今天群里抛出了个乍看之下很迷的问题:

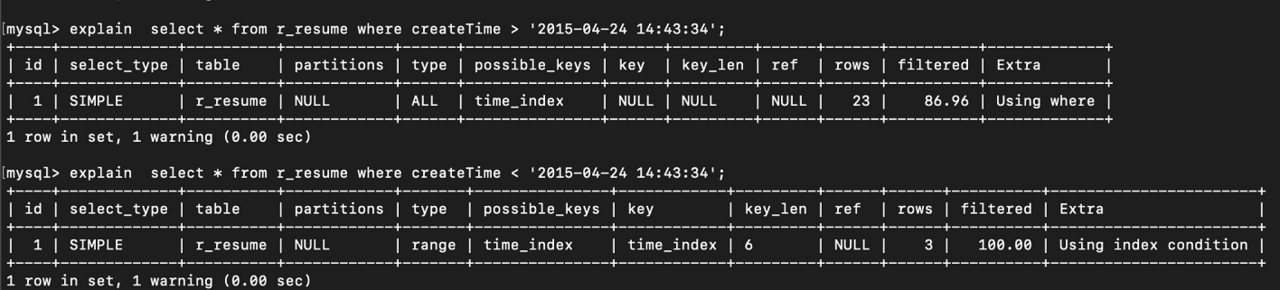
看到问题的第一瞬间,我想这是什么原理,比较方向的修改就能引起索引失效了?于是我自己先试了一下。
环境:MySQL 5.7.25
1. 创建测试表
我先整了个32万行记录的表test_user,表中仅有两个字段:id和创建时间:
CREATE TABLE `test_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`create_time` datetime NOT NULL COMMENT '创建时间'
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
复制代码
2. 创建索引
然后针对时间字段create_time加索引ct_index
create index ct_index on test_user(create_time);
复制代码
3. 分析sql
对select * from test_user where create_time > '2007-07-02 13:07:51';进行explain分析,这里的时间2007-07-02 13:07:51只是随便取一个值:
mysql> explain select * from test_user where create_time > '2007-07-02 13:07:51';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | test_user | NULL | ALL | ct_index | NULL | NULL | NULL | 317844 | 49.19 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
复制代码
看到执行计划的type为ALL(全表查询)我有些奇怪:我在create_time列加了索引,范围查询也基于create_time,没有使用上索引呢(若使用上则type为range)?
我姑且再试一次,对select * from test_user where create_time < '2007-07-02 13:07:51';做分析,这里大于号改为小于号:
mysql> explain select * from test_user where create_time < '2007-07-02 13:07:51';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | test_user | NULL | ALL | ct_index | NULL | NULL | NULL | 317844 | 50.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
复制代码
结论同上,一样没有走索引。至此还看不到什么规律,于是我改变where子句的查询条件多做测试分析,将年份2007改为2017:
mysql> explain select * from test_user where create_time < '2017-07-02 13:07:51';
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | test_user | NULL | ALL | ct_index | NULL | NULL | NULL | 317844 | 50.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from test_user where create_time > '2017-07-02 13:07:51';
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | test_user | NULL | range | ct_index | ct_index | 5 | NULL | 30614 | 100.00 | Using index condition |
+----+-------------+-----------+------------+-------+---------------+----------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
复制代码
终于在分析select * from test_user where create_time > '2017-07-02 13:07:51';时有了不同的结果,通过type为range和key为ct_index可以看出,索引生效了,但是为什么呢?原理何在?
