本文为Synchronous Bidirectional Learning for Multilingual Lip Reading的记录,原论文请看https://pan.baidu.com/s/1F8ibNfU1flNUK0qqwAHGng,提取码:1111。
来源:BMVC2020
作者单位:中科院计算所vipl
1.翻译原文
1.1摘要
1.本文研究唇语识别的多语言协同作用。
2.世界上有7000种语言,对每种语言分别建模不现实。
3.语言有自己的发音特性,但唇动模式相似。
4.基于2和3我们提出同步双向学习(Synchronous Bidirectional Learning,SBL)框架,以实现多语唇读的有效协同。
5.我们使用音素作为多语言建模的基本单元。
6.原因1:因为它比字母更贴合唇部运动。
7.原因2:在任何语言中,相似的音素都能带来相似的唇部运动。
8.我们提出SBL以填空的方式学习语言的规则。
9.模型需要根据上下文推断空里填什么,上下文可以表示为每种语言的组合规则。
10.为了使模型针对不同语言,我们还让模型预测样本是那种语言。
11.在LRW和LRW1000上SOTA。
1.2介绍
第一段:唇语识别是xxxx的任务。在xxxx有前景。但大部分针对单语言,多语言没被研究过。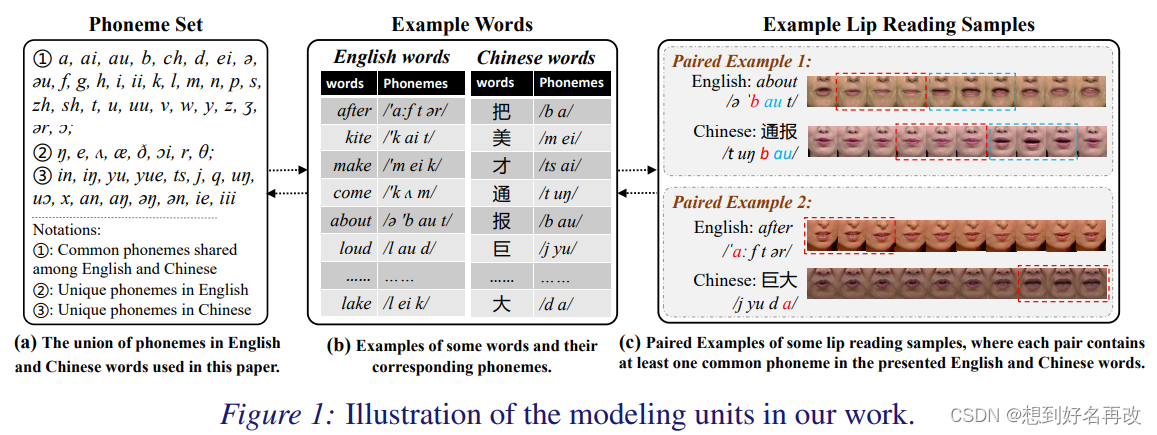
第二段:受限于我们的发音器官,人只能发出有限的音素,不同语言中有很多相似的发音。像素的音素如上图所示。
第三段:不同语言将音素按一定规则组成单词,如果模型可以学到每种语言的规则,识别精度就会较高。基于此,我们将模型的学习过程视为填空题,即无论哪种语言,解码器能根据给出的上下文填空。我们使用SBL块来进行学习和预测。
