逆向爬虫19 Scrapy增量式和分布式
一、增量式爬虫
1. 场景引入
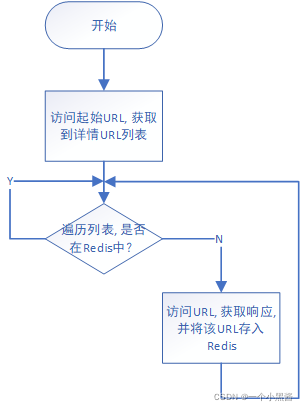
设想一个场景,你想获取一个论坛的某个板块上所有的帖子信息,但这个板块每时每刻都有可能会有新帖子被发出来。因此,每当有帖子更新,你就得启动一次爬虫爬取该板块的所有帖子数据。如果使用之前的技术来实现这个需求,会有个 问题,就是 每次板块更新时,你的爬虫程序会把当前所有的帖子都抓取一遍,里面会包含很之前爬过重复的数据。 因此我们需要设计一种新的爬虫模式,每当我们要抓取URL时,先判断一下该URL历史上有没有被抓取过,如果已经抓取过了,则跳过,若没抓过,则正常抓取它。该需求场景下设计的爬虫就是 增量式爬虫,即每次只爬取增加的数据。
2. 原理分析
从上述场景引入可知,实现这个功能的关键在于,怎么才能让爬虫在抓取URL时,知道历史上是否有抓取过。Scrapy本身的 调度器 模块具备URL去重功能,但是它仅限Scrapy一次运行之中,多次启动同一个Scrapy程序时,它无法知道上一次启动时爬取过哪些URL。因此需要考虑使用第三方工具,来帮助实现该功能。这里我们打算使用Redis来保存每次抓取过的URL信息,因为Redis工作时时存储在内存中的数据库,因此它的速度相比于MySQL,MongoDB要快很多,这里需要保存的是控制程序运行状态的标志信息,数据量远比真实要抓取的数据少,因此使用Redis既可满足速度,又能实现功能。
3. 流程框图
4. 开始动手
抓取天涯国际观察板块内的帖子数据
scrapy startproject tianya
cd tianya
scrapy genspider ty
ty.py文件
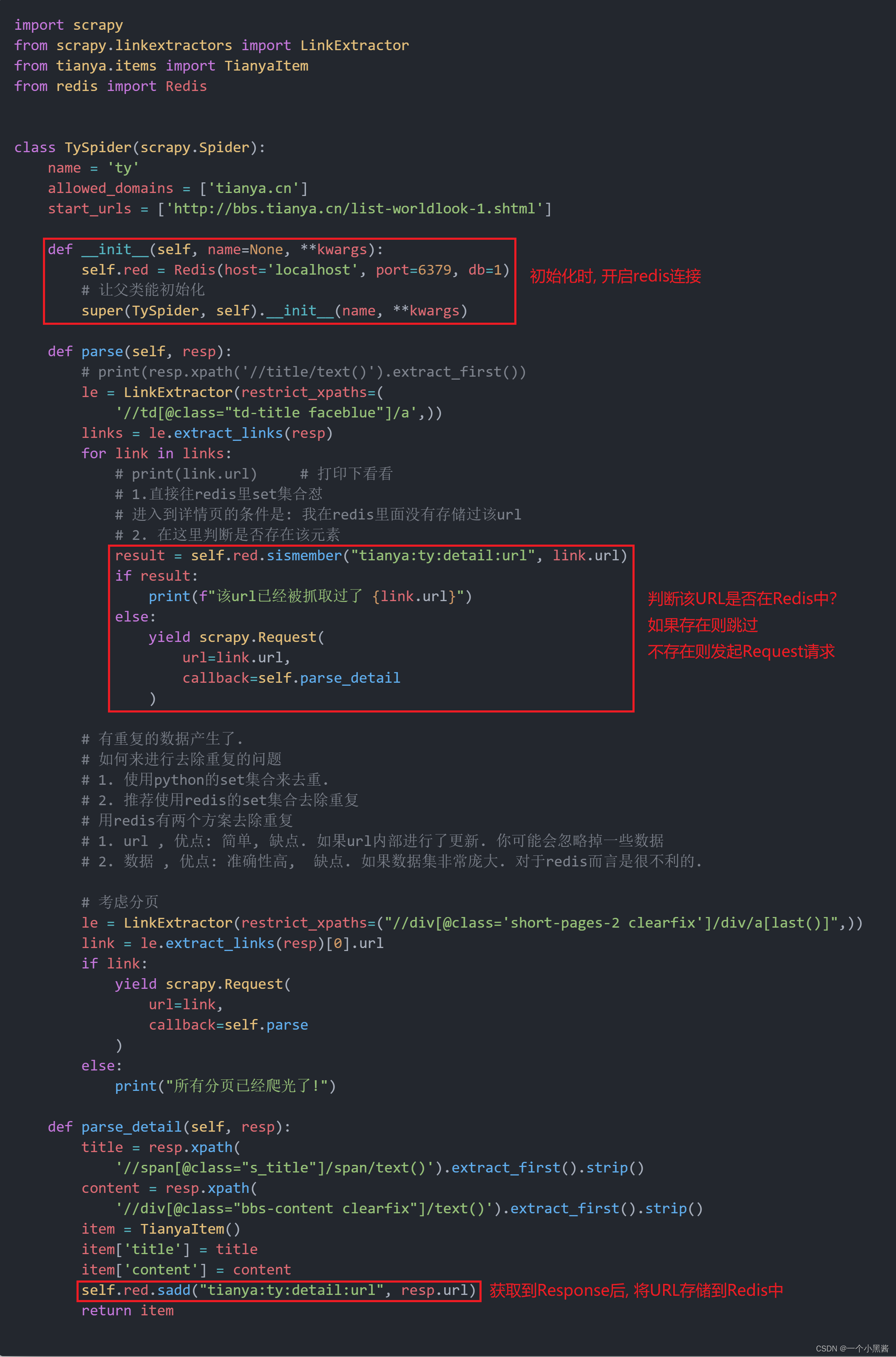
ty.py源码
import scrapy
from scrapy.linkextractors import LinkExtractor
from tianya.items import TianyaItem
from redis import Redis
class TySpider(scrapy.Spider):
name = 'ty'
allowed_domains = ['tianya.cn']
start_urls = ['http://bbs.tianya.cn/list-worldlook-1.shtml']
