第一章(了解配准)
图像配准的基本框架包括以下四个方面:特征空间、搜索空间、搜索策略和相似性度量。
特征空间
特征空间是指从参考图像和浮动图像中提取的可用于配准的特征。在基于灰度的图像配准方法中,特征空间为图像像素的灰度值;而在基于特征的图像配准方法中,特征空间可以是点、边缘、曲线、曲面、不变矩等。
搜索空间
搜索空间是指在配准过程中对图像进行变换的范围及变换的方式。
图像的变换范围可以分为三类:全局的、局部的和位移场的。全局变换是指整幅图像的空间变换都可以用相同的变换参数表示。局部变换是指在图像的不同区域可以有不同的变换参数,通常的做法是在区域的关键点位置上进行参数变换,在其他位置上进行插值处理。位移场变换是指对图像中的每一像素点独立地进行参数变换,通常使用一个连续函数来实现优化和约束。
图像的变换方式可以分为线性变换和非线性变换两种形式。线性变换又可以分为刚体变换((Rigid BodyTransformation)、仿射变换(Affine Transformation)和投影变换(Projective Transformation)。非线性变换一般使用多项式函数,如二次、三次函数及薄板样条函数,有时也使用指数函数。
相似性度量
相似性度量是衡量每次变换结果优劣的准则,用来对变换结果进行评估,为搜索策略的下一步动作提供依据。
相似性度量和特征空间、搜索空间紧密相关,不同的特征空间往往对应不同的相似性度量;而相似性度量的值将直接决定配准变换的选择,以及判断在当前所取的变换模型下图像是否被正确匹配了。通常配准算法抗干扰的能力是由特征提取和相似性度量共同决定的。
相似性度量一般有互信息、归一化互信息、联合熵、相关性、欧氏距离、梯度互相关等。
搜索策略
搜索策略的任务是在搜索空间中找到最优的配准参数,在搜索过程中以相似性度量的值作为判优依据。
常用的搜索策略有黄金分割法、Brent法、抛物线法、三次插值法、Powell法、遗传算法、蚁群算法、牛顿法、梯度下降法等。
总结
基于特征的配准方法会先涉及到图像分割及特征提取,再根据特征空间进行配准,速度较快、精度较高但是也需要人工干预。
基于灰度的配准方法不涉及图像分割,全依靠配准方法以及只针对灰度值。
不同的医学图像
在医学领域,不同模态的图像有各自的特性,如CT和 MRI以较高的空间分辨率提供器官的解剖结构信息,而PET (Positive Electron Tomography,正电子发射计算机断层扫描)和 SPECT (Emission Computed Tomography,单光子发射断层扫描)以较低的空间分辨率提供器官的新陈代谢功能信息。
第二章(特征空间)
1.点检测
空间滤波包括线性滤波和非线性滤波,这里专指线性滤波,即掩膜与图像之间的卷积操作。
点检测的基本原理:在图像f的均匀区域中,假设存在一个点P,其灰度值与周围其他像素的灰度值相差很大;对图像f用图3-2所示的掩模进行空间滤波,若点(x, y)处的响应R满足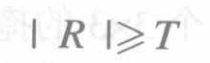
利用点检测可得到待预测的图像中的特征点。
2. 线检测
对待检测图像f用具有方向性的掩膜w进行空间滤波,若点(x,y)处的相应R满足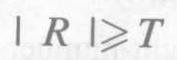
则(x,y)就是与掩膜w同方向直线上的点。其结果可为不同方向上的特征直线。
3.Hough变换
可用于检测指定的直线和曲线。
Hough变换的基本思想:若在参数平面中,相交于同一点(k,b)的直线有n条,则在图像平面中这n个点共线于由k和b确定的直线。
利用判断点是否共线,来提取出检测的直线和圆。
4.边缘检测