第四段:我们的贡献:1、第一次探索大型数据集多语言唇语识别;2、我们使用音素作为基本单元来连接多语言唇语识别。提出SBL来学习每种语言的规则。同时让网络预测语言类型,增加针对性;3、性能SOTA。
1.3相关工作
**唇语识别:**有很多好工作xxxx分为两类。第一类看做序列到序列任务,第二类看做视频分类任务。
**多语言学习:**大部分是做多语言音频识别的。我们做多语言唇语识别。
1.4SBL
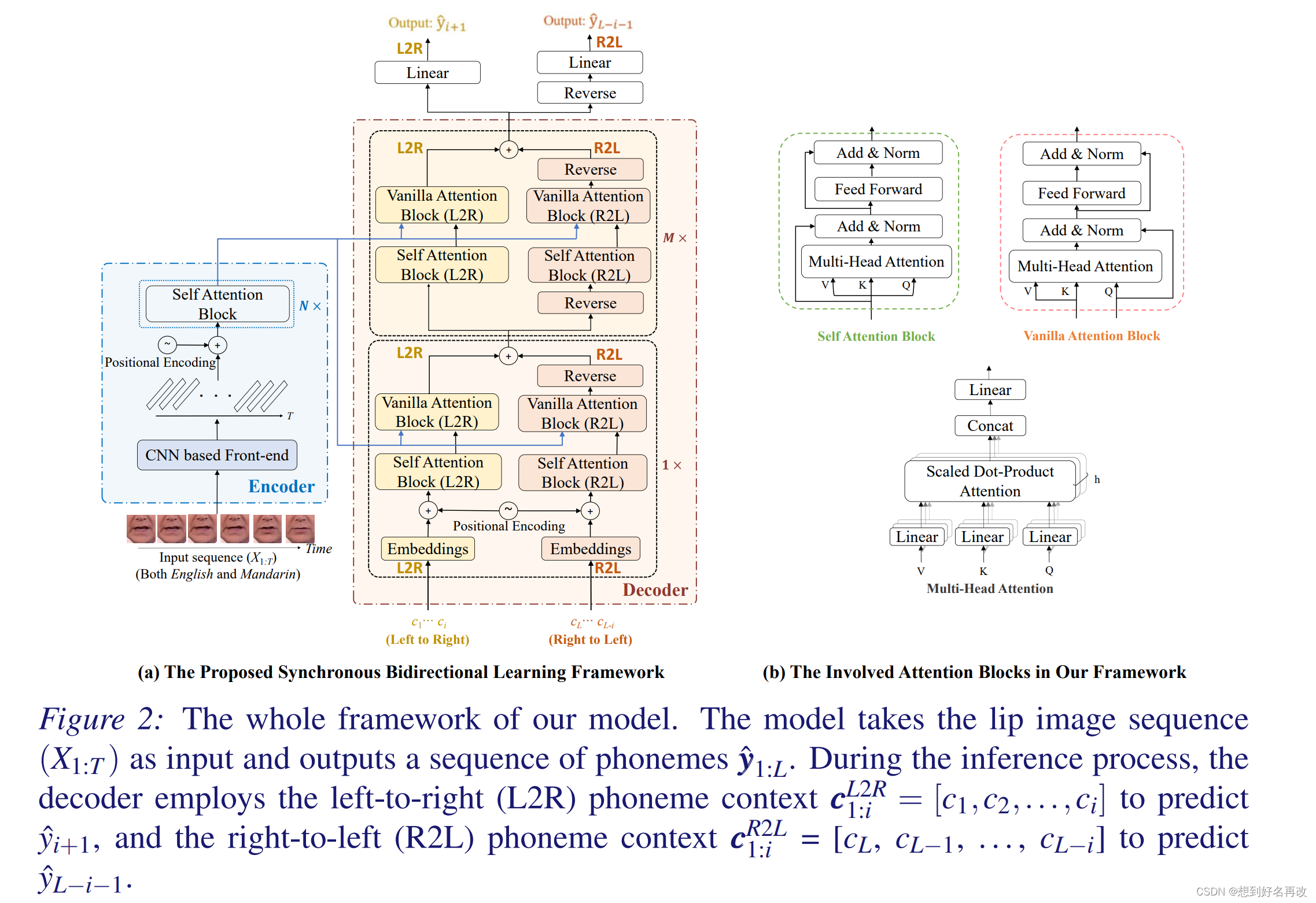
第一段:我们基于Transformer设计我们的模型,结构如上图所示,包含两部分,视觉编码器:将视频编码为特征序列,同步双向解码器:根据特征序列双向学习上下文和每种语言的规则,得到输出序列。
**视觉编码器:**包括卷积网络和多个注意力块。卷积网络3D+2D-ResNet-18得到T×512的特征序列-E θ ( X ) E_\theta(X)Eθ(X)。之后输入多头注意力模块。
**同步双向解码器:**解码器根据E θ ( X ) E_\theta(X)Eθ(X),预测每一个时间步(共L个)的音素。标签由L个音素组成,统一padding到长度为L,如banks->000…0bæŋks0…000(后续TM-ML-Flag实验中可选的添加语言标签来区分英语和汉语,即banks:(eng)000…0bæŋks0…000,银行:(chi)000…0bæŋks0…000)。其中,自注意力模块根据输入序列计算加权和,kqv等于输入序列。朴素注意力模块也输出加权和,但kv等于编码器的输出,q等于之前的自注意力模块的输出。
当预测第i+1个时间步的音素时,第一个SBL块正序分支和倒序分支的输入分别为当前时间步左侧的音素和右侧的音素(测试时是对应时间步的预测结果y ^ \hat{y}y^-这块不太清楚预测怎么来的,训练时是γ×标签y+(1-γ)×上一次的预测结果,γ=0.5)。
