VIT
- Abstract
- 在视觉上,attention与卷积网络一起应用,所需的计算资源大大减少。并且能获得出色的结果。
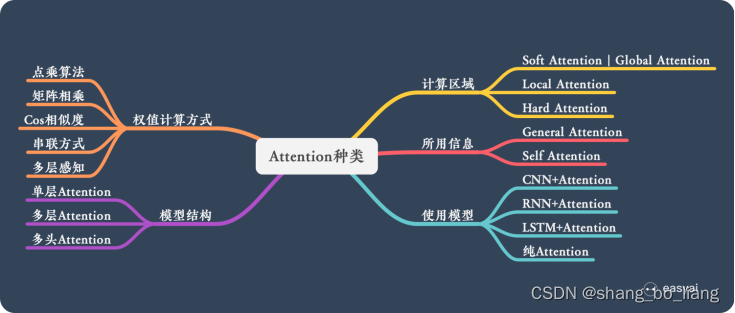
- Attention机制
本质:从关注全部到关注重点。
Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。人的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
优点:
参数少,模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好:就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
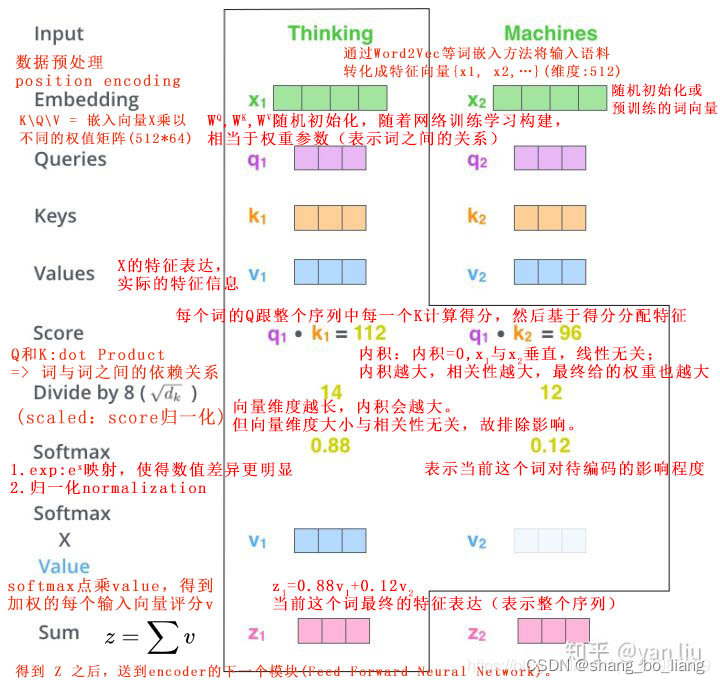
- Attention原理:
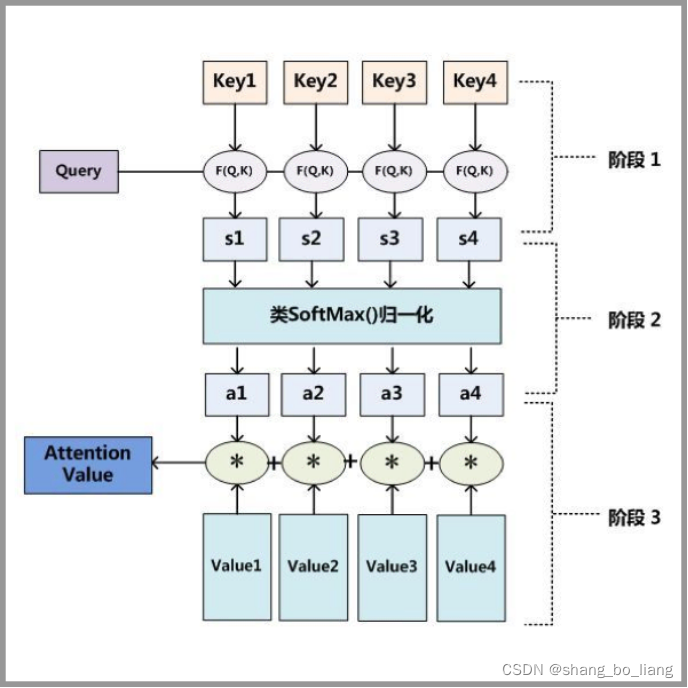
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
- Self-attention:
Self-Attention是Attention的特殊形式。在序列内部做Attention,寻找序列内部的联系。例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
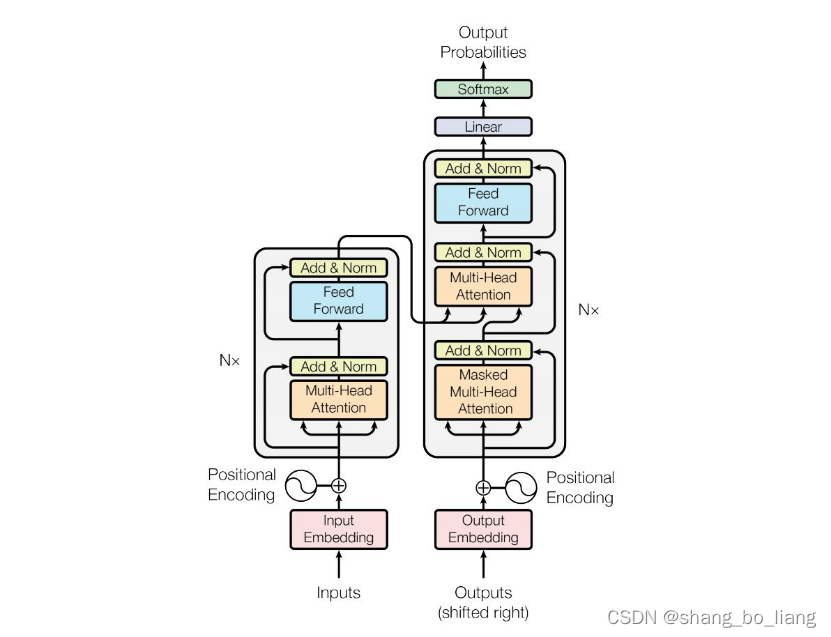
- Transformer模型:
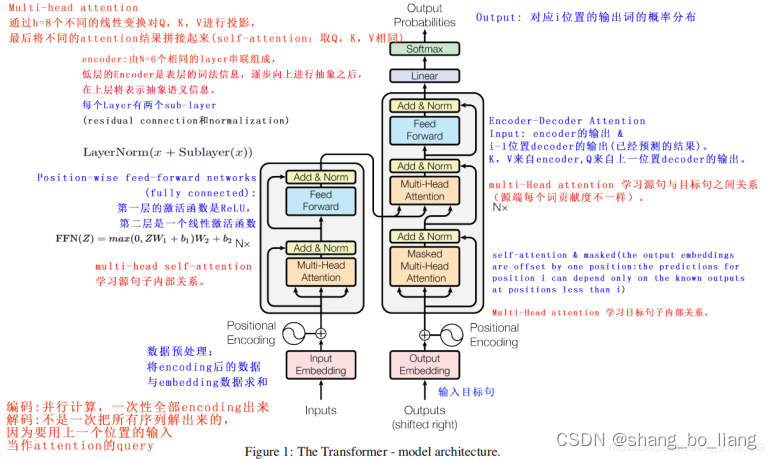
- VIT模型

ViT的核心流程包括图像分块处理 (make patches)、图像块嵌入 (patch embedding)与位置编码、Transformer编码器和MLP分类处理等4个主要部分。
①图像分块处理 (make patches)
第一步可以看作是一个图像预处理步骤。在CNN中,直接对图像进行二维卷积处理即可,不需要特殊的预处理流程。但Transformer结构不能直接处理图像,在此之前需要对其进行分块处理。