def __init__(self, name=None, **kwargs):
self.red = Redis(host='localhost', port=6379, db=1)
# 让父类能初始化
super(TySpider, self).__init__(name, **kwargs)
def parse(self, resp):
# print(resp.xpath('//title/text()').extract_first())
le = LinkExtractor(restrict_xpaths=(
'//td[@class="td-title faceblue"]/a',))
links = le.extract_links(resp)
for link in links:
# print(link.url) # 打印下看看
# 1.直接往redis里set集合怼
# 进入到详情页的条件是: 我在redis里面没有存储过该url
# 2. 在这里判断是否存在该元素
result = self.red.sismember("tianya:ty:detail:url", link.url)
if result:
print(f"该url已经被抓取过了 {link.url}")
else:
yield scrapy.Request(
url=link.url,
callback=self.parse_detail
)
# 有重复的数据产生了.
# 如何来进行去除重复的问题
# 1. 使用python的set集合来去重.
# 2. 推荐使用redis的set集合去除重复
# 用redis有两个方案去除重复
# 1. url , 优点: 简单, 缺点. 如果url内部进行了更新. 你可能会忽略掉一些数据
# 2. 数据 , 优点: 准确性高, 缺点. 如果数据集非常庞大. 对于redis而言是很不利的.
# 考虑分页
le = LinkExtractor(restrict_xpaths=("//div[@class='short-pages-2 clearfix']/div/a[last()]",))
link = le.extract_links(resp)[0].url
if link:
yield scrapy.Request(
url=link,
callback=self.parse
)
else:
print("所有分页已经爬光了!")
