本文不仅解释深度图像如何转化为激光雷达,更通过笔者的亲测阐释了为什么kinect深度图像转化的数据只能检测到平行kinect的障碍物,而较低的障碍物或者较高的障碍物检测不到。帮助新手少走弯路,当然有些知识和图片偷袭别人的。
首先先看下原理:
深度图转激光在ROS包depthimage_to_laserscan,代码中实现,本篇讲解其计算过程。
1. 深度图转激光原理
原理如图(1)所示。深度图转激光中,对任意给定的一个深度图像点m(u,v,z)
,其转换激光的步骤为:
a.将深度图像的点m(u,v,z)
转换到深度相机坐标系下的坐标点 M(x,y,z)b.计算直线AO
和 CO 的夹角 AOC,计算公式如下:θ=atan(x/z)
c.将叫AOC
影射到相应的激光数据槽中.已知激光的最小最大范围 [α,β] , 激光束共细分为 N 分,那么可用数组 laser[N] 表示激光数据。那么点 M 投影到数组laser中的索引值 n可如下计算:
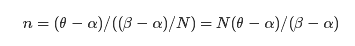
laser[n]的值为M在x轴上投影的点C到相机光心O的距离r
,即
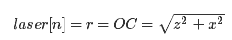

核心代码
我们的想法是取深度图像上每一列最小值依次保存到雷达ranges[]数组中,这样理论上,我们将会获kinect前方纵向上最近的障碍物距离,ranges[]数组体现了横向每个障碍点到kinect距离。但是实际,纵向上扫面的高度极为苛刻,并不能把地面到到0.6米的高度都扫一遍,因为什么呢,请看后面总结。先看核心代码,思路:先行扫描将数据存到ranges[]中,然后再高度扫面,比较下一行与原来数据ranges[],小数据替换原来ranges[]中的大数据,这样就将高度给压缩了。
template<typename T>
void convert(const sensor_msgs::ImageConstPtr& depth_msg, const image_geometry::PinholeCameraModel& cam_model,
const sensor_msgs::LaserScanPtr& scan_msg, const int& scan_height) const{
// Use correct principal point from calibration使用校正的正确的主要点
float center_x = cam_model.cx(); 中心点
float center_y = cam_model.cy();
// Combine unit conversion (if necessary) with scaling by focal length for computing (X,Y)
//在计算(X,Y)的时候,结合单位转换(如果必要的话)
double unit_scaling = depthimage_to_laserscan::DepthTraits<T>::toMeters( T(1) );
float constant_x = unit_scaling / cam_model.fx();
float constant_y = unit_scaling / cam_model.fy();
const T* depth_row = reinterpret_cast<const T*>(&depth_msg->data[0]);
int row_step = depth_msg->step / sizeof(T);
int offset = (int)(cam_model.cy()-scan_height/2);
depth_row += offset*row_step; // Offset to center of image
for(int v = offset; v < offset+scan_height_; v++, depth_row += row_step){ 高度遍历,层次遍历
for (int u = 0; u < (int)depth_msg->width; u++) // Loop over遍历 each pixel in row
{ 行遍历计算距离r,保存到一维雷达数组中ranges[]中
T depth = depth_row[u];
double r = depth; // Assign to pass through NaNs and Infs
double th = -atan2((double)(u - center_x) * constant_x, unit_scaling); // Atan2(x, z), but depth divides out
int index = (th - scan_msg->angle_min) / scan_msg->angle_increment; //当前数据所在ranges[]的下标
if (depthimage_to_laserscan::DepthTraits<T>::valid(depth)){ // Not NaN or Inf
// Calculate 计算in XYZ
double x = (u - center_x) * depth * constant_x;
double z = depthimage_to_laserscan::DepthTraits<T>::toMeters(depth);
// Calculate actual distance
r = sqrt(pow(x, 2.0) + pow(z, 2.0));//实际距离
}
// Determine if this point should be used.
if(use_point(r, scan_msg->ranges[index], scan_msg->range_min, scan_msg->range_max)){
scan_msg->ranges[index] = r;//此函数进行此障碍点到相机距离r与其列存的当前值ranges[index]比较,
}//返回ture,说明r值小,找出了当前此列高度上距离最近的障碍物
}
}
}重点
现实世界的实际距离是通过深度图像转化的,而我们的scan_hight是针对深度图像扫描高度,深度图像类似一张照片,如
这张图偏中是下方基本都是地面,当我扫面高度超过一定范围,就会把地面当成障碍物引入。所以如果我想检测相机前方1米高度为10CM的障碍物,你就得把scan_hight设置到200(亲测),这样是可以检测到了,但是再远1米的地面都会被检测,都会引入当成障碍物,这样的结果是,导致全局都是障碍物。可能会想,找到一个合适scan_hight,并没有,通常设置为10。scan_hight对扫面的高度影响极小,但对远处的障碍物影响很大,所以稍微改动,得不到想要的结果,反而影响的全局了规划。
所以,最好的办法就是给机器人另加传感器。