在机器学习中情感分析的5种方法
情感分析:用于确定给定文本的情感或观点。
情感分析模型可以通过从自然语言中提取意义并将其分配分数来预测给定文本数据是正的、负的还是中性的。
现介绍开发或介绍情绪分析模型的5种方法:
1. 定制训练监督模型:
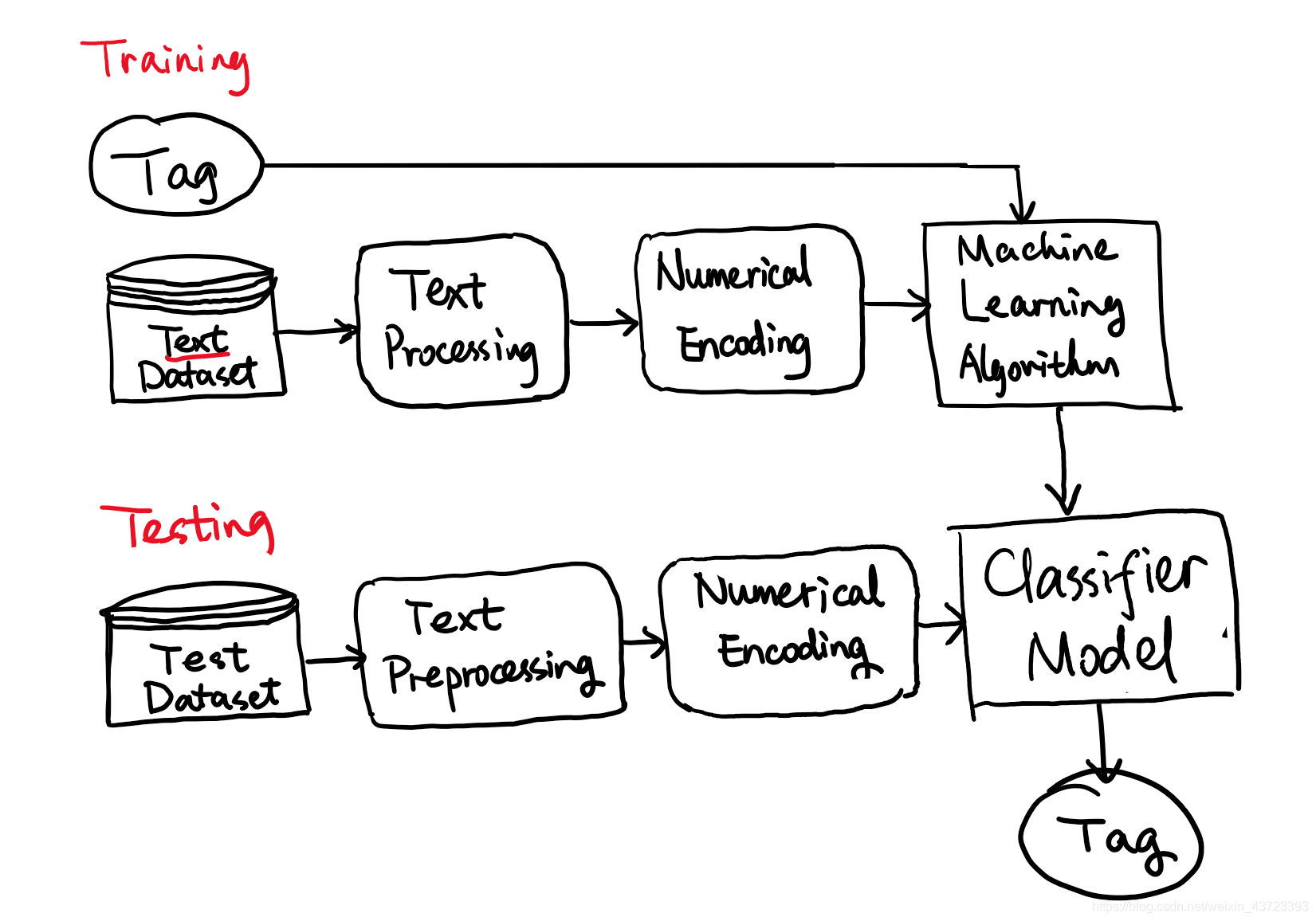
我们可以训练一个定制的机器学习或深度学习情感分析模型。一个有标记的数据集是训练一个健壮的ML模型的关键。ML模型将学习数据级中的各种模式,并能预测文本的情感。
要训练自定义情绪分析模型,必须遵循以下步骤:
- 收集原始标记数据集进行情绪分析
- 文本预处理
- 文本的数字编码
- 选择合适的ML算法
- 调参与训练ML模型
- 预测
具体模型的设计框图如下图所示:
2.TextBlob
TextBlob是一个开源的Python库,用于处理文本数据,允许在其简单的API框架下指定要使用的算法。
TextBlobs的API可以用来执行诸如词性标注、名词短语提取、分类、翻译、情感分析等任务。
对于情感分析,TextBlob库提供了两种实现:
- patternalyzer:(默认)基于模式库
- NaiveBayesAnalyzer:一个基于电影评论语料库的NLTK分类器。
安装
pip install -U textblob
实施
from textblob import TextBlob
from textnlob.sentiments import NaiveBayesAnalyzer,PatternAnalyzer
text = 'I like the movie, the actors performance was too good.'
# NaiveBayesAnalyzer
blob = TextBlob(text, analyzer = NaiveBayesAnalyzer())
print(blob.sentiment)
# PatternAnalyzer
blob = TextBlob(text, analyzer = PatternAnalyzer())
print(blob.sentiment)
3. 基于词典的模型
基于词典的模型涉及到从文本语料库中创建一个n − g r a m n-gramn−gram的正负词典。
该方法需要一个带标签的文本语料库,并使用自定义python函数分别为正文本和负文本创建一个n − g r a m n-gramn−gram词典。
自定义词也可以添加到字典的基础上领域知识,作为一个额外的优势。
在下一步中,创建一个自定义函数,该函数可以使用上面形成的正负词典来分析给定的输入文本,并可以将其分类为正面情绪或负面情绪。
- 输入文本中的每个积极词都会增加情感得分,而消极词则会减少情感得分。
- 将最后的情绪分数除以该文本中的字数,以使分数标准化。
积极情绪得分介于0 00和1 11之间,表示积极情绪,其中1表示100%置信度的积极情绪预测。
负面情绪得分在− 1 -1−1和0 00之间,其中,− 1 -1−1是100%置信度的负面情绪预测。
实施
import ntlk
pos_words = []
ned_words = []
def compute_sentiment_score(text):
sentiment_score = 0
words = ntlk.word_tokenize(text)
for word in words:
if word in pos_words:
print('pos:',word)
sentiment_score = sentiment_score + 1
if word in neg_words:
print('neg:',word)
sentiment_score = sentiment_score - 1
return sentiment_score/len(words)
with open('datapath') as file:
for line in file:
line_attrib = line.spilt()
word = line_attrib[2].spilt('=')[1] #3nd column in the file
polarity = line_attrib[-1].spilt('=')[1] #last column in the file
if polarity == 'positive':
pos_words.append(word)
if polarity == 'negative':
neg_words.append(word)
print('Total positive words found: ',len(pos_words))
print('Total negative words found: ',len(neg_words))
text = 'I love the movie, the actors performance was mindblowing.'
sentiment = compute_sentiment_score(text)
print('The sentiment score of this twxt is: {:.2f}'.format(sentiment))
4. BERT
BERT代表来自Google开发的Transformers的双向编码器表示,它是用于NLP任务的最先进的ML模型。
要使用BERT 训练情感分析模型,请执行以下步骤:
- 安装 Transformer库
- 加载 BERT分类器和标记器
- 创建已处理的数据级
- 配置和训练加载的BERT模型,并对其超参数进行微调
- 进行情绪分析预测
实现
按照下面提到的文章使用BERT实现情绪分析模型。
5.基于命名实体的情感分析器
基于命名实体的情感分析器主要针对实体词或重要词。也可以称为目标情绪分析,他只关注重要的词语或实体,比上述三种方法更精确,更有用。
- 第一步是在文本语料库中找到所有命名实体
- 在文本上应用名称实体识别来查找各种实体,如PERSON、ORG、GPE。
- 基于命名实体的情感分析
- 以找到包含命名实体的句子为目标,只对这些句子逐一进行情感分析。