目录
之前已经给大家介绍了OrionX赋能深度学习分布式训练的相关知识OrionX(猎户座)AI加速器资源池化软件赋能深度学习分布式训练,了解了分布式训练在AI场景下发挥的重大作用,目前无论是深度学习主流框架(如TensorFlow, PyTorch, PaddlePaddle, MXNet等),还是分布式训练工具(Horovod, DeepSpeed)都是在不断尝试突破和优化AI分布式训练算法,以满足更大规模、更复杂场景的模型高效训练需求。
聊到AI分布式训练,应该了解一下其背后的原理。其实分布式概念并不是近十年AI大发展过程中提出,更早的HPC和大数据领域都已经在分布式计算领域输出了大量实践和成果,但由于目前AI算法特殊的前向和反向计算机制,对分布式算法提出了更高难度的挑战,AI分布式算法吸取前人经验,走出了一条独特的创新之路。
AI分布式算法有哪些思想?
目前主流的AI分布式算法分为两大类,分别是Parameter Server和Ring Allreduce:
- Parameter Server(参数服务器):参数服务器是一个编程框架,用于方便分布式并行程序的编写,其中重点在于对大规模参数的分布式存储和协同的支持。参数服务器概念最早来自于Alex Smola于2010年提出的并行LDA的框架。后来由Google的Jeff Dean进一步提出了第一代Google大脑的解决方案:DistBelief。再之后由MXNet作者,AWS首席科学家李沐在2014年提出第三代参数服务器思想,论文为《Parameter Server for Distributed Machine Learning》