图像边缘是图像局部特征不连续性(灰度突变、纹理结构突变等)的反映,它标志着一个区域的终结和另个区域的开始。边缘的特征是沿边缘走向的像素变化平缓而垂直于边缘方向的像素变化剧烈。
在图像边缘的较小邻域中的像素集,它们的灰度值是不连续的,会有较大的跃变。因此,我们可以通过导数来判别图像中像素的灰度值是否存在突变,从而检测出边缘。一般可以使用一阶导数和二阶导数来实现。
基于一阶导数的边缘检测
基于一阶导数的边缘检测的基本原理:令坐标为(x,的像素的梯度值为G(x, y),若满足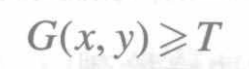
则(x,y)就是边缘上的点所在的位置。式中,T是一个正的阈值。
像素(x,y)的梯度:
常用的基于一阶导数的边缘检测器有Roberts、Prewitt、Sobel、 Robinson和 Kirsch,它们的实现机理与前面介绍的类似,最主要的区别在于实现导数的方法和掩模的选取不同。
基于二阶导数的边缘检测
设f(x)是一个离散的一元函数,其二阶导数定义如下
基于二阶导数的边缘检测的基本原理:在边缘两侧的像素点,其二阶导数符号相反,它们连线的中点就是边缘的中心。或者说,在二阶导数零交叉的地方就是边缘中心。
第四章 搜索空间
搜索空间包括空间变换范围和空间变换方式。
图像的变换范围可以分为三类:全局的、局部的和位移场的。全局变换是指整幅图像的空间变换都可以用相同的变换参数表示。局部变换是指在图像的不同区域可以有不同的变换参数,通常的做法是在区域的关键点位置上进行变换参数,在其他位置上进行插值处理。位移场变换是指对图像中的每一像素点独立地进行参数变换,通常使用一个连续函数来实现优化和约束。
空间变换方式主要解决图像平面上像素的重新定位问题,式(1-容间变换模型有刚体少执、a江音两点型进行描述,常用的空间变换模型有刚体变换、仿射变换、投影变换和非线性变换。刚体变换使一幅图像中任意两点间的距离变换到另一幅图像中后仍然保持不变;仿射变换使一幅图像中的直线经过变换后仍保持直线,并且平行线仍保持平行;投影变换是从三维图像到二维平面的投影;非线性变换把一条直线变换为一条曲线,一般用代数多项式来表示。
其中,基于像素的变换方式包括平移变换、旋转变换、缩放变换。
仿射变换具有一个重要特性:若干个仿射变换的合成依旧是一个仿射变换利用此特性,我们可以通过多个T矩阵相乘来产生一个综合了平移、旋转和按比例缩放的仿射变换。
第五章 灰度级插值技术
灰度级插值技术主要针对配准图像中像素灰度值赋值的问题,当确定了参考图像和配准图像的空间变换参数后,需要对配准图像中像素灰度值赋值,主要有正向映射法和反向映射法。
所谓正向映射法是从原始图像上的像素点坐标出发,求出配准后图像上对应的像素点坐标,然后将原始图像上像素点的灰度值赋给配准后图像上对应的像素点;反向映射法是指从配准后图像上像素点坐标出发,求出原始图像上对应的像素点坐标,然后将原始图像上像素点的灰度值赋给配准后图像上对应的像素点。
采用正向映射法将存在两大问题:一是配准图像可能有些像素没有赋值;二是原始图像上的多个像素点可能同时映射到配准图像的同一个像素点。通常反向映射比正向映射更容易实现,所以在配准中一般采用反向映射法。所以一般采用反向映射法。
反向映射法具体实现过程是:从配准后图像上的输出像素出发,找到原始图像上对应的坐标位置,由于该位置的坐标值可能不是整数,因此需要利用原始图像上该对应位置周围像素点的灰度值通过插值方法求出该位置的灰度值,然后将求得的灰度值赋给配准后图像上的像素点。
常用的灰度级插值方法有
最近邻插值法(nearest interpolation)、双线性插值法(bilinear interpolation)和立方卷积插值法(cubic convolution interpolation)。
1.最近邻插值法