def parse_detail(self, resp):
title = resp.xpath(
'//span[@class="s_title"]/span/text()').extract_first().strip()
content = resp.xpath(
'//div[@class="bbs-content clearfix"]/text()').extract_first().strip()
item = TianyaItem()
item['title'] = title
item['content'] = content
self.red.sadd("tianya:ty:detail:url", resp.url)
return item
piplines.py源码(保存数据到MySQL,用于和Redis中保存的URL数量对比是否一致)
from itemadapter import ItemAdapter
import pymysql
from tianya.settings import MYSQL
class TianyaPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(
host=MYSQL['host'],
port=MYSQL['port'],
user=MYSQL['user'],
password=MYSQL['password'],
database=MYSQL['database']
)
def close_spider(self, spider):
if self.conn:
self.conn.close()
def process_item(self, item, spider):
print(item['title'], item['content'])
try:
cursor = self.conn.cursor()
sql = "insert into ty (title, content) values (%s, %s)"
cursor.execute(sql, (item['title'], item['content']))
self.conn.commit()
except:
self.conn.rollback()
finally:
if cursor:
cursor.close()
return item
5. 小结
增量式爬虫比较简单,就是在爬取之前和爬取之后,增加了数据库操作,这里可以把Redis换成其他任意数据库。
二、分布式爬虫
