前言:为什么我们钟爱hive?hive提供了一个被称为hive查询语言的sql方言,来查询存储在hadoop集群中的数据。作为用户的我们无需再过多关注如何使用jiva语言去实现数据运算,学会了hql查询,我们仅需要关注查询本身了,省了不少力气。
有同学会好奇,hive在底层到底是如何运作的呢?今天我们来一探究竟
一、hardoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
hadoop核心主要由两部分组成分别是MapReduce(编程模型,负责计算)、HDFS(分布式文件系统,负责存储)。
二、mapreduce概述
首先我们要搞明白何为mapreduce。MapReduce是一种编程模型,该模型可以将大型数据处理任务分解成很多单个的、可以在服务器集群中并行执行的任务。这些任务的计算结果可以合并在一起来计算最终的结果。
mapreduce=map过程+reduce过程,如图所示:
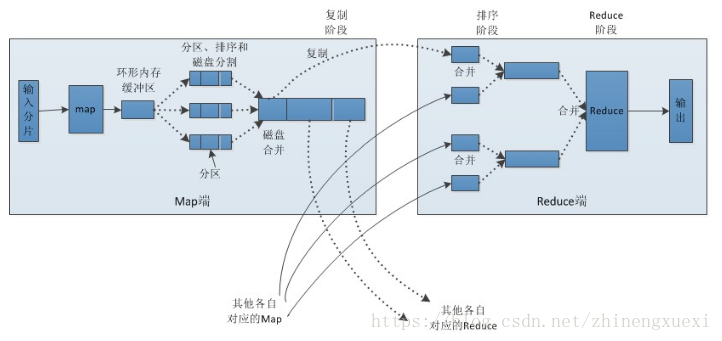
具体过程可参考《MapReduce:大数据之上的简化数据处理》
三、HDFS概述
HDFS hardoop分布式文件系统,管理集群里面的数据。
四、Yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度
版权声明:本文为weixin_44702289原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。