‘‘目录
如何直观理解PPO算法?[理论篇] - 知乎 (zhihu.com)
Proximal Policy Optimization(PPO)算法原理及实现! - 简书 (jianshu.com)
1-Critic的作用与效果.mp4_哔哩哔哩_bilibili
PPO ALGORITHM
进行看别人文章:
如何直观理解PPO算法?[理论篇] - 知乎 (zhihu.com)
- 老实说这篇文章,我并没有汲取太多的有关PPO的东西,原因是因为他讲的有关知识太少,肤浅和杂乱,且针对强化学习,没有一点基础是看不懂他讲的什么。下面是我给出的自己汲取到的东西:
- OpenAL将PPO作为首选算法;PPO是目前来讲最广的一种算法;
- PPO 是基于AC框架;
- AC产生的一个问题:AC产生的数据,只能更新一次
- PPO做的工作就是在一定条件下将数据存下来
- PPO采用important-sampling 重要性采样技术 做到离线策略;

【强化学习8】PPO - 知乎 (zhihu.com)
- 这篇文章讲的较好,基本把PPO的内核讲到位了:
- DPPO(Deepmind PPO)
- 首先,简单回顾policy gradient 的损失函数:
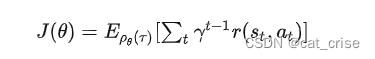
- gradient :
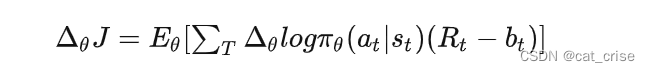
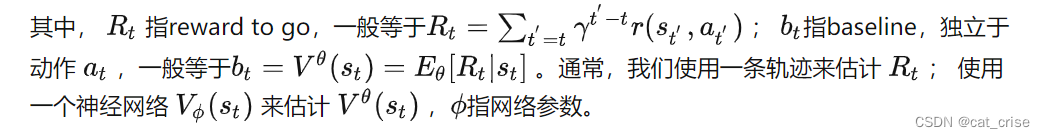
- 以上属于policy gradient ,但是policy gradient 的方差很大,并且对超参数很敏感。目前用的解决方法是 trust region constraint 限制gradient 的变化量,从而使得损失函数单调递增。eg:TRPO:
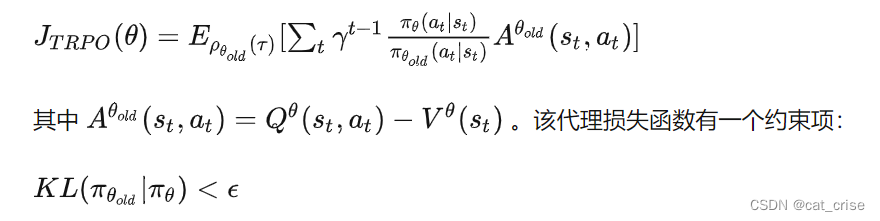
- 约束项的作用是抑制policy的变化量不要太大,从而使policy的损失能够单调递增
- TRPO需要使用对偶梯度法进行优化,有很大难度。因此,openAI 提出了一个简化TRPO => PPO 。 PPO使用一个正则项作为trust region restraint ,根据trust region restraint 是否被遵守来设定正则化的系数,从而避免使用对偶法,Deepmind PPO:



先运行当前的policy,采集T个sample,再更新policy和critic。所以,ppo是一种online policy
KL是一个约束项,避免
变化太大;子循环2的作用是估计state value函数
的参数

DPPO是一种同步并行PPO算法。同步并行算法的原理可用下图来表示。DPPO把网络参数存在到一个服务器上,并且会在每一个gradient step后同步地更新workers的参数。Algorithm 2是DPPO的服务器端,用于同步地更新actor和critic参数。

- 首先,简单回顾policy gradient 的损失函数:
PPO(OpenAI)
