋值方法。
方法1:使用命名参数的默认值
简单来说,就是不对子转换中的命名参数进行另外赋值,直接使用默认值。
方法2:手动填写值
这里填写的值可以是具体值(例如20或"华东"),也可以是变量和命名参数。
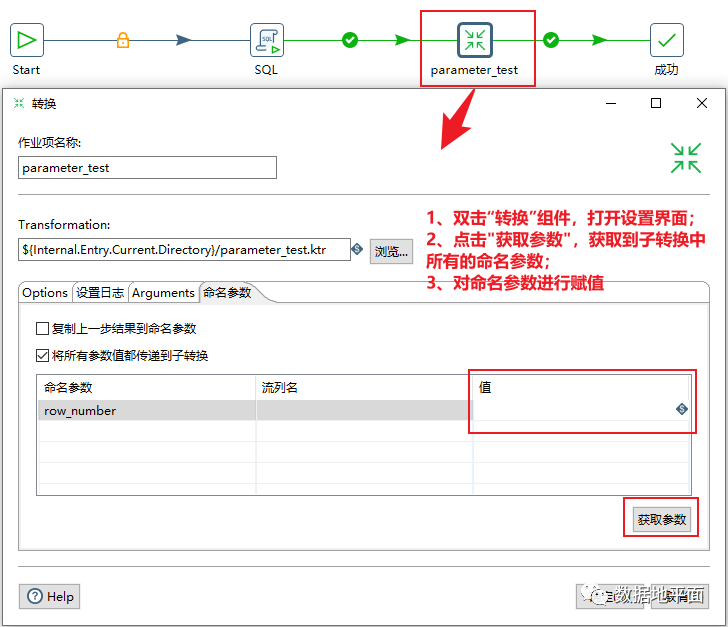
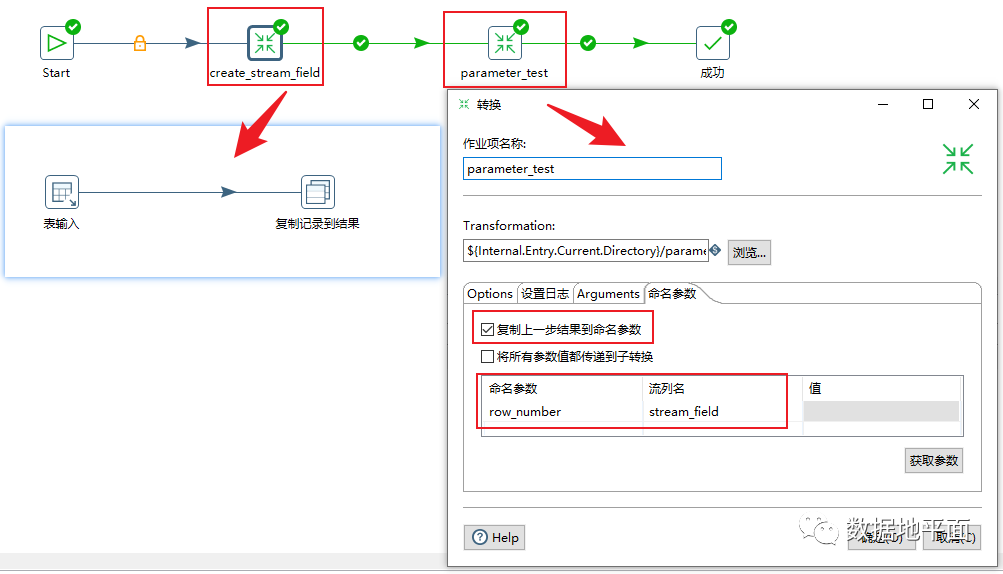
方法3:复制上一步结果到命名参数
这里需要注意的是,在上一步的子转换中需要使用"复制记录到结果"组件。
3、命令行传递命名参数
Windows下作业命令行举例:
D:cd \pdi-ce-9.2.0.0-290\data-integrationkitchen.bat /file:D:\job_file\main_file.kjb "-param:row_number=20" "-param:initialsr='B'" /level:Basic > D:\job_file\main_file.log
Windows下转换命令行举例:
D:cd \pdi-ce-9.2.0.0-290\data-integrationpan.bat /file:D:\ktr_file\main_file.ktr "-param:row_number=20" /level:Basic > D:\ktr_file\main_file.log
Linux下作业命令行举例:
./kitchen.sh -file=/etl_monitor/job_file/main_file.kjb -param:row_number=20 -param:initialsr='B' -level=Minimal >> D:\job_file\main_file.logLinux下作业命令行举例:
./pan.sh -file=/etl_monitor/ktr_file/main_file.ktr -param:row_number=20 -param:initialsr='B' -level=Minimal >> D:\job_file\main_file.log总结
本文介绍了Kettle中主要参数的使用方法,大家可以和变量的使用方法进行下对比,在实际业务中根据业务需要选择合适的实现方式。
案例中使用的数据为MySQL自带的的示例数据,对应数据库名称"sakila",MySQL安装好后登录本地库就可看到。我已经把对应的Kettle脚本文件上传到百度网盘,需要的话,请关注公众号后,回复“变量和参数”获取。