1. 什么是分布式爬虫?
分布在不同区域的多台计算机(公网IP不同)联合起来完成同一个爬虫任务的爬虫程序叫分布式爬虫。
2. 为什么要分布式爬虫?
单台计算机的能力是有限的,当我们希望可以更快地完成某些爬虫任务时,可以考虑使用分布式爬虫。
3. 原理分析
之前我们写的都是单机爬虫程序,我们只能控制一个Scrapy程序对某个网站进行爬取,现在我们希望可以在多个不同的计算机上运行Scrapy程序来完成爬虫工作。试想一下我们会遇到什么问题?
由于我们每个Scrapy程序时独立的,因此不同的程序之间会爬取到重复的数据,这样即使架好集群,也无法发挥出多台计算机并行爬取网站的优势。因此我们必须让不同的Scrapy程序可以对不同的URL发起请求,如何才能实现这个功能呢?我们需要回到Scrapy的工作流程,对 调度器 的工作原理做进一步的研究。
单机程序下,Scrapy 调度器 从 爬虫 这里获取到start_url的request请求,再交给 下载器 ,由 下载器 对目标URL进行HTTP请求。现在我们希望多台计算机联合起来工作,如果每台计算机拥有自己各自的 调度器 的话,相互之间就没有任何关联,自顾自地调度URL地分配。因此考虑将多台计算机地Scrapy程序的调度器统一起来,由一台机器来负责 调度 分配URL,剩下的机器负责下载,解析,以及存储。
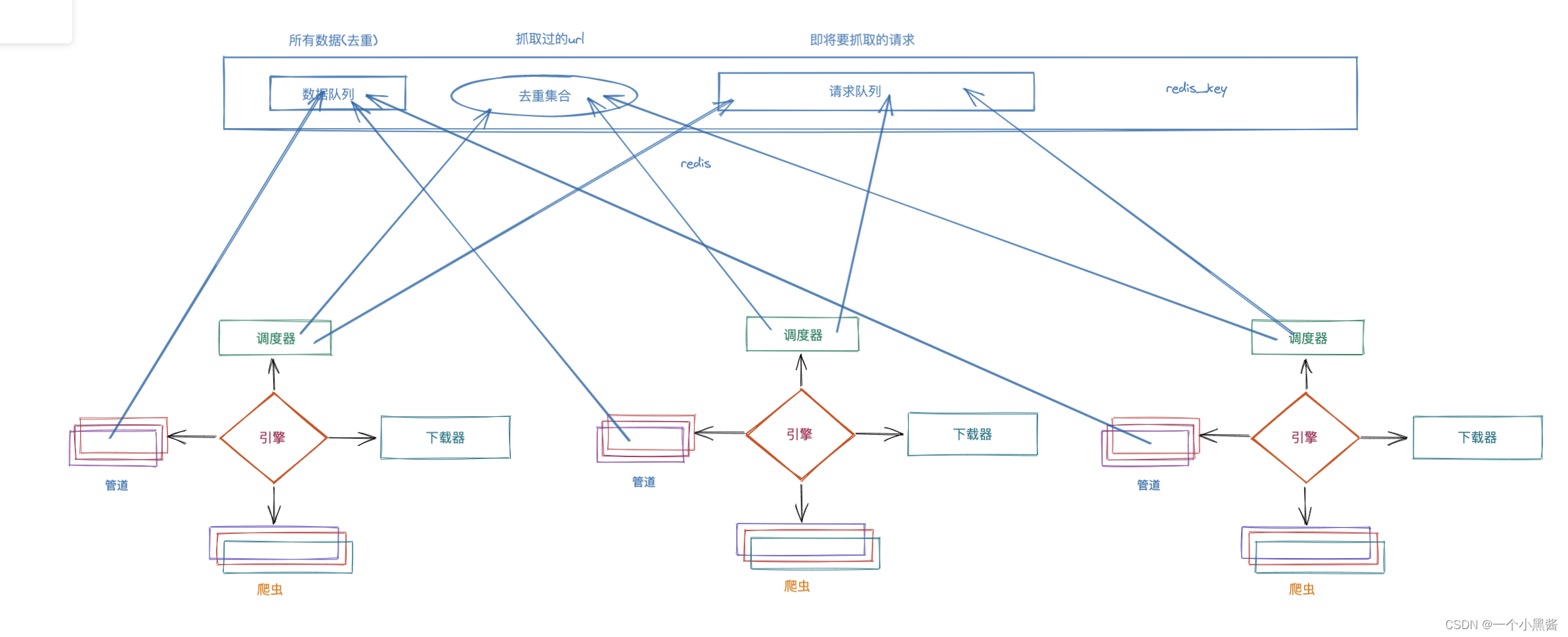
上图是Scrapy分布式爬虫的原理图,上方的蓝色长方形就是负责给所有其他计算机分配URL的 调度器,里面包含四个东西:
- 去重集合,和单机版Scrapy一样,用于过滤掉重复的URL。
- 请求队列,其它所有计算机共享一个请求队列,因此相互不会抓重复的数据。
- redis_key,和单机版程序中的start_urls是一个意思,用于给分布式爬虫指定起始URL的。
- 数据队列 (可选),方便数据整合,如果没有则数据分布在每个计算机之上,后期需要手动整合。
总的来说,分布式爬虫就是把调度器分离出去,一般我们用Scrapy_redis来做这个调度器,剩下的部分都可以不变。
4. 开始动手
目标依然是天涯国际观察板块内的帖子数据,因此没有贴出来的文件都是一样的
scrapy startproject tianya2
cd tianya2
scrapy genspider ty
ty.py文件
settings.py文件
ty.py源码
import scrapy
from scrapy_redis.spiders import RedisSpider, RedisCrawlSpider