policy gradient 中,虽然使用一条轨迹对
进行多步优化很有吸引力,但它会使得policy gradient 更新量太大,从而难保损失函数单调递增
TRPO::一种具有单调递增特性的policy gradient算法。它构造了一个带有约束项的代理objective。TRPO使用共轭梯度法求解上述约束目标函数。由于TRPO很复杂,openAI提出了PPO。早期的PPO使用一个惩罚项来替代TRPO的约束项,从而把约束优化问题转换为无约束优化问题。
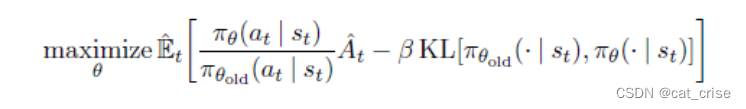
该代理objective的目的是最大化其第一项,以及最小化KL,从而使 θ 变化量不会太大并且确保强化学习的目标函数单调递增。该代理objective中的 β 是一个很有争议的正则系数。TRPO不用 β 的原因是因为很难选择一个合适的β ,使算法能够适应不用的问题(TRPO和PPO是同一个作者)。另外,作者通过实验发现如果使用固定的正则系数,PPO的性能好不到哪里。- PPO原理:
- 版本一:

版本二:

PPO算法流程
PPO算法参考了A3C很多东西。如果策略网络和评价网络贡献网络参数的话,PPO参考A3C采用了一个多任务损失函数:PPO的算法流程为,这里说明一下:N指平行运行的actor数量;T是一个小于回合长度的数;在每一次网络参数更新过程中,所有actor共产生了NT个数据,对这些数据进行epochs为K,batchsize为M的网络更新(经典的actor critic只利用数据一次,这里利用了数据K次,因此有点off-policy的感觉)。
- 版本一:
Proximal Policy Optimization(PPO)算法原理及实现! - 简书 (jianshu.com)
- 这篇文章是整理性文章,将李弘毅老师的强化学习视频进行学习输出,值得揪着其文章,看着视频。视频里有笔记链接:(4条消息) 【笔记2-2】李宏毅深度强化学习笔记(二)Proximal Policy Optimization (PPO)_jessie_weiqing的博客-CSDN博客
- Proximal Policy Optimization
- 这个是PPO官网网页,我认为这个很官方,讲的特别好
- 首先它指出:Policy gradient methods 是利用深度神经网络进行控制的基础。但是目前来讲,由于其对步长、信号敏感度太强,导致样本效率也就很低。
- 通过TRPO和ACER来消除上述缺陷时:ACRE比PPO复杂得多,在Atari基准测试中,只比PPO好一点;TRPO 与共享策略和值函数或辅助损失不容易兼容。下面是PPO的一个变体的目标函数:

- 上面目标函数是实现一种与随机梯度下降兼容的信任域更新方法。通过消除KL惩罚和进行自适应更新来简化算法
- 测试中,该算法在连续控制任务上表现出很好的性能。几乎和ACER在Atari的表现一样,而且应用起来很简单
1-Critic的作用与效果.mp4_哔哩哔哩_bilibili
- 这个博主绝对是个宝藏博主!讲解很详细,对新人特别友好!