我发现在索引失效的三个SQL的explain报告中,预估的扫描数rows都为317844,即接近全表扫描320000条数据(或者说就是做了全表扫描,但是这里只显示预估值317844),而唯一使用了索引的SQL的explain报告则显示预估扫描30614条。这应该是问题的突破口。于是我往MySQL官网跑了。
寻找答案
我最终在第八章优化部分找到答案
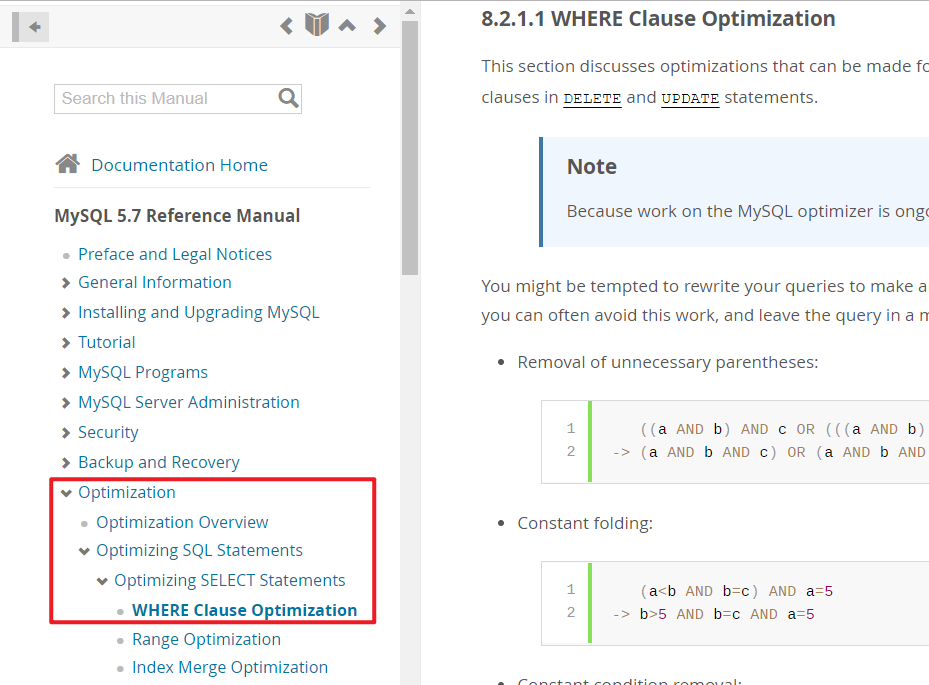

我翻译一下大意是:
Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan.
表中的每个索引都会被访问,当中最佳的那个则会被使用,除非优化器认为使用全表查询比使用所有查询更高效。
At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longer determines the choice between using an index or a scan.
曾经,是否进行全表扫描取决于使用最好的索引查出来的数据是否超过表的30%的数据,但是现在这个固定百分比(30%)不再决定使用索引还是全表扫描了。
The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size.
优化器现在变得更复杂,它考虑的因素更多,比如表大小、行数量、IO块大小。
复制代码
如果看完我的翻译仍觉得迷糊的,那这里再加点大白话:
我们建的索引并不是总会起作用的,中间有查询优化器插足,它会判断一个查询SQL是否走索引查得更快,若是,就走索引,否则做全表扫描。
以前有个百分比(30%)决定SQL是走索引还是走全表扫描,就是说如果总共有100行记录,走索引查询出来的记录超过30条,那还不如不走索引了。
但是现在MySQL不这么干了,不只通过这个百分比来决定走不走索引,而是要参考更多因素来做决定。
复制代码
至此,我们回头看看上述4条SQL的查询记录数和总数之比:
mysql> select
-> (select count(*) from test_user where create_time > '2007-07-02 13:07:51')/(select count(*) from test_user) as '>2007',
-> (select count(*) from test_user where create_time < '2007-07-02 13:07:51')/(select count(*) from test_user) as '<2007',
-> (select count(*) from test_user where create_time > '2017-07-02 13:07:51')/(select count(*) from test_user) as '>2017',
-> (select count(*) from test_user where create_time < '2017-07-02 13:07:51')/(select count(*) from test_user) as '<2017';
+--------+--------+--------+--------+
| >2007 | <2007 | >2017 | <2017 |
+--------+--------+--------+--------+
| 0.2484 | 0.7515 | 0.0508 | 0.9492 |
+--------+--------+--------+--------+
1 row in set (0.30 sec)
复制代码
这时就可以明确地看出结论了:执行select * from test_user where create_time > '2017-07-02 13:07:51';查询得到的数据只占总数据量的5%,查询优化器认为这比做全表扫描来的值,于是它就走索引。
最终得出的结论是,索引失效并不是因为字段类型为时间类型,而是因为查询优化器会对SQL的执行计划进行判断,选择一个最优最快的查询方式,当走索引的代价高于全表扫描时就不会采取走索引的方式去执行SQL。