- Ring Allreduce(环行归约):Allreduce归约概念很早就诞生于并行计算领域,在HPC经常使用的MPI(Message-Passing Interface,消息传递接口)标准中就有常见的接口MPI_Allreduce。后来2016年百度硅谷人工智能实验室(SVAIL)首次将Ring Allreduce算法引入到深度学习中,开启了AI分布式训练新的篇章,后续Nvidia的NCCL,Uber开源的Horovod,PyTorch的DDP都是基于Ring Allreduce思想不断演进发展的实现方式。
Parameter Server算法
Parameter Server框架中,计算节点被分成两种:server和worker。
- server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数。
- worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。worker只和server通信,互相之间没有通信。
如下图所示:

图1:Parameter Server结构
*From[1]“Horovod: fast and easy distributed deep learning in TensorFlow”
举一个具体例子,如下图所示,GPU 0~3卡负责网络参数的训练,每个卡上都布置了相同的深度学习网络,每个卡都分配到不同的数据的minibatch。每张卡训练结束后将网络参数同步到GPU 0,也就是Reducer这张卡上,然后再求参数变换的平均下发到每张计算卡,整个流程有点像MapReduce的原理。
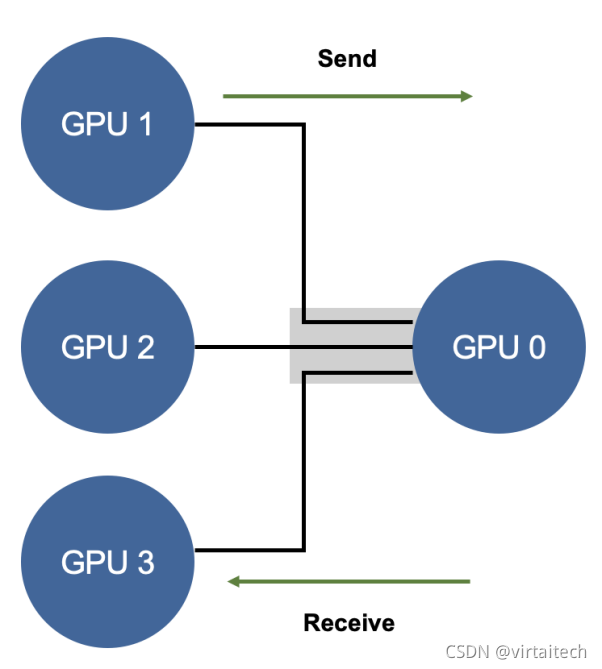
图2:Parameter Server通信流程
PS算法的通信成本为:
N:GPU个数
K:通信一次完整的参数所需时间
这里面就涉及到了两个问题:
问题一:每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束。如果卡数比较少的情况下影响不大,但是如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
问题二:每次迭代所有的计算GPU卡都需要针对全部的模型参数跟Reduce卡进行通信,如果参数的数据量大的时候,那么这种通信开销也是非常庞大,而且这种开销会随着卡数的增加而线性增长。
为了解决上述问题,就引入了另一种通信算法思想:Ring Allreduce。
Ring Allreduce算法
Ring Allreduce通过将GPU卡的通信模式拼接成一个环形,从而减少随着卡数增加而带来的资源消耗,如下图所示:
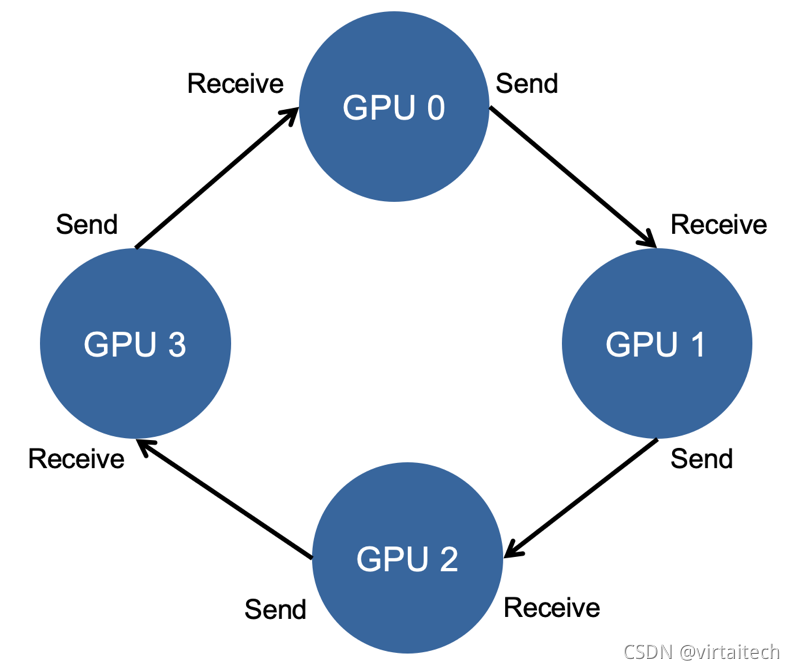
图3:Ring Allreduce通信流程
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
算法主要分两步:
1. scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
2. allgather:GPU会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
