最近工作写hive sql的时候发现了一个问题 left join和where一块用时,会出现null值数据丢失的问题
研究了一下,发现 where 写的位置不同 会有不同的结果
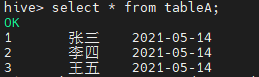
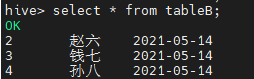
首先准备两张表 tableA 和 tableB,数据如下图
下面三个sql语句来来进行一下演示
SELECT
a.col1,
b.col2
FROM
tableA a
LEFT JOIN
tableB b ON a.id = b.id
WHERE
a.dt = '${bizdate}'
AND b.dt = '${bizdate}';
得出结果如下图
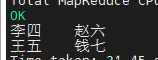
这种写法,left join 执行的效果会和 join 执行的效果一样,丢失为 null 的数据
SELECT
a.col1,
b.col2
FROM
tableA a
LEFT JOIN
tableB b ON a.id = b.id and b.dt = '${bizdate}'
WHERE a.dt = '${bizdate}';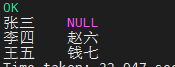 这种方法不会丢失 主表 的数据
这种方法不会丢失 主表 的数据
SELECT
a.col1,
b.col2
FROM
(SELECT id,col1 FROM tableA WHERE dt = '${bizdate}') a
LEFT JOIN
(SELECT id,col2 FROM tableB WHERE dt = '${bizdate}') b
ON a.id = b.id
第三种方法也不会丢失 主表 的数据
以上三种情况,第一种写法看着是left join,实际执行的是join,所以会丢失数据,使用的时候要注意
我们可以通过Explain语法,查看三句代码底层执行过程来进行原理的深究
hive> EXPLAIN
> SELECT
> a.col1,
> b.col2
> FROM
> tableA a
> LEFT JOIN
> tableB b ON a.id = b.id
> WHERE
> a.dt = '2021-05-14'
> AND b.dt = '2021-05-14';
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage --- 最先执行步骤4
Stage-3 depends on stages: Stage-4 --- 步骤3依赖于步骤4 为第二步执行
Stage-0 depends on stages: Stage-3 --- 步骤0依赖于步骤3 为第三步执行
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work --- 本地 map reduce
Alias -> Map Local Tables:
b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
b
TableScan --- 扫描表 b
alias: b
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree: --- map 阶段
TableScan
alias: a --- 扫描表 a
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Map Join Operator --- 执行join操作
condition map:
Left Outer Join0 to 1 --- left join操作
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col1, _col7, _col8 --- 输出三个字段 作为临时字段
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
Filter Operator --- 执行过滤操作,where b.dt = '2021-05-14' 这里会有一个explain没有显示出来的Filter 的操作 (b.id is not null)
predicate: (_col8 = '2021-05-14') (type: boolean)
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Select Operator --- 执行选择 select 操作
expressions: _col1 (type: string), _col7 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1 --- job 没有limit语句, stage-0没有任何操作
Processor Tree:
ListSink
hive> EXPLAIN
> SELECT
> a.col1,
> b.col2
> FROM
> tableA a
> LEFT JOIN
> tableB b ON a.id = b.id and b.dt = '2021-05-14'
> WHERE a.dt = '2021-05-14';
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
b
TableScan
alias: b
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: a
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 id (type: int)
1 id (type: int)
outputColumnNames: _col1, _col7 --- 输出临时字段 为两个字段
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
Select Operator --- 只有select 操作,并没有过滤filter操作
expressions: _col1 (type: string), _col7 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.229 seconds, Fetched: 56 row(s)
hive> EXPLAIN
> SELECT
> a.col1,
> b.col2
> FROM
> (SELECT id,col1 FROM tableA WHERE dt = '2021-05-14') a
> LEFT JOIN
> (SELECT id,col2 FROM tableB WHERE dt = '2021-05-14') b
> ON a.id = b.id ;
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
b:tableb
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
b:tableb
TableScan
alias: tableb
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), col2 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: int)
1 _col0 (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: tablea
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), col1 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 24 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col1, _col3
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: string), _col3 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 3 Data size: 26 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
通过explain操作查看三句sql的执行详解可以看出,第一个sql执行过程中,有一个明显的Filter过滤操作,过滤了表b的id不会null的情况
而其他两个的explain详解中,没有明显的执行Filter的操作,所以表b的id为null的情况被保留了下来
所以第一种sql的left join 结果 跟 join结果一样,
注意:第一个sql中,如果where条件里没有写右表b的条件时,也就是只写了左表a的条件时,依然是可以达到left join的效果。
版权声明:本文为KoHsin_原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。