最近邻插值法的实现方法是:配准图像的像素通过反向映射得到原始图像上的一个浮点坐标,对其进行四舍五入的取整,得到一个整数型坐标,这个整数型坐标对应的像素值就是配准图像对应像素的像素值。也就是说,取原始图像浮点坐标最邻近的点对应的像素值赋给配准图像。
在图像配准的灰度级插值过程中,经常需要处理出界点的问题。出界点是指反向映射点超出原图像区域,比如在几何变换时,反向映射点坐标值为负值。对于不在原图中的点,可以直接将它的像素值统一设置为某一固定值(如对于灰度图设置为0或255,即黑色或白色)或者将它的灰度值等于和它相邻的且在原图中有映射点的像素灰度值。
2.双线性插值
实现原理:双线性插值方法假定内插点p四周四个点围成的区域内的灰度变化是线性的,从而可以用线性内插方法,根据四个近邻像素的灰度值,计算出内插点p的灰度值。双线性插值法的计算示意图如下图所示。
假设浮动图像通过反向映射得到参考图像上的一个浮点坐标为( i + Δ x , j + Δ y ) (i+\Delta x,j+\Delta y)(i+Δx,j+Δy),其中i、j为正整数,Δ x \Delta xΔx、Δ y \Delta yΔy为[0,1]区间的纯小数,则f ( i + Δ x , j + Δ y ) f(i+\Delta x,j+\Delta y)f(i+Δx,j+Δy)的值可由原始图像中坐标为(i,j)、(i+1,j)、(i,j+1)、(i+1,j+1)所对应的四个像素值共同决定
f ( i + Δ x , j + Δ y ) = ( 1 − Δ x ) ( 1 − Δ y ) f ( i , j ) + Δ x ( 1 − Δ y ) f ( i , j + 1 ) + ( 1 − Δ x ) Δ y f ( i + 1 , j ) + Δ x Δ y f ( i + 1 , j + 1 ) f(i+\Delta x,j+\Delta y)=(1-\Delta x)(1-\Delta y)f(i,j)+\Delta x(1-\Delta y)f(i,j+1)+(1-\Delta x)\Delta yf(i+1,j)+\Delta x\Delta yf(i+1,j+1)f(i+Δx,j+Δy)=(1−Δx)(1−Δy)f(i,j)+Δx(1−Δy)f(i,j+1)+(1−Δx)Δyf(i+1,j)+ΔxΔyf(i+1,j+1)
出现疑问:
为什么不是( 1 − Δ x ) ( 1 − Δ y ) f ( i + 1 , j + 1 ) (1-\Delta x)(1-\Delta y)f(i+1,j+1)(1−Δx)(1−Δy)f(i+1,j+1)???开始学习的时候认为是相反的
3.立方卷积插值法
实现原理:
立方卷积插值法根据反向变换点p周围邻域16个像素点的灰度值按一定的加权系数计算加权平均值,从而内插出反向变换点的灰度值。立方卷积插值法的计算示意图如下图所示。
假设浮动图像通过反向映射得到参考图像上的一个浮点坐标为(i+u,j+v),其中i、j为正整数,u、v为[0,1]区间的纯小数,则f(i+u,j+v)的值可由原始图像中以p为中心邻域的16个像素的灰度值共同决定,其计算公式为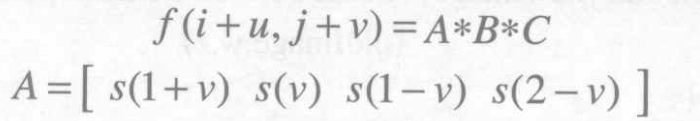