假设一个图像x∈H×W×C,现在将其分成P×P×C的patches,那么实际有N=HW/P2个patches,全部patches的维度就可以写为N×P×P×C。然后将每个patch进行展平,相应的数据维度就可以写为N×(P2×C)。这里N可以理解为输入到Transformer的序列长度,C为输入图像的通道数,P为图像patch的大小。
②图像块嵌入 (patch embedding)
将N×(P2×C)的向量维度,转化为N×D大小的二维输入,还需要做一个图像块嵌入的操作,类似NLP中的词嵌入,块嵌入也是一种将高维向量转化为低维向量的方式。所谓图像块嵌入,其实就是对每一个展平后的patch向量做一个线性变换,即全连接层,降维后的维度为D。
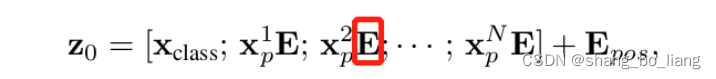
E即为块嵌入的全连接层,其输入大小为(P2×C),输出大小为D。式中给长度为N的向量还追加了一个分类向量,用于Transformer训练过程中的类别信息学习。假设将图像分为9个patch,即N=9,输入到Transformer编码器中就有9个向量,但对于这9个向量而言,该取哪一个向量做分类预测呢?合理的做法就是人为添加一个类别向量,该向量是可学习的嵌入向量,与其他9个patch嵌入向量一起输入到Transformer编码器中,最后取第一个向量作为类别预测结果。所以,这个追加的向量可以理解为其他9个图像patch寻找的类别信息。
③位置编码 (position encoding)
为了保持输入图像patch之间的空间位置信息,还需要对图像块嵌入中添加一个位置编码向量,如上式中的Epos,ViT的位置编码没有使用更新的2D位置嵌入方法,而是直接用的一维可学习的位置嵌入变量。
④ViT前向流程
集合了类别向量追加、图像块嵌入和位置编码为一体的嵌入输入向量后,就直接进入Transformer编码器部分了,主要包括MSA(multi-headed-self-attention)和MLP(多层感知机)两个部分。ViT的编码器前向计算过程可以归纳如下:

第一个式子即前述的图像块嵌入、类别向量追加和位置编码;第二个式子为MSA部分,包括多头自注意力、跳跃连接 (Add) 和层规范化 (Norm) 三个部分,可以重复L个MSA block;第三个式子为MLP部分,包括前馈网络 (FFN)、跳跃连接 (Add) 和层规范化 (Norm) 三个部分,也可以重复L个MSA block。第四个式子为层规范化。最后以一个MLP作为分类头 (Classification Head)。