我们通过实际例子看一下:
准备阶段:将每个GPU节点分配的参数进行划分,划分的份数为GPU节点数N。
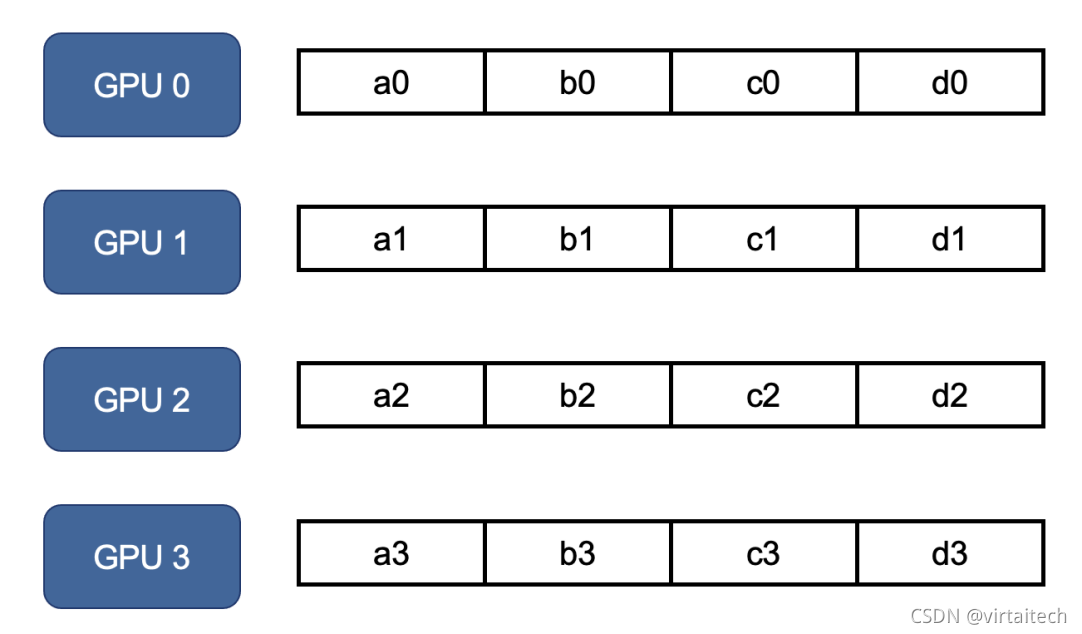
图4:Ring Allreduce数据准备
第一步:执行scatter-reduce。
第一轮GPU 0上的a0传递给GPU 1上a1并相加,GPU 1上的b1传递给GPU 2上的b2并相加。
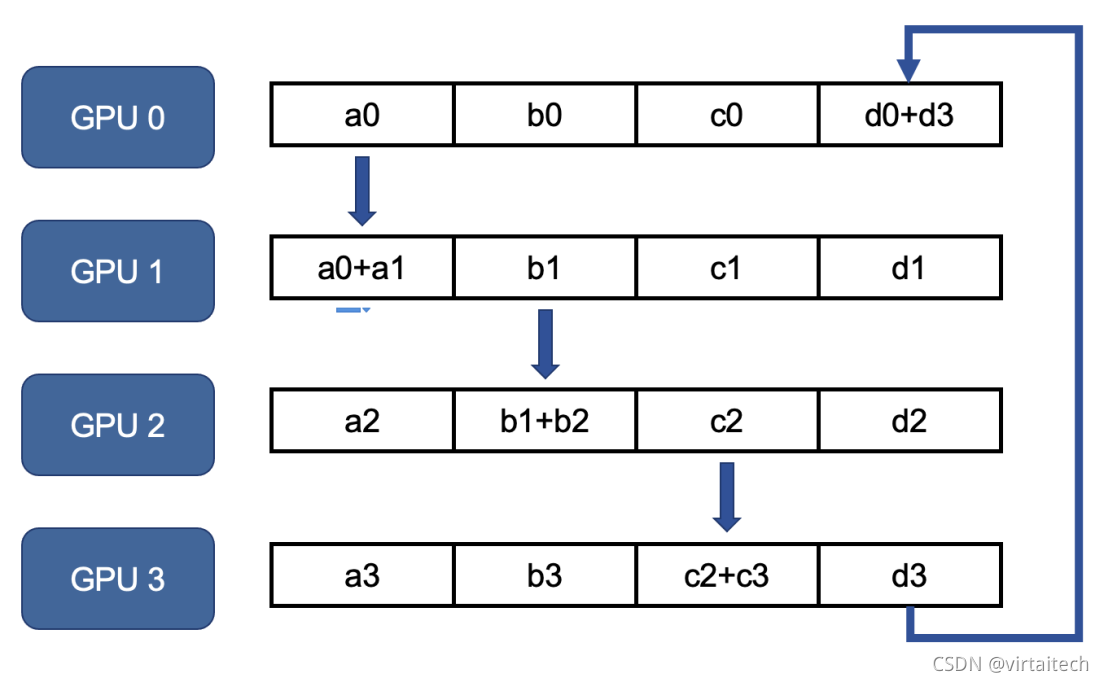
图5:Ring Allreduce scatter-reduce第一轮参数传递
第二轮GPU 1上的a0+a1传递给GPU 2上a2并相加,GPU 2上的b1+b2传递给GPU 3上的b3并相加,以此类推。
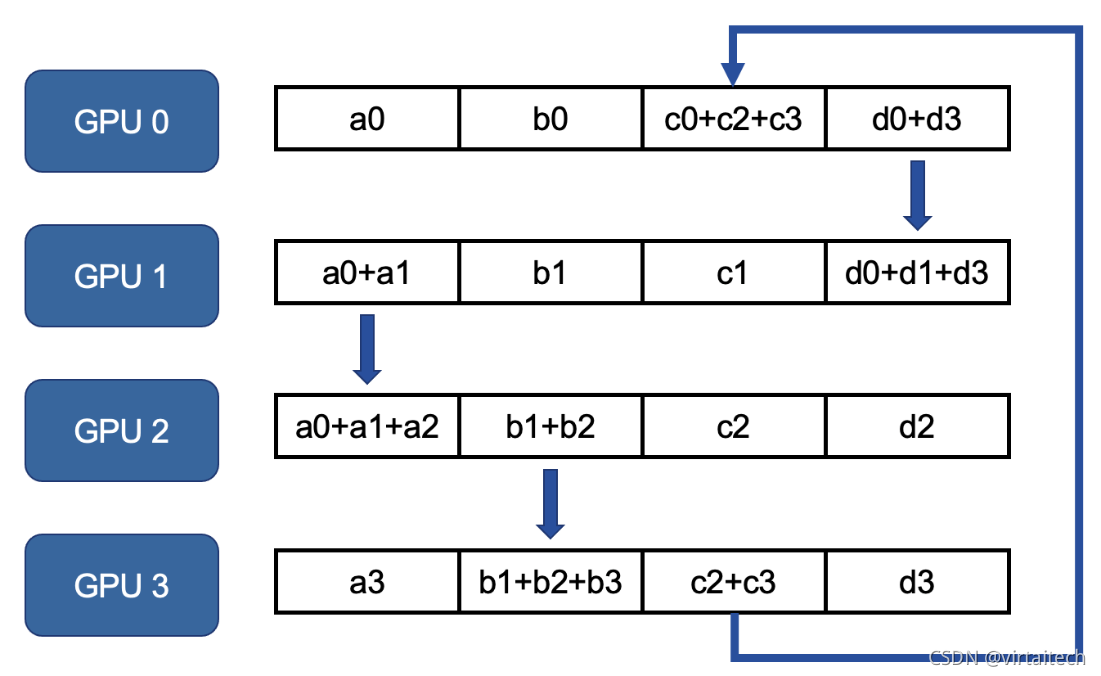
图6:Ring Allreduce scatter-reduce第二轮参数传递
第二步:当每一组节点完成相加之后,GPU3得到a0+a1+a2+a3之后,执行allgather,完整参数GPU节点向其它GPU节点传递对应的汇总参数。
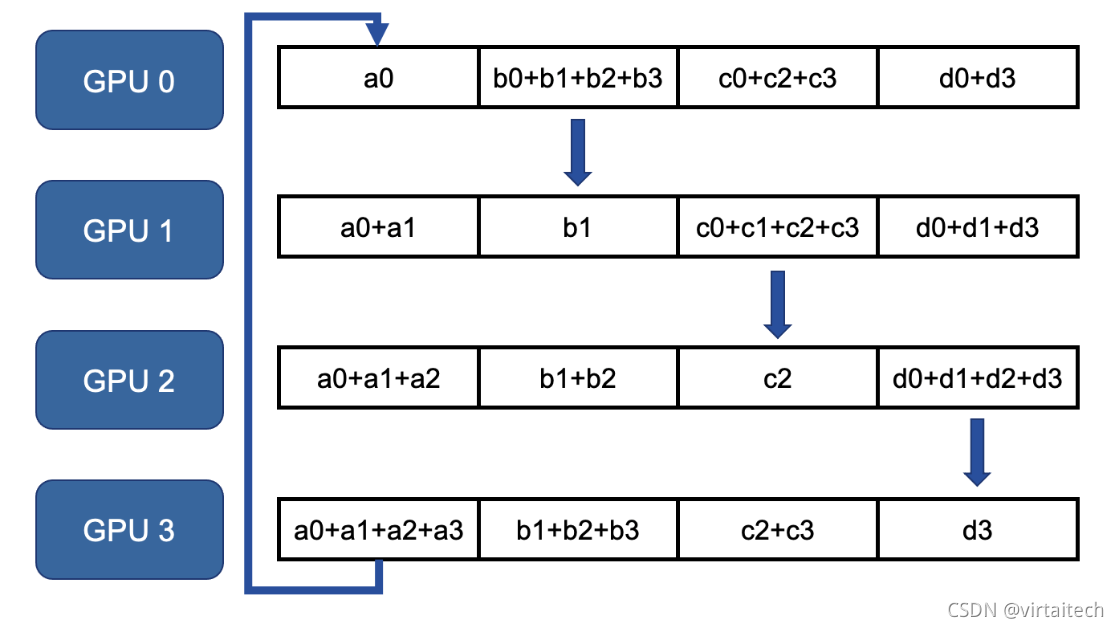
图7:Ring Allreduce allgather第一轮参数传递
最终每个节点都可以拿到完整的参数信息:

图8:Ring Allreduce allgather第N轮参数传递
Ring Allreduce算法的通信成本为:
N:GPU个数
K:通信一次完整的参数所需时间
