MESI协议虽然可以实现缓存的一致性,但是也会存在一些问题。
就是各个CPU缓存行的状态是通过消息传递来进行的。如果CPU0要对一个在缓存中共享的变量进行写入,首先需要发送一个失效的消息给到其他缓存了该数据的CPU。并且要等到他们的确认回执。CPU0在这段时间内都会处于阻塞状态。为了避免阻塞带来的资源浪费。在cpu中引入
了Store Bufferes。
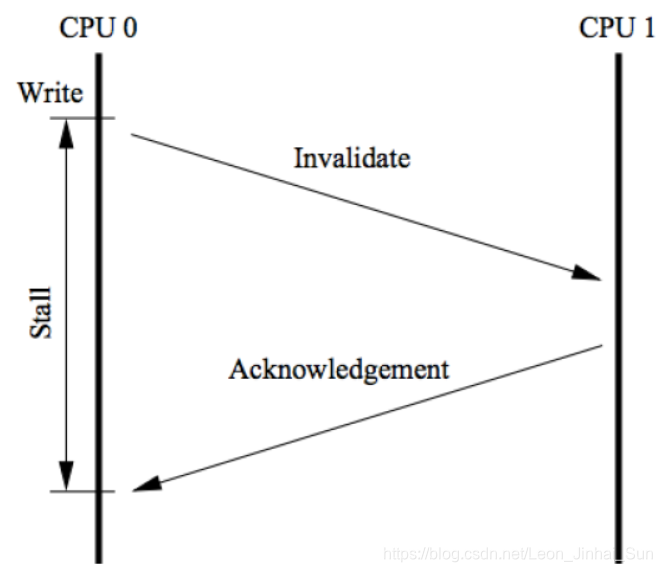
CPU0只需要在写入共享数据时,直接把数据写入到store bufferes中,同时发送invalidate消息,然后继续去处理其他指令。
当收到其他所有CPU发送了invalidate acknowledge消息时,再将store bufferes中的数据数据存储至cache line中。最后再从缓存行同步到主内存。

但是这种优化存在两个问题
1. 数据什么时候提交是不确定的,因为需要等待其他cpu给回复才会进行数据同步。这里其实是一个异步操作
2. 引入了storebufferes后,处理器会先尝试从storebuffer中读取值,如果storebuffer中有数据,则直接从storebuffer中读取,否则就再从缓存行中读取
我们来看一个例子

exeToCPU0和exeToCPU1分别在两个独立的CPU上执行。假如CPU0的缓存行中缓存了isFinish这个共享变量,并且状态为(E)、而Value可能是(S)状态。
那么这个时候,CPU0在执行的时候,会先把value=10的指令写入到storebuffer中。并且通知给其他缓存了该value变量的CPU。在等待其他CPU通知结果的时候,CPU0会继续执行isFinish=true这个指令。
而因为当前CPU0缓存了isFinish并且是Exclusive状态,所以可以直接修改isFinish=true。这个时候CPU1发起read操作去读取isFinish的值可能为true,但是value的值不等于10。
这种情况我们可以认为是CPU的乱序执行,也可以认为是一种重排序,而这种重排序会带来可见性的问题
这下硬件工程师也抓狂了,我们也能理解,从硬件层面很难去知道软件层面上的这种前后依赖关系,所以没有办法通过某种手段自动去解决。
所以硬件工程师就说:既然怎么优化都不符合你的要求,要不你来写吧。
所以在CPU层面提供了 memory barrier(内存屏障)的指令,从硬件层面来看这个 memroy barrier就是CPU flush store bufferes中的指令。软件层面可以决定在适当的地方来插入内存屏障。