⑤ViT的向量维度变化图

2.introduction
Transfomer在nlp的使用主要的方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调,在计算机视觉中,开始将cnn的和self-attention相结合。在大规模图像识别中,经典的ResNet架构仍然是最先进的。受Transformer scaling在NLP成功的启发,作者尝试将标准Transformer直接应用于图像,并尽可能少地进行修改。为此,将图像分割为多个patch,并将这些patch进行线性嵌入(sequence of linear embeddings)作为transformer的输入,然后以监督的方式训练模型进行图像分类。当在没有强正则化的ImageNet等中等大小的数据集上进行训练时,这些模型产生的精度比类似大小的ResNets低几个百分点。原因是:transformer缺少cnn固有的归纳偏置(inductive biases)。比如平移不变性(translation equivariance )和局部像素之间的相关性(locality)。在数据不足的情况下,效果不好。。然而,如果在更大的数据集(14M-300M图像)上训练模型,我们发现大规模的训练胜过归纳偏置。(ViT)在进行足够规模的预训练并将其迁移到具有较少数据点的任务时,可以获得良好的效果。当在公众ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViT在多个图像识别基准上接近或超过最先进的水平。该模型在ImageNet、ImageNet- real、CIFAR-100和VTAB等19个任务上的准确率分别为88.55%、90.72%、94.55%和77.63%。
- transformer scale:
Transformer scale指的是对transformer中的attention进行scale,原因是:向量的点积结果会很大,将softmax函数push到梯度很小的区域,会导致梯度消失scaled,会缓解这种现象。
attention公式:
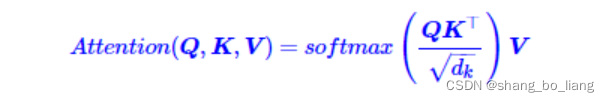
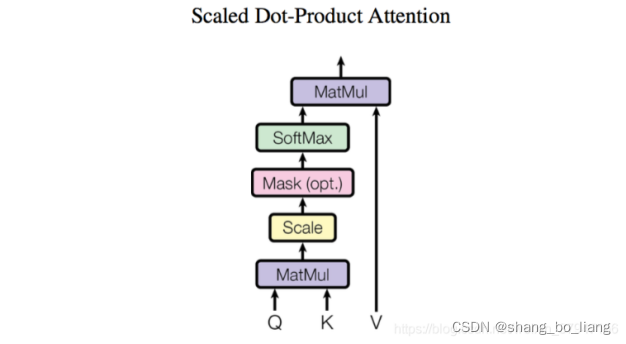
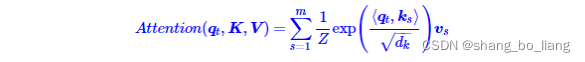