通信代价分析:每个GPU在scatter-reduce阶段,接收N-1次数据,N是GPU数量;每个GPU在allgather阶段,接收N-1次数据;每个GPU每次发送K/N大小数据块,K是总数据大小;所以随着 GPU数量N增加,总传输量恒定。也就是理论上,随着GPU数量的增加,Ring Allreduce有线性加速能力。
RingAllreduce的算法思想演进
Ring Allreduce的计算线性加速只是理论上分析,但因为一台服务器上的GPU卡之间通信时长,多台服务器GPU卡之间的通信时长都是存在很大变化,特别是多机多卡之间通信,对通信机制、网络带宽,机器连接拓扑都有很高的要求,所以不同团队又在Ring Allreduce算法思想下不断演进,演化出更高效的多机多卡通信方式。下面简单做一个分享。
1、Hierarchical Ring Allreduce(分层环形归约)
分层环形归约由腾讯机制团队提出[2],实现4分钟训练ImageNet,算法思想为先由单机内GPU之间进行Ring Allreduce参数交换,再从每个GPU节点选出一个节点进行Allgether,这样可以有效减少跨机通信次数。
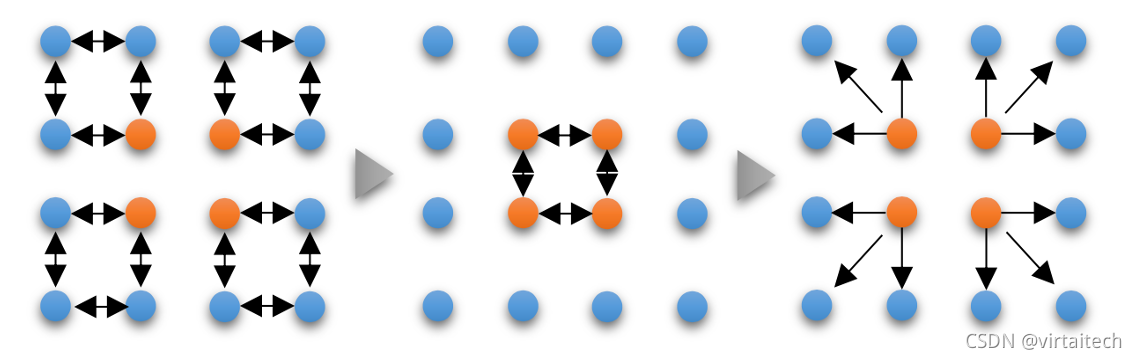
图9:Hierarchical Ring Allreduce 通信流程图
2、2D-Torus Allreduce
2D-Torus归约思想由索尼研发团队[3]提出,实现224秒训练ImageNet,算法思想为将GPU排列在一个逻辑2D网格中,并以不同的方向执行一些列操作,具体为水平执行reduce-scatter,垂直执行allreduce和水平执行allgather,最终实现通信开销进一步减小。