B = [ f ( i − 1 , j − 1 ) f ( i − 1 , j ) f ( i − 1 , j + 1 ) f ( i − 1 , j + 2 ) f ( i , j − 1 ) f ( i , j ) f ( i , j + 1 ) f ( i , j + 2 ) f ( i + 1 , j − 1 ) f ( i + 1 , j ) f ( i + 1 , j + 1 ) f ( i + 1 , j + 2 ) f ( i + 2 , j − 1 ) f ( i + 2 , j ) f ( i + 2 , j + 1 ) f ( i + 2 , j + 2 ) ] B=\begin{bmatrix} f(i-1,j-1) & f(i-1,j)&f(i-1,j+1)&f(i-1,j+2) \\ f(i,j-1) & f(i,j)&f(i,j+1)&f(i,j+2) \\f(i+1,j-1)&f(i+1,j)&f(i+1,j+1)&f(i+1,j+2) \\f(i+2,j-1)&f(i+2,j)&f(i+2,j+1)&f(i+2,j+2)\end{bmatrix}B=⎣⎢⎢⎡f(i−1,j−1)f(i,j−1)f(i+1,j−1)f(i+2,j−1)f(i−1,j)f(i,j)f(i+1,j)f(i+2,j)f(i−1,j+1)f(i,j+1)f(i+1,j+1)f(i+2,j+1)f(i−1,j+2)f(i,j+2)f(i+1,j+2)f(i+2,j+2)⎦⎥⎥⎤
s(w)为插值加权系数函数,定义如下:
第六章 搜索策略
常用的搜索策略:
黄金分割法、Brent法、抛物线法、三次插值法、遗传算法、蚁群算法、Powell法等。
1.一维搜索算法
一维搜索就是求目标函数在直线上的极小点,也称线性搜索。一维搜索是许多非线性规划算法的重要组成部分。常用的一维搜索算法有黄金分割法、Brent法、抛物线法、三次插值法。
2.Powell算法
互信息对于输入参数,如水平位移、垂直位移、旋转角度等没有一个具体的函数表达式,因此进行最优化搜索时,无法利用求导计算梯度的最优化方法来搜索极值。方向加速法(Powell)是一种直接法,不用计算目标函数的梯度,仅通过比较目标函数的数值大小来移动迭代点就可求出极值。Powell法对目标函数提出一套计算方案,使得经过若干次一维搜索后,产生一组共.方向。在共辄方向上进行搜索得到极值点。
3.遗传算法
算法原理:遗传算法(Genetic Algorithm)是一种仿生优化算法,该算法的基本思想来源于达尔文的进化论。遗传算法的基本原理是首先对问题的可行解进行编码,然后随机生成一定规模的初代种群,接着按照适者生存和优胜劣汰的原理,逐代进行进化。在每一代进化中,根据问题域中个体的适应度大小择优挑选个体,并按照一定的概率进行基因交叉和基因变异操作,生成新一代的种群。像自然界进化一样,遗传算法的后代种群会比前代种群具有更大的适应度,更加适应环境,即更加接近问题的最优解。最后,对末代种群中的最优个体进行解码,即可作为问题的近似最优解。
遗传操作:
遗传操作是指从父代种群中如何产生子代种群的方法,通常包括选择、交叉和变异。选择操作是交叉和变异操作的前提,交叉和变异是产生新个体的手段。
1.1 选择:
选择是指从父代种群中挑选出优良的个体。当确定了父代种群中的全部个体后,需要通过选择操作来挑选其中的较优个体,以供后续的交叉和变异使用。由于选择操作是根据个体的适应度进行的,因此在选择前需要计算父代种群中全部个体的适应度。
一般常见的选择方法有:轮盘赌选择法、随机遍历抽样法、锦标赛选择法。
1.2 交叉:
交叉是指对选择出来的优良个体通过基因交叉的方法以便产生与父代种群不同的个体,交叉是遗传算法产生新个体的主要手段。
1.3 变异:
变异是指对交叉后的个体的基因以很小的概率发生改变,通过基因变异同样可以产生与父代种群不同的个体,变异是遗传算法产生新个体的次要手段。变异的实质是一种局部随机搜索,变异概率不能太大,否则遗传算法就退化为随机搜索法。
4.蚁群算法
