如果你对Levenshtein和Difflib相似性的快速视觉比较感兴趣,我计算了大约230万本书的书名:import codecs, difflib, Levenshtein, distance
with codecs.open("titles.tsv","r","utf-8") as f:
title_list = f.read().split("\n")[:-1]
for row in title_list:
sr = row.lower().split("\t")
diffl = difflib.SequenceMatcher(None, sr[3], sr[4]).ratio()
lev = Levenshtein.ratio(sr[3], sr[4])
sor = 1 - distance.sorensen(sr[3], sr[4])
jac = 1 - distance.jaccard(sr[3], sr[4])
print diffl, lev, sor, jac
然后用R绘制结果:
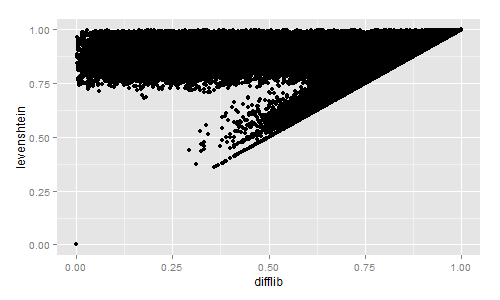
出于好奇,我还比较了Difflib、Levenshtein、Sørensen和Jaccard的相似性值:library(ggplot2)
require(GGally)
difflib
colnames(difflib)
ggpairs(difflib)
结果:
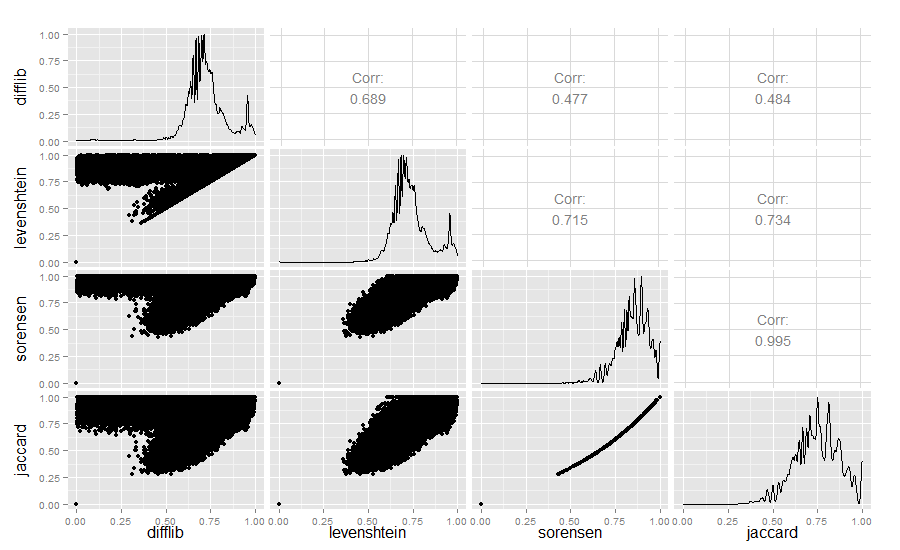
Difflib/Levenshtein的相似性真的很有趣。
2018年编辑:如果你正在识别类似的字符串,你也可以查看minhashing——有一个great overview here。Minhashing在线性时间内发现大型文本集合中的相似性是令人惊奇的。我的实验室组装了一个应用程序,可以使用minhashing在这里检测和可视化文本重用:https://github.com/YaleDHLab/intertext