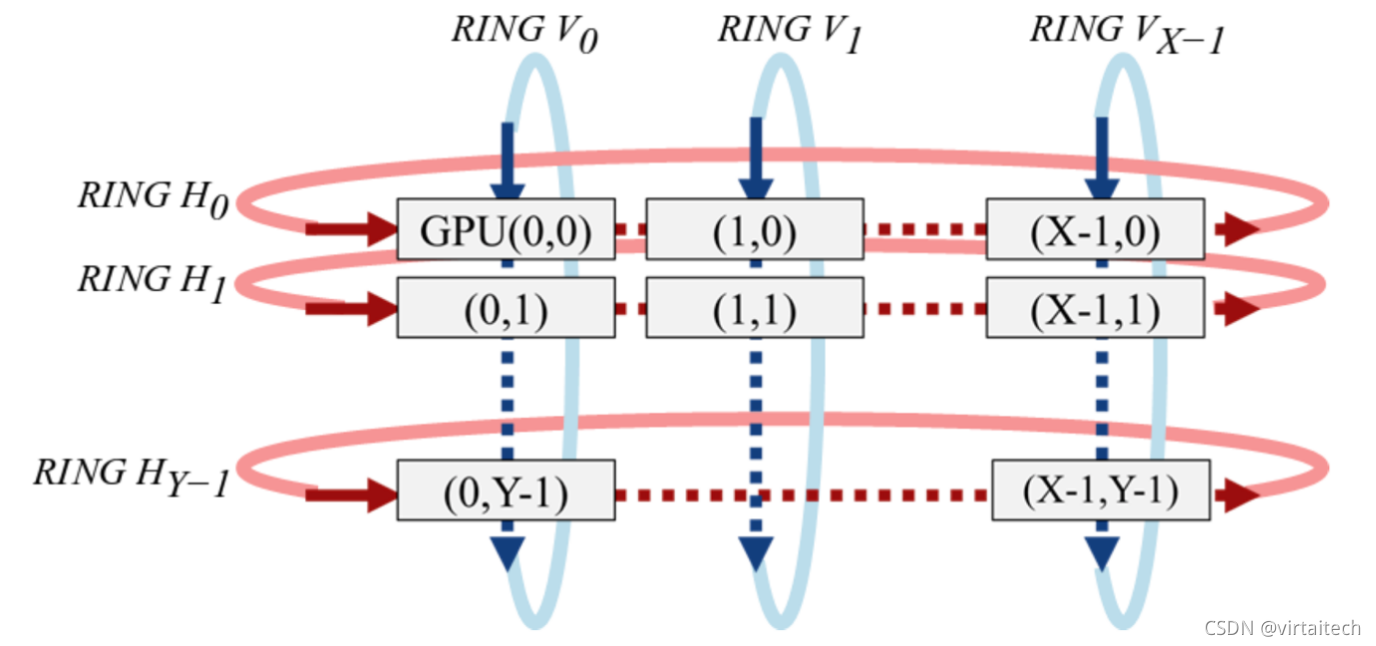
图10:2D-Torus Allreduce 通信流程图
3、3D-Torus Allreduce
IBM提出名为BlueConnect的算法,比2D-Torus算法更进一步,形成了3个维度上的分解,因此可以归类为3D-Torus算法,其主要思想是考虑了节点间不同机器和交换机(机器内->机器间交换机->上层交换机/路由器)的带宽不同,从而做出不同的分解,以达到最优的多机之间通信效果。
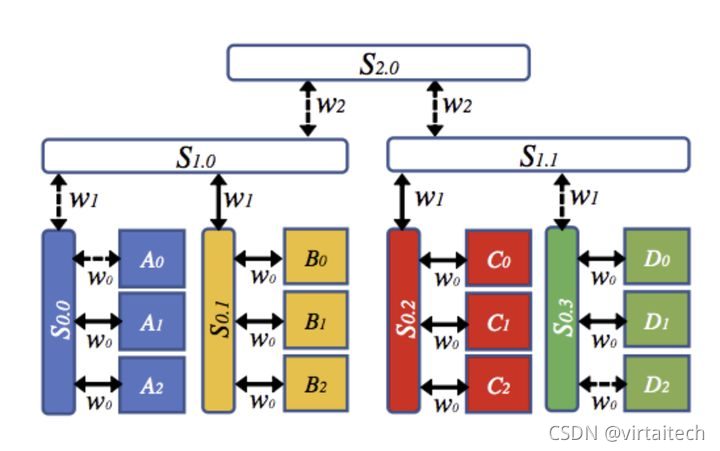
图11:3D-Torus Allred 通信流程图
趋动科技OrionX助力AI分布式训练
OrionX在分布式训练场景中,支持以Ring Allreduce为思想而实现的Nvidia NCCL,Horovod和PyTorch DDP。
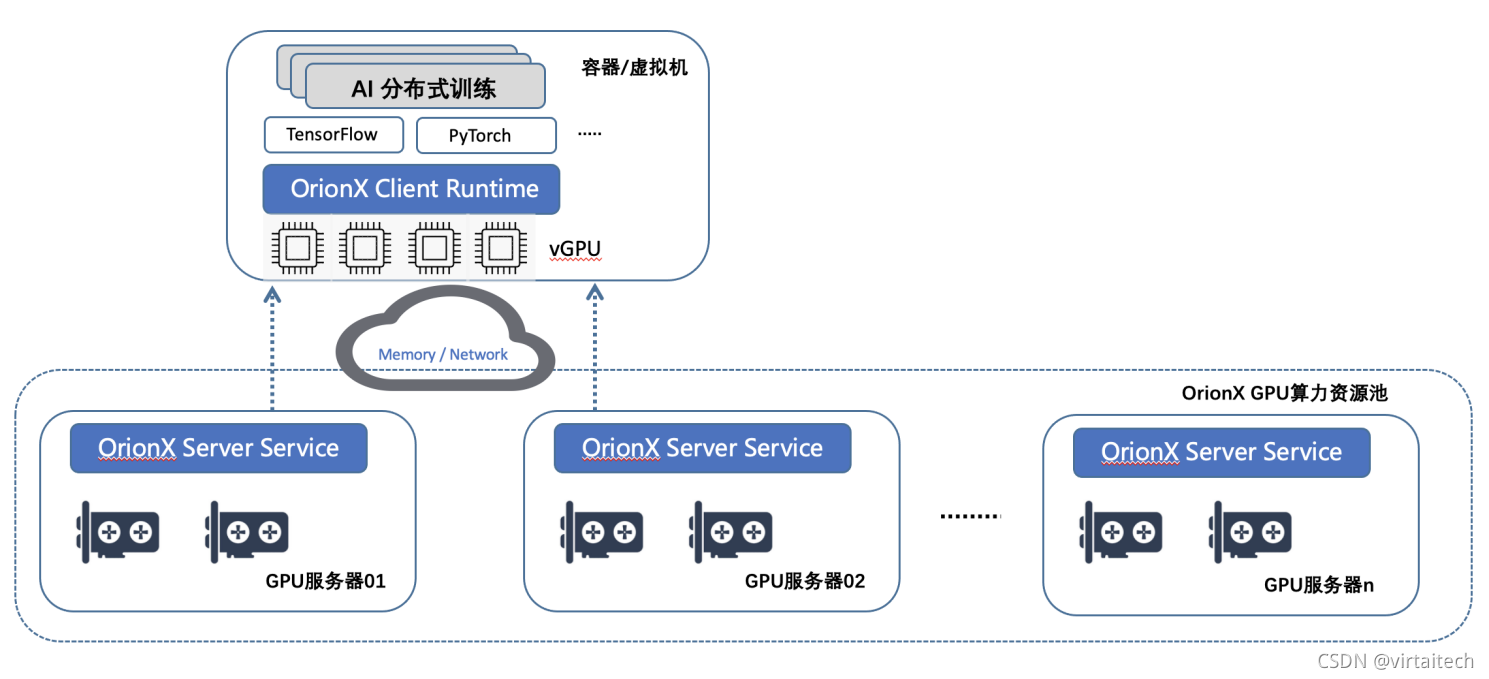
图12:OrionX AI分布式训练架构图
在AI分布式训练中,OrionX具有如下优势:
- 编程接口简单。不需要用户准备多个容器/虚机环境。这对于快速迭代的科研或算法开发来说可以节省大量编程精力。
- 资源利用率高。一个业务容器/虚机里面挂载的OrionX vGPU可以来自于多个物理机节点,每个节点使用的vGPU数目是动态生成的。因此可以有效使用多个节点中的碎片资源。
- 降低复杂度。各个节点之间的资源调用实现免密,无需复杂申请。
OrionX AI算力资源池化平台作用在IaaS层,对于算法业务层代码无论是单机多卡代码还是分布式代码都可以支持。
补充:单机多卡代码和分布式代码的区别
- AI单机多卡程序:通常为单进程多线程程序,运行范围是在一台物理机器上。
- AI分布式程序:通常为多进程程序,无论是单机单卡,单机多卡,还是多机多卡都可以运行AI分布式程序。
所以如果算法业务层原来编写的为单机多卡程序,现在期望在多台机器上运行,通常必须要进行少量的分布式代码程序改造。目前Horovod(https://github.com/horovod/horovod)和PyTorch DDP(https://pytorch.org/docs/stable/distributed.html)都封装了非常简单易用的分布式代码API接口,可以通过几个API调用就可以实现一套灵活的AI分布式代码程序。使用Horovod和PyTorch DDP的单机多卡程序无需修改代码,就可以通过OrionX直接调用多台服务器上的GPU卡,实现多机GPU聚合功能。
期待更多的AI分布式程序与OrionX能力结合,使AI训练计算更高效,更灵活。
参考文章
- Horovod: fast and easy distributed deep learning in TensorFlow https://arxiv.org/pdf/1802.05799.pdf
- 4分钟训练ImageNet!腾讯机智创造AI训练世界纪录 4分钟训练ImageNet!腾讯机智创造AI训练世界纪录 - 知乎
- Massively Distributed SGD: ImageNet/ResNet-50 Training in a Flash https://arxiv.org/pdf/1811.05233.pdf