算法原理:蚂蚁在运动时会在所经过的路径上释放出一种称为“信息素”的化学分泌物,后续的蚂蚁可据此选择路径。前面的蚂蚁遇到一个路口时,会随机选择其中的一条路径并释放出相应的信息素,路径越长信息素越少。后面的蚂蚁来到相同的路口时,就会根据信息素的多少做出路径选择,信息量大的路径被选择的概率相对较大,同时释放信息素,这样就形成了信息正反馈。最优路径上的信息量越来越大,而其他路径上的信息随着时间的推移而逐渐消逝,整个蚁群最终会找到最佳路径。
蚁群算法(Ant Colony Optimization Algorithm)是一种模仿蚁群行为的仿生优化算法,其实现机理包括两个基本阶段:适应阶段和协作阶段。在适应阶段,各可行解根据积累的信息不断调整自身结构,路径上经过的蚂蚁越多,信息量越大,则该路径越容易被选择;时间越长,信息量越小。在协作阶段,各可行解之间通过信息交流,以期望产生性能更好的解。
第七章 相似性度量
常用的相似性度量准则:最大互信息测度、归一化互信息、联合嫡、相关性、欧氏距离等。
1.最大互信息测度
1.信息熵定义
Hartley在研究消息的信息量度量时认为:一条消息是由n个符号组成的一个符号串,其中每个符号有s种不同的可能。因此,一条消息共有s n s^nsn种不同消息可能性,所以信息量可以用s n s^nsn度量,但此时信息量将随着消息的长度指数增加,为了得到线性增加的度量,可以采用取对数的方法。于是Hartley 给出了信息量的定义H = log 2 s n = n log 2 s H=\log_2{s^n}=n\log_2{s}H=log2sn=nlog2s
这种度量方法可以看成是对不确定性的度量,例如我现在已经知道自己要收到的是那条消息,那么它是确定的即不确定性为0;如果可能要收到的不同消息越多,那么我要收到信息越不确定,则其不确定性越大。
Hartley度量方法的不足之处是假设所有符号出现的概率一样,而实际情况往往是不一样的。为此,Shannon提出了一个改进的方法:对消息出现的可能性采用概率来衡量,信息量依据其概率进行加权得到。
假设某一随机现象共有n种可能,它们发生的概率分别是p 1 , p 2 , . . . , p n p_1,p_2,...,p_np1,p2,...,pn,则 Shannon熵的定义如下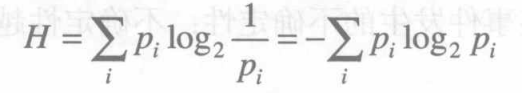
由上式可知,当所有的事件等概率出现时,Shannon熵就变成了Hartley熵: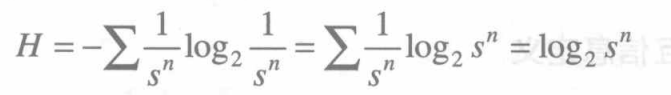
当涉及到信息熵时,通常人们使用更多的是 Shannon熵。
Shannon熵可用来度量某消息包含的信息量。从香农公式定义可知 Shannon熵实质上就是对所有可能事件的信息量依据其概率进行加权而得到的,因此从一个发生概率为p i p_ipi的事件所获得的信息量与该事件发生的概率成反比。
Shannon熵也可看成是对不确定性的度量:当所有事件等概率发生时,熵取得最大值,不确定性相应地达到最大;当某事件比其他事件有更大的可能性发生时,熵变小,不确定性也随之降低。当事件的发生概率为1时,熵取得最小值0,此事件必然发生。
Shannon熵也可用于对概率分布的分散性的度量:集中的分布对应着低熵值,而分散的分布对应着高熵值。利用此特性,可以计算图像所包含的信息量,此时我们所关注的是图像灰度值的分布。灰度值的概率分布可以这样计算,用一幅图像中每个灰度值出现的次数除以所有灰度值出现次数的总数。如果一幅图像只包含一个灰度值,那么它的熵值将很低,因为它所包含的信息量很少。反之,如果一幅图像包含很多灰度值,这些灰度值出现的次数又大致相同,那么它的熵值将很高,因为它包含的信息量很多。
综上所述,熵有三种含义:
(1)度量某消息包含的信息量:信息量越大,熵越大。
(2)度量某事件发生的不确定性:不确定性越强,熵越大。
(3)度量某事件概率分布的分散性:分散性越强,熵越大。
2.互信息定义