query - key - value思想,当时的该模型聚焦的任务主要是question answering,先用输入的问题query检索key-value memories,找到和问题相似的memory的key,计算相关性分数,然后对value embedding进行加权求和,得到一个输出向量。
其中Z是归一化因子。事实上q,k,v分别是query,key,value的简写,K,V是一一对应的,它们就像是key-value的关系,那么上式的意思就是通过qt这个query,通过与各个ks内积的并softmax的方式,来得到qt与各个vs的相似度,然后加权求和,得到一个dv维的向量。其中因子起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)
- sequence of linear embeddings
- inductive biases
归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。
- translation equivariance
首先介绍等变映射 (equivariant mapping),如下图输入图片X1中的数字'4',通过平移变换T得到了图X2中的数字'4'。F1和F2分别表示两幅图片经过特征映射 的输出,注意 是translation equivariant mapping,在这个例子中特征映射F2通过将X2传入 得到,同时也等价于将X1输入到 中,然后再通过同一个平移变换T得到。
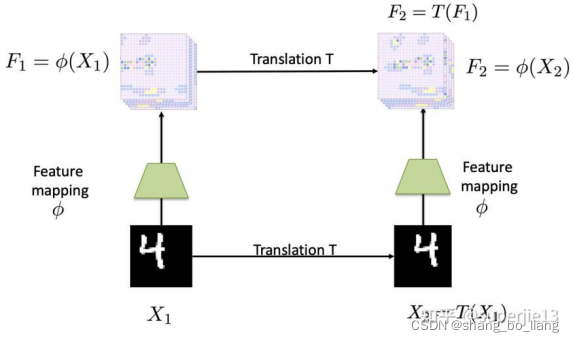
因此如何获得一个具有平移等变性的网络?传统的线性MLPs(ulti-layer Perceptrons(MLPs) 是一个由全连接层构成的标准神经网络)外加一个非线性操作如ReLU,tanh等,可以近似表示任意一个平滑的函数。因此MLPs是一种方案。另外一个选择时卷积操作,实际上卷积操作也具有平移等变形。由于卷积操作中的参数远远少于MLP而且天然具有平移等变性,因此经常出现在图像领域的网络模型中。平移不变形可以通过pooling操作来近似
3.源码
原论文源码:mirrors / google-research / vision_transformer · CODE CHINA (gitcode.net)
Pytorch源码: