Faster R-CNN Keras版源码史上最详细解读系列之数据解析
数据解析
我们可以在train_frcnn.py中看到数据解析的部分:
# 上面说的解析参数使用的不同方式
if options.parser == 'pascal_voc':
from keras_frcnn.pascal_voc_parser import get_data
elif options.parser == 'simple':
from keras_frcnn.simple_parser import get_data
else:
raise ValueError("Command line option parser must be one of 'pascal_voc' or 'simple'")
有两种方式,一种是voc格式,一种是简易的,其实原理一样的,就是解析文件,voc是用xml解析,简易的就是用逗号分隔符分割,具体来看看源码吧。
pascal_voc_parser.py
在keras_frcnn下的pascal_voc_parser.py就是解析voc数据的,传入的是训练集的路径,输出的是所有图片的标签数据,类别个数,以及类别和索引的映射。
import os
import cv2
import xml.etree.ElementTree as ET
import numpy as np
'''
从voc的xml中读取信息
'''
def get_data(input_path):
'''
:param input_path: 数据集路径
:return:所有图片标注信息,类别数量映射,类别索引映射
'''
# 所有图片标注信息
all_imgs = []
# 类别名字统计字典
classes_count = {}
# 类别名字和序号的映射
class_mapping = {}
visualise = False
# 可以是多个数据集,放在列表里,可以拼起来,比如input_path=d:/pascal 则路径为d:/pascal/voc2007,d:/pascal/voc2012,当然可以直接写文件夹,那就不用拼路径了
# data_paths = [os.path.join(input_path,s) for s in ['VOC2007']]
data_paths = [os.path.join(input_path,s) for s in ['']]
print('Parsing annotation files')
for data_path in data_paths:
'''
获取标注文件夹,图片文件夹,还有训练验证集和测试集的路径
'''
annot_path = os.path.join(data_path, 'Annotations')
imgs_path = os.path.join(data_path, 'JPEGImages')
imgsets_path_trainval = os.path.join(data_path, 'ImageSets','Main','trainval.txt')
imgsets_path_test = os.path.join(data_path, 'ImageSets','Main','test.txt')
trainval_files = []
test_files = []
try:
with open(imgsets_path_trainval) as f:
for line in f:
# strip()可去除换行
trainval_files.append(line.strip() + '.jpg')
except Exception as e:
print(e)
try:
with open(imgsets_path_test) as f:
for line in f:
test_files.append(line.strip() + '.jpg')
except Exception as e:
if data_path[-7:] == 'VOC2012':
# this is expected, most pascal voc distibutions dont have the test.txt file
pass
else:
print(e)
# 标注xml的列表
annots = [os.path.join(annot_path, s) for s in os.listdir(annot_path)]
idx = 0
for annot in annots:
try:
idx += 1
et = ET.parse(annot)
element = et.getroot()
# 找到所有物体标签
element_objs = element.findall('object')
element_filename = element.find('filename').text
element_width = int(element.find('size').find('width').text)
element_height = int(element.find('size').find('height').text)
if len(element_objs) > 0:
# 有物体信息就添加到标注数据中
annotation_data = {'filepath': os.path.join(imgs_path, element_filename), 'width': element_width,
'height': element_height, 'bboxes': []}
if element_filename in trainval_files:
annotation_data['imageset'] = 'trainval'
elif element_filename in test_files:
annotation_data['imageset'] = 'test'
else:
annotation_data['imageset'] = 'trainval'
for element_obj in element_objs:
class_name = element_obj.find('name').text
# 统计类别数量
if class_name not in classes_count:
classes_count[class_name] = 1
else:
classes_count[class_name] += 1
# 建立类别和序号的映射
if class_name not in class_mapping:
class_mapping[class_name] = len(class_mapping)
# 物体信息边框 左上角和右下角
obj_bbox = element_obj.find('bndbox')
x1 = int(round(float(obj_bbox.find('xmin').text)))
y1 = int(round(float(obj_bbox.find('ymin').text)))
x2 = int(round(float(obj_bbox.find('xmax').text)))
y2 = int(round(float(obj_bbox.find('ymax').text)))
difficulty = int(element_obj.find('difficult').text) == 1
annotation_data['bboxes'].append(
{'class': class_name, 'x1': x1, 'x2': x2, 'y1': y1, 'y2': y2, 'difficult': difficulty})
all_imgs.append(annotation_data)
# 是否要可视化看看标注框对不对
if visualise:
img = cv2.imread(annotation_data['filepath'])
for bbox in annotation_data['bboxes']:
cv2.rectangle(img, (bbox['x1'], bbox['y1']), (bbox[
'x2'], bbox['y2']), (0, 0, 255))
cv2.imshow('img', img)
cv2.waitKey(0)
except Exception as e:
print(e)
continue
return all_imgs, classes_count, class_mapping
整个过程就是先读取训练验证集合测试集的文件,做好哪些文件是训练的,验证的,或者测试的分类,然后解析所有的标注xml文件,读取里面需要用的信息,特别是标注出来的物体的类型和坐标,然后统计类别的数量classes_count,做类别索引映射class_mapping。你会发现xml里没有标注背景的类别,没事,后面会处理。
simple_parser.py
另一个简易的解析我也贴下代码吧,其实差不多思路的,只是有些参数没用到,比如difficult,不过对于目标检测来说够用了:
import cv2
import numpy as np
'''
从csv中读取,格式应该就是这样 filename,x1,y1,x2,y2,class_name
'''
def get_data(input_path):
found_bg = False
all_imgs = {}
classes_count = {}
class_mapping = {}
visualise = True
with open(input_path, 'r') as f:
print('Parsing annotation files')
for line in f:
# 分割取信息
line_split = line.strip().split(',')
(filename, x1, y1, x2, y2, class_name) = line_split
if class_name not in classes_count:
classes_count[class_name] = 1
else:
classes_count[class_name] += 1
if class_name not in class_mapping:
if class_name == 'bg' and found_bg == False:
# 背景类,为了难例挖掘
print(
'Found class name with special name bg. Will be treated as a background region (this is usually for hard negative mining).')
found_bg = True
class_mapping[class_name] = len(class_mapping)
if filename not in all_imgs:
all_imgs[filename] = {}
# 这里采用了去读图片信息来作为宽和高
img = cv2.imread(filename)
(rows, cols) = img.shape[:2]
all_imgs[filename]['filepath'] = filename
all_imgs[filename]['width'] = cols
all_imgs[filename]['height'] = rows
all_imgs[filename]['bboxes'] = []
if np.random.randint(0, 6) > 0:
# 比例5/6作为训练验证集
all_imgs[filename]['imageset'] = 'trainval'
else:
all_imgs[filename]['imageset'] = 'test'
all_imgs[filename]['bboxes'].append(
{'class': class_name, 'x1': int(float(x1)), 'x2': int(float(x2)), 'y1': int(float(y1)),
'y2': int(float(y2))})
all_data = []
# 字典放入列表中
for key in all_imgs:
all_data.append(all_imgs[key])
# make sure the bg class is last in the list
# 确保背景类是最后的
if found_bg:
if class_mapping['bg'] != len(class_mapping) - 1:
#找出class_mapping中序号为最大的那个key,和bg的序号做交换 ,使得背景的序号始终是最大的,为class_mapping长度-1
key_to_switch = [key for key in class_mapping.keys() if class_mapping[key] == len(class_mapping) - 1][0]
val_to_switch = class_mapping['bg']
class_mapping['bg'] = len(class_mapping) - 1
class_mapping[key_to_switch] = val_to_switch
return all_data, classes_count, class_mapping
只是他考虑了可能有背景类别,有的话最后把他交换到类别索引映射的最后,为什么要这么做呢,以便后面有地方可以快速获取,判断是不是背景,后面会讲到。那没考虑背景这么办呢,train_frcnn.py源码里有考虑啦:
#获取图片信息,包括名字,位置,大小,获取类别和对应的数量,获取类别名字和序号的映射
all_imgs, classes_count, class_mapping = get_data(options.train_path)
#如果没有背景就加一个背景类
if 'bg' not in classes_count:
classes_count['bg'] = 0
class_mapping['bg'] = len(class_mapping)
看下三个返回值的数据,方便代码理解:

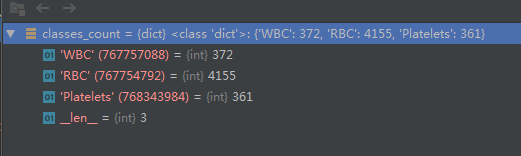
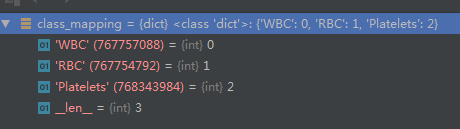
不讲太多,慢慢来,太多了不好消化,写太长了看了也烦,后面继续更新。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。
版权声明:本文为wangwei19871103原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。