- 强化学习需要不断与环境交互;需要大量的模拟数据来训练;设置奖励机制,获得最终结果
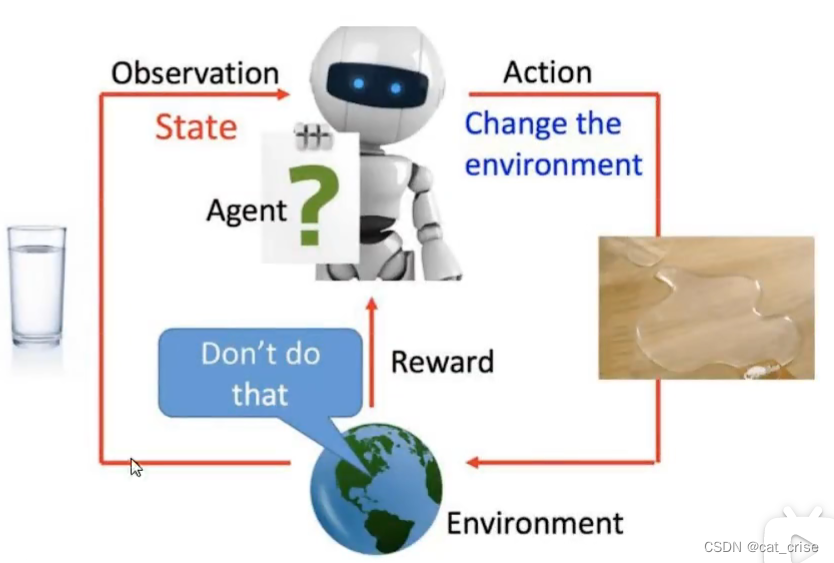 这张图表达的是强化学习的工作框架!
这张图表达的是强化学习的工作框架!- 在这里我整理一下PPO算法的具体流程:
- 首先呢,根据数据模型分析,我要得到最大化我的整个模型中的奖励最大;
- 其次,根据大数定律,直接穷举所有可能性就好了;
- 接下引入一个化简,log那个化简,然后将数据全部引入求解即可;
- 但是呢,根据我们陟罚臧否,不宜异同思想,提出来baseline思想,即:将奖励去均值思想,建立以0为中心的正态分布
- 但是呢,将数据带入以上公式时候,还是出现,对应一个
- 最终呢,就形成了我的PPO algorithm
- importance sampling
- 替代者要尽可能接近被替代者
- 下面是摆公式了,请注意:
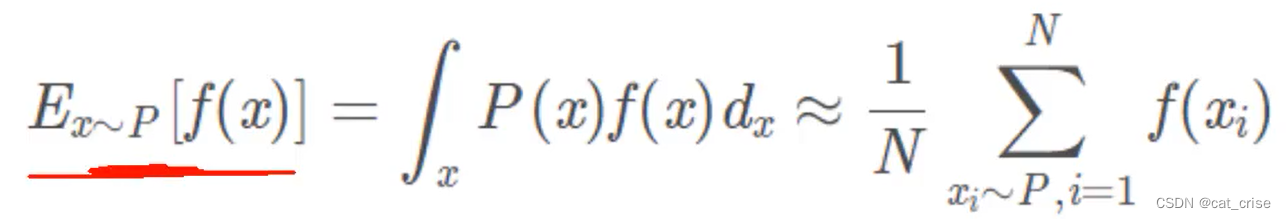 这条公式是我们本来的“公子哥”,现在呢,需要
这条公式是我们本来的“公子哥”,现在呢,需要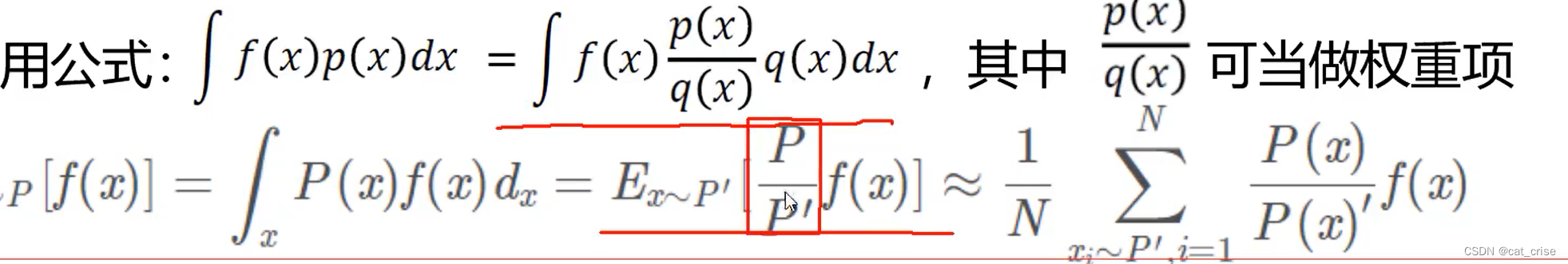 这其实就是一个公式代换而已,尽管如此,也是想了一会,才明白。
这其实就是一个公式代换而已,尽管如此,也是想了一会,才明白。 最后,求梯度的话,也可以写为
最后,求梯度的话,也可以写为
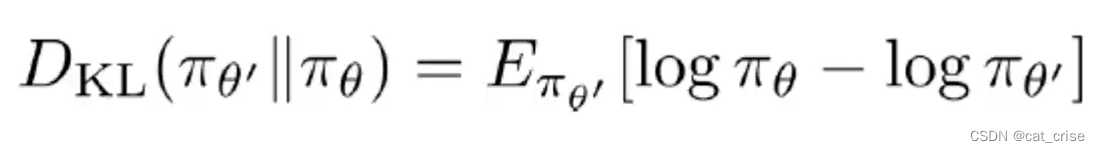
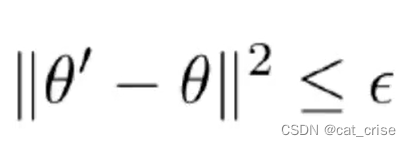 实际中是他俩经过网络的预测结果尽可能差不多
实际中是他俩经过网络的预测结果尽可能差不多
- 这里说明一下:On policy & Off policy
- On policy: 就是训练数据由当前agent不断的环境交互得到的
- Off policy: 就是自己可以歇着了,找个打工的帮我来跟环境进行交互得到结果
- 我用我的理解来讲明一下,为什么忽然来个Off policy,你看啊,上述那个梯度公式,那个
- 这里还有一个问题,就是
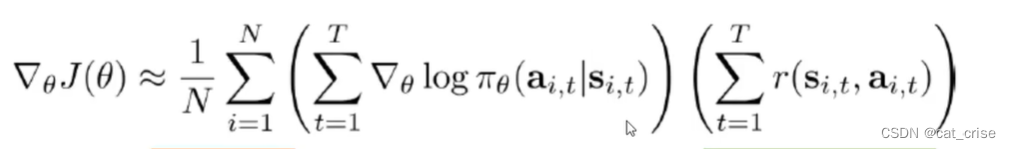 这个求得的函数,只是给出奖励,那对不适合的目标没有任何惩罚,就导致,目标获取的时间长,于是,聪明的学者就提出了一个baseline,什么意思呢?希望通过奖励和惩罚来完成训练,想到了正态分布,具体是,将奖励去均值,
这个求得的函数,只是给出奖励,那对不适合的目标没有任何惩罚,就导致,目标获取的时间长,于是,聪明的学者就提出了一个baseline,什么意思呢?希望通过奖励和惩罚来完成训练,想到了正态分布,具体是,将奖励去均值,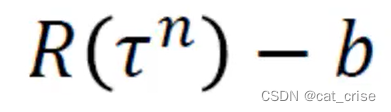 b为奖励的均值。