from scrapy.linkextractors import LinkExtractor
from tianya2.items import TianyaItem
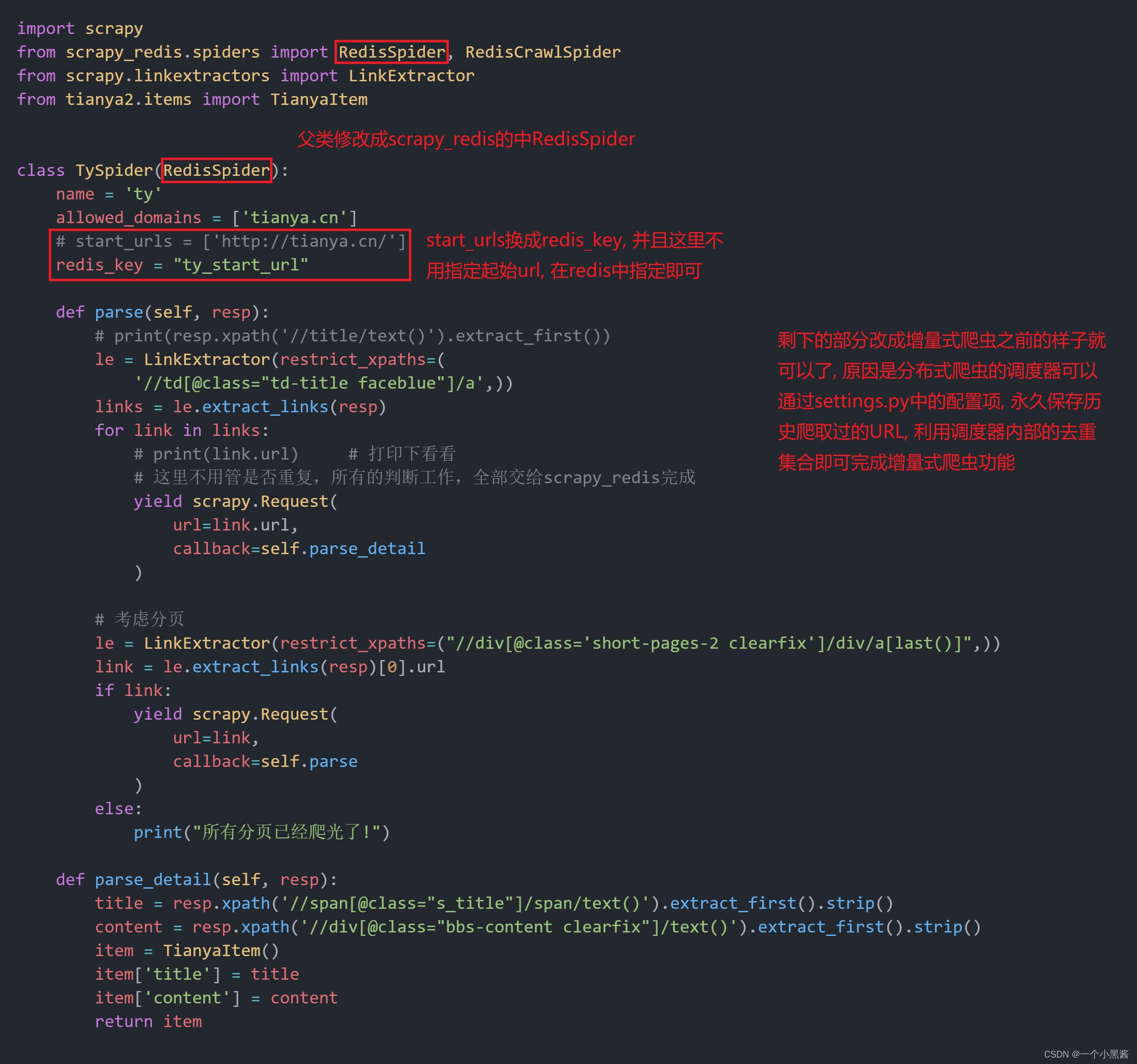
class TySpider(RedisSpider):
name = 'ty'
allowed_domains = ['tianya.cn']
# start_urls = ['http://tianya.cn/']
redis_key = "ty_start_url"
def parse(self, resp):
# print(resp.xpath('//title/text()').extract_first())
le = LinkExtractor(restrict_xpaths=(
'//td[@class="td-title faceblue"]/a',))
links = le.extract_links(resp)
for link in links:
# print(link.url) # 打印下看看
# 这里不用管是否重复,所有的判断工作,全部交给scrapy_redis完成
yield scrapy.Request(
url=link.url,
callback=self.parse_detail
)
# 考虑分页
le = LinkExtractor(restrict_xpaths=("//div[@class='short-pages-2 clearfix']/div/a[last()]",))
link = le.extract_links(resp)[0].url
if link:
yield scrapy.Request(
url=link,
callback=self.parse
)
else:
print("所有分页已经爬光了!")
def parse_detail(self, resp):
title = resp.xpath('//span[@class="s_title"]/span/text()').extract_first().strip()
content = resp.xpath('//div[@class="bbs-content clearfix"]/text()').extract_first().strip()
item = TianyaItem()
item['title'] = title
