目录
3,sendfile+Scatter/Gather(分散/收集)
零拷贝概念
零拷贝就是一种避免 CPU 将数据从一块存储拷贝到另外一块存储的技术。针对操作系统中的设备驱动程序、文件系统以及网络协议堆栈而出现的各种零拷贝技术极大地提升了特定应用程序的性能,并且使得这些应用程序可以更加有效地利用系统资源。这种性能的提升就是通过在数据拷贝进行的同时,允许 CPU 执行其他的任务来实现的。
传统IO:
在说起零拷贝就不得不谈一谈传统IO,传统的IO底层是通过read()读、write()进行写。
通过read()把数据从硬盘读到内核缓冲区,再复制到用户缓冲区;再通过write()写入到socket()缓冲区,最后写入网卡。
这里涉及到了两个概念:用户态和内核态。简单的解释一下用户空间和内核空间,用户空间指的就是用户进程的运行空间;内核空间指的是内核运行的空间。进程运行在用户空间就是用户态,进程运行在内核空间就是内核态。
为了安全起见,两种空间是进行相互隔离的,在进行拷贝时就会进行一个上下文的切换,如果是请求量较大就会频繁切换,是非常损耗性能的。
while((n = read(diskfd, buf, BUF_SIZE)) > 0)
write(sockfd, buf , n);
此时整个过程发生了4次用户态和内核态的上下文切换和4次拷贝,如流程图所示:
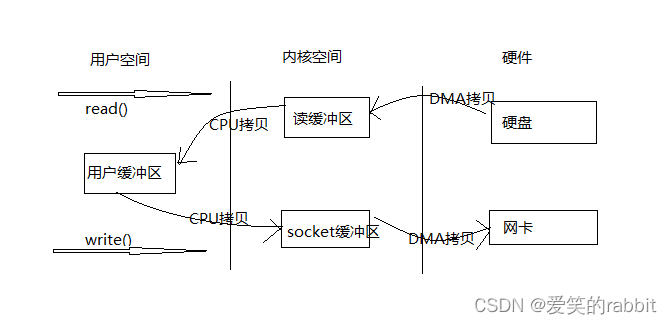
详细说一下整个过程干了些什么事,是怎样走的,虽然图显示的很明显,做了4次上下文切换与4此拷贝(2次CPU拷贝和2次DMA拷贝)还是做一下说明:
1,进程通过read()方法向系统发起调用,用户态转内核态
2,DMA控制器将硬盘数据拷贝到读缓冲区
3,CPU将读缓冲区数据拷贝到用户缓冲区,内核态转为用户态,read()结束
4,进程通过write()发起调用,用户态转为内核态
5,CPU从用户缓冲区将数据拷贝到Socket缓冲区
6,DMA从Socket缓冲区拷贝到网卡,内核态转为用户态,write()结束
什么是DMA控制器呢?
一个完整的IO过程,是通过CPU进行发起指令实施的,但是对于CPU来说,IO速度太慢了,CPU有大量的时间都在等待IO;所以就出现了DMA(Direct Memory Access,直接存储器访问),不需要依赖于CPU的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。
零拷贝
并非是没有数据拷贝的一个过程,而是通过一些技术手段去减少拷贝次数和上下文的切换。
1,mmap+write(内存映射)
实际只是说使用mmap()替换了read()而已,进行内存映射减少了1次CPU拷贝,整个过程就是4次上下文切换和3次拷贝(一次CPU拷贝和2次DMA拷贝):
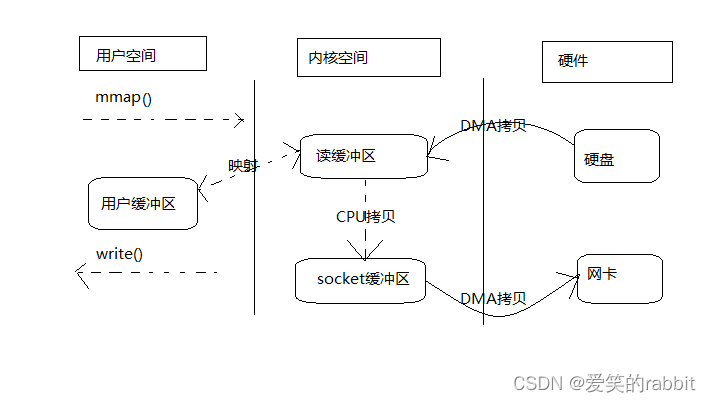
1,进程通过mmap()方法发起调用,用户态转为内核态
2,DMA将数据从硬盘拷贝到读缓冲区
3,内核态转为用户态,mmap()调用结束
4,进程通过write()发起调用,用户态转内核态