b为奖励的均值。 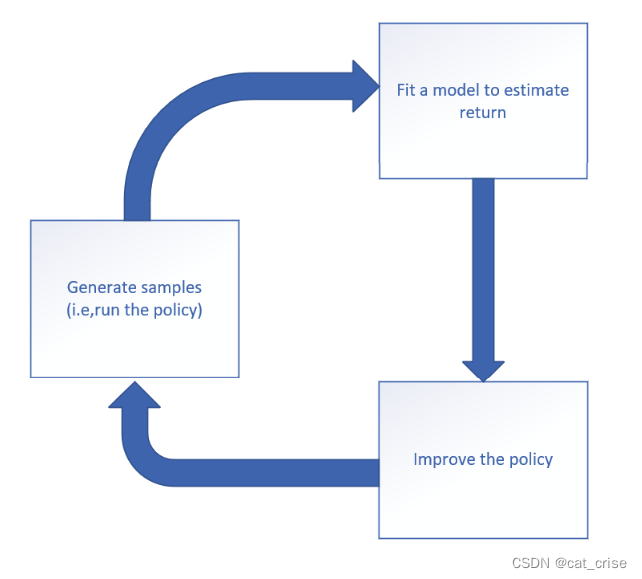 这张图是其运行流程
这张图是其运行流程- 再最后利用大数定律写成这个公式:
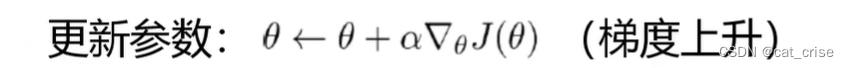
- 最后是求
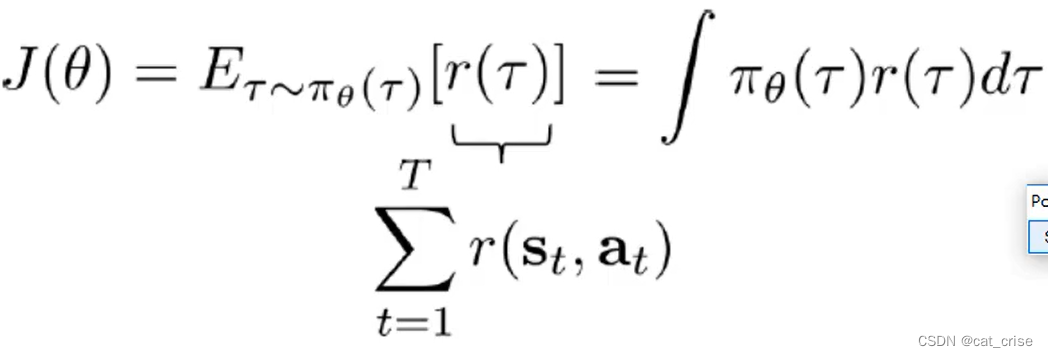 公式的梯度,
公式的梯度,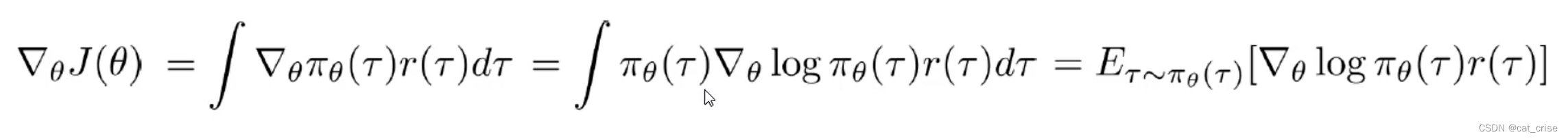
- 最后是按照大数定律思想,直接穷举所有的可能性就好了:
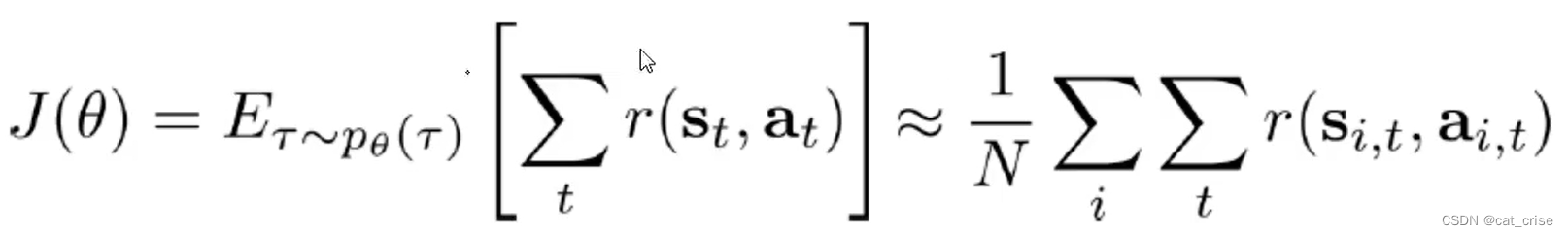
- 来梳理一下,这里的意思是,每一个状态对应地行为的奖励的总和,使得其数学期望最大化。这里为什么要用到数学期望呢? 原因是:求其平均值,希望不断得到更好的reward。
- 这样的话,我们更需要求神经网络中每一个权重,使得每个权重最大化,也就是使得我们的reward最大。所以这里是这样做的目标函数:
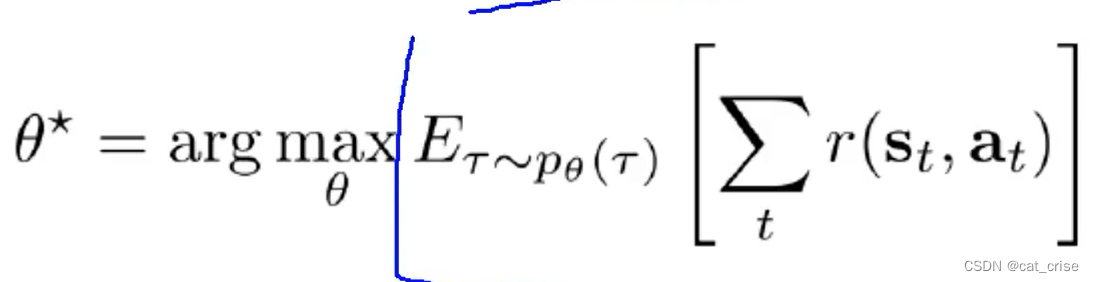
- 这样讲吧::在输入输出过程中,environment对应下一个的action,每一格action对应下一个environment 这样就使得我们将每一步的状态和action放在 一个矩阵里 (trajectory)里面,而这样的话,要使得我们的训练模型更好,就是要求每一步的reward更大,求总的reward更大。