item['content'] = content
return item
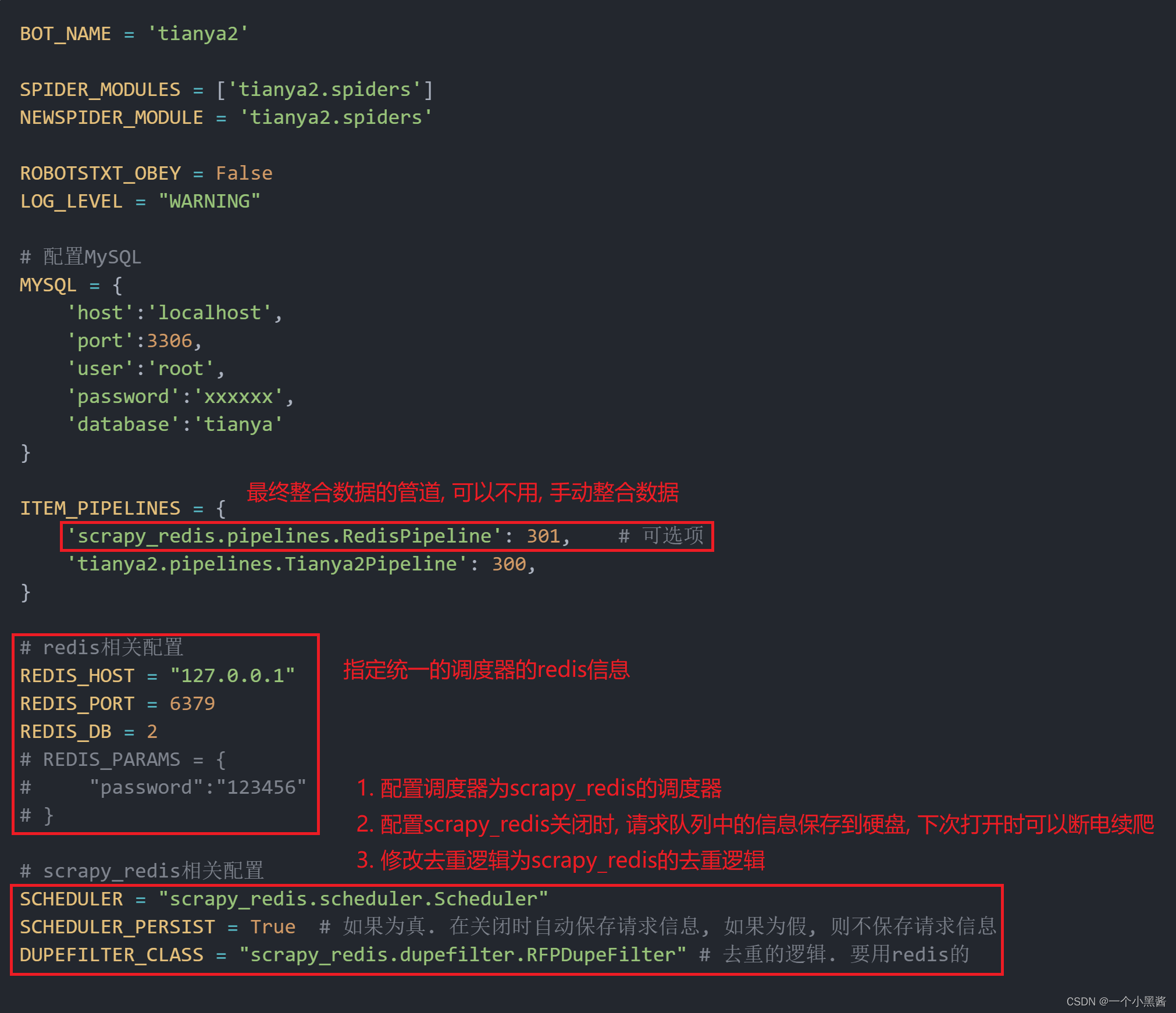
settings.py源码
BOT_NAME = 'tianya2'
SPIDER_MODULES = ['tianya2.spiders']
NEWSPIDER_MODULE = 'tianya2.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
# 配置MySQL
MYSQL = {
'host':'localhost',
'port':3306,
'user':'root',
'password':'xxxxxx',
'database':'tianya'
}
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 301, # 可选项
'tianya2.pipelines.Tianya2Pipeline': 300,
}
# redis相关配置
REDIS_HOST = "127.0.0.1"
REDIS_PORT = 6379
REDIS_DB = 2
# REDIS_PARAMS = {
# "password":"123456"
# }
# scrapy_redis相关配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # 如果为真. 在关闭时自动保存请求信息, 如果为假, 则不保存请求信息
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 去重的逻辑. 要用redis的
启动程序
开启三个命令行终端,两个输入Scrapy crawl ty
一个进入redis指定redis_key
PS C:\Users\Apphao> redis-cli
127.0.0.1:6379> select 2
OK
127.0.0.1:6379[2]> lpush ty_start_url http://bbs.tianya.cn/list-worldlook-1.shtml
(integer) 1
127.0.0.1:6379[2]>
指定好redis_key后另外两个终端就会联合爬取目标网站了
5. 小结
利用Scrapy_redis来完成Scrapy中的 调度器 的工作,在传统单机Scrapy程序上增加了3个功能。
- 增量式爬虫
- 断点续爬
- 分布式爬虫
修改代码的地方很少,大部分是在配置的文件中。