互信息通常用于描述两个系统间的统计相关性,或者是一个系统中所包含的另一个系统信息的多少,它可以用熵来描述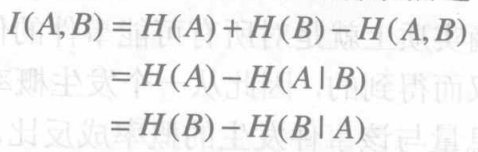
其中,H(A)和H(B)分别是系统A和B的熵,H(A,B)是它们的联合熵,H(AIB)和H(BIA)分别表示已知系统B时A的条件熵和已知系统A时B的条件熵。
上述各种熵可以分别表示为:
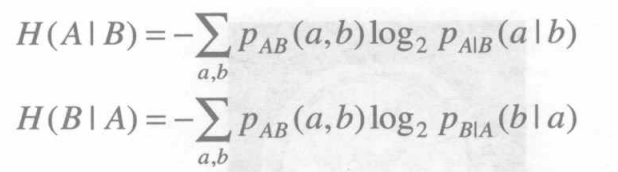
其中,a ∈ A , b ∈ B a\in A,b\in Ba∈A,b∈B,p A ( a ) p_A{(a)}pA(a)和p B ( b ) p_B{(b)}pB(b)分别是系统A和B完全独立时的概率分布,p A B ( a , b ) p_{AB}{(a,b)}pAB(a,b)是系统A和B的联合概率分布,p A ∣ B ( a ∣ b ) p_{A|B}{(a|b)}pA∣B(a∣b)是已知系统B时A的条件概率分布,p B ∣ A ( b ∣ a ) p_{B|A}{(b|a)}pB∣A(b∣a)是已知系统A时B的条件概率分布。
3.直方图
定义:
设数字图像f ( x , y ) f(x,y)f(x,y)的灰度级值r ∈ [ 0 , L − 1 ] r\in [0,L-1]r∈[0,L−1],则f ( x , y ) f(x,y)f(x,y)的直方图可用离散函数h ( r k ) h(r_k)h(rk)表示为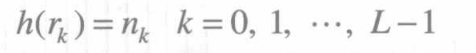
式中,r k r_krk表示第k级灰度值,n k n_knk表示图像f ( x , y ) f(x,y)f(x,y)中灰度级值为r k r_krk的像素个数。
直方图归一化:
设图像f ( x , y ) f(x,y)f(x,y)的归一化直方图函数为p ( r k ) p(r_k)p(rk),f ( x , y ) f(x,y)f(x,y)总像素数为n,对上式两边同时除以n,则得到p ( r k ) p(r_k)p(rk)的表达式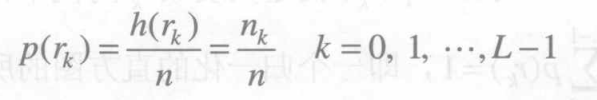
由于n = ∑ k n k = ∑ k h ( r k ) n=\sum_k{n_k}=\sum_k{h(r_k)}n=∑knk=∑kh(rk),因此上式也可表示为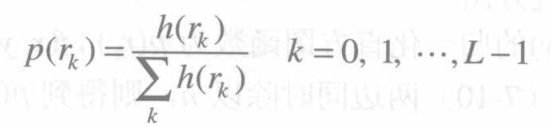
显然,p ( r k ) p(r_k)p(rk)是灰度级r k r_krk的概率分布函数。显然∑ k = 0 L − 1 p ( r k ) = 1 \sum_{k=0}^{L-1}{p(r_k)}=1∑k=0L−1p(rk)=1,即一个归一化直方图的所有部分之和等于1.
最大互信息理论
互信息可用于图像配准的理论依据是:如果两幅图像已经配准,则它们的互信息达到极大值。
从上图中我们得知,当图像A和B配准时其联合直方图中的点集中分布在对角线上,随着图像A和B的相似性降低,联合直方图中的点更加分散分布在对角线周边。由前面的熵理论可知,当图像A和B配准时,它们的联合熵达到极小值,互信息达到极大值。
2.AM测度
AM (Alignment Metric)测度,表示一幅图像每个灰度值在像素位置上对应的另一幅图像的灰度值最稳定,在数学上体现为方差最小。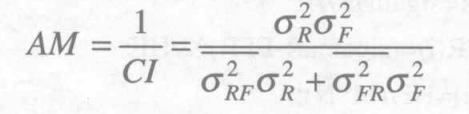
式中,CI表示为图像R(x,y)和F(x,y)的交互方差。
图像配准算法的一般流程图

本博客是由于自己才开始接触配准方面的知识,才在学习《图像配准技术及其MATLAB编程实现》时所做的摘要知识,提炼或者直接引用书中的原话以作记忆。