涉及coding层面
- 导包
import torch import torch.nn as nn from torch.distributions import Categorical import gym # pip install box2d box2d-kengz --user(重要,vrep有这个没装----仅供自己看懂) - Critic 网络
- 记得之前的那个均值b吗,我现在要做的事情就是,要评估当前模型做的事情是否是现在应该做的事情,简单来说,就是现在做的事情是否属于利益最大化。然后,我就想到,b,也就是将奖励取均值,不过这里的去均值是随学习过程持续变化的,eg:我的游戏等级越高,我对去b的值要求也就越高。

- 记得之前的那个均值b吗,我现在要做的事情就是,要评估当前模型做的事情是否是现在应该做的事情,简单来说,就是现在做的事情是否属于利益最大化。然后,我就想到,b,
- PPO2版本
- PPO2将设置上下界,简单来说,就是打工者和老板的比值不能超过上下界。
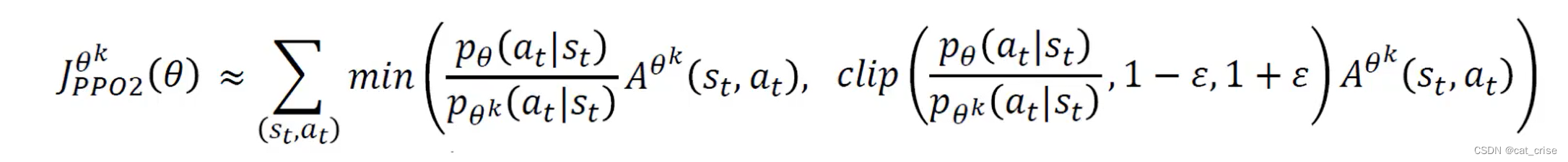
- PPO2将设置上下界,简单来说,就是打工者和老板的比值不能超过上下界。
- 导包