5,CPU从读缓冲区将数据拷贝到socket缓冲区
6,DMA控制器将数据从socket缓冲区拷贝到网卡设备,内核态转用户态,write()结束
内存映射的核心思想就是将内核缓存区、用户空间缓存区映射到同一个物理地址上,可以减少用户缓存区与内核缓存区之间的数据拷贝。
2,sendfile
sendfile是Linux2.1后引入的一个函数,相比较于mmap(),减少了系统调用的步骤,也就是说减少了2次上下文的切换,整个过程就是2次的上下文切换与3次拷贝(一次CPU拷贝和2次DMA拷贝):
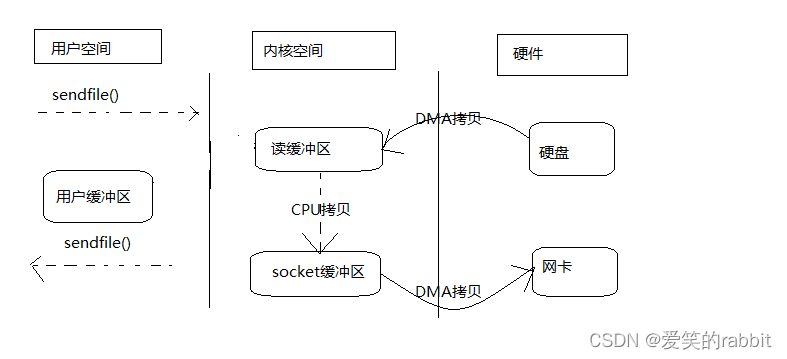
1,进程通过sendfile()发起调用,用户态转为内核态
2,DMA控制器将数据从硬盘拷贝到读缓冲区
3,CPU将数据从读缓冲区拷贝到socket缓冲区
4,DMA控制器将数据从socket缓冲区拷贝到网卡,内核态转用户态,sendfile()结束返回
3,sendfile+Scatter/Gather(分散/收集)
Linux2.4内核引入了gather机制,用以消除最后一次CPU拷贝,即不再将内核缓存区中的数据拷贝到socketbuffer,而是将内存缓存区中的内存地址、需要读取数据的长度写入到socketbuffer中,然后DMA直接根据socketbuffer中存储的内存地址,直接从内核缓存区中的数据拷贝到协议引擎(注意,这次拷贝由DMA控制)。
相比之前单独的sendfile减少了一次CPU的拷贝,CPU不参与拷贝,实现真正的零拷贝。
整个过程经历了2次上下文切换和2次拷贝(2次DMA拷贝):
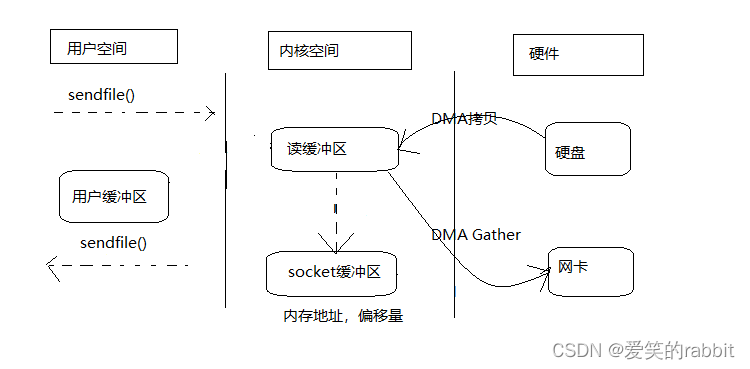
1,进程通过 sendfile()方法发起调用,上下文从用户态转向内核态
2,DMA 控制器利用 scatter 把数据从硬盘中拷贝到读缓冲区进行离散存储
3,CPU 把读缓冲区中的内存地址、偏移量发送到 socket 缓冲区
4,DMA 控制器根据内存地址、偏移量,使用 scatter/gather 把数据从内核缓冲区拷贝到网卡
总结
CPU 和 IO 速度的差异问题,产生了 DMA 技术,通过 DMA 搬运来减少 CPU 的等待时间。从传统的IO到最后CPU不参与拷贝过程,极大提高了性能,特别是在大数据量的情况下,得到了非常大的优化。
1,传统IO:整个过程经历4次上下文切换和4次拷贝(2次CPU拷贝和2次DMA拷贝)
2,mmap+write():内存映射,整个过程经历4次上下文的切换和3次拷贝(1次CPU拷贝和2次的DMA拷贝)
3,sendfile:Linux2.1内核版本支持的函数,减少系统调用,整个过程经历2次上下文切换和3次拷贝(1次CPU拷贝和2次DMA拷贝)
4,sendfile+DMA scatter/gatter:Linux2.4内核版本提供scatter/gather(分散/收集),将最后于1次的CPU拷贝替换了,实现真正意义上的零拷贝,整个过程经历2次上下文的切换和2次拷贝(2次DMA拷贝),包括从socket缓冲区存储的内存地址和偏移量获取数据这一次,也是由DMA决定的