学习过程: LRW一般的分类会计算输出概率和标签的交叉熵,输出和标签均为500的向量。本文则计算每一个时间步的音素输出概率和标签的交叉熵,输出和标签均为n的向量,n为音素个数。训练过程的损失函数如下:
测试的时候,对于时间步i会得到正序和倒序两个预测,选择其中一个熵小的作为最终预测。选择过程如下: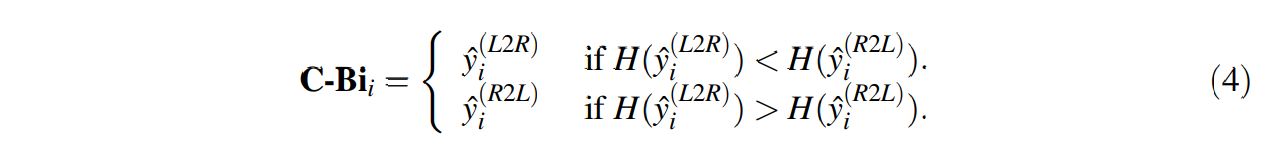
在引入语言标签时,只有当两个语言相同时才会执行上述概率选择操作;当语言不同时,直接选择所有时间步熵和小的分支。
1.5实验
单语言训练和正常设置一样,多语言则混合数据集,但分别给出每种语言的准确率方便对比。
实现细节: LRW原图中心裁切112×112,LRW-1000原图为112×112,之后都随机裁切成88×88。单词标签将转化为音素序列标签,英语40,汉语48,合并56个音素。使用Adam训练。
两个问题:1.是否可以进行多语言唇读;2.SBL对多语言唇读有什么帮助。
后续的符号:TM:编码器相同,使用传统Transformer作为解码器;ML:同时使用两个数据集训练;Flag:添加语言标记;BD:双向学习,SBL块内有无逆序分支。
问题1: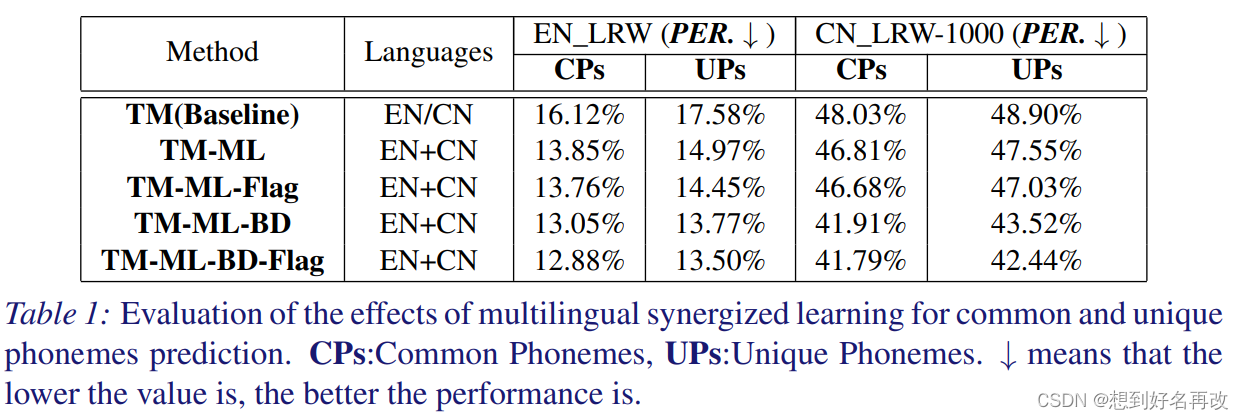
表1给出音素分类准确率,CP表示共有音素,UP表示独有音素,TM-ML-BD-Flag最高。我们发现预测准确率和位置关系不大。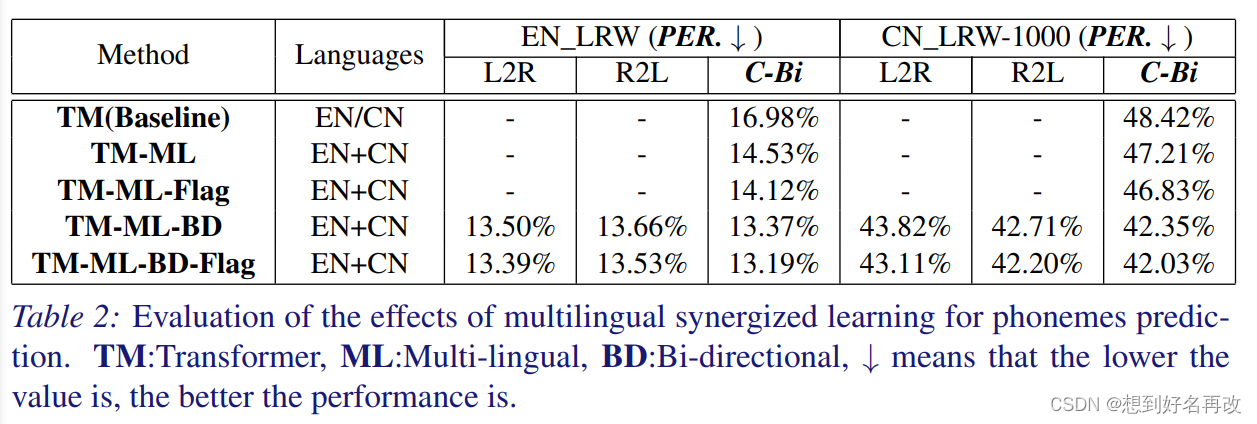
表2给出双向选择的准确率,选出熵较小的预测可以带来较小的精度提升。
问题2: 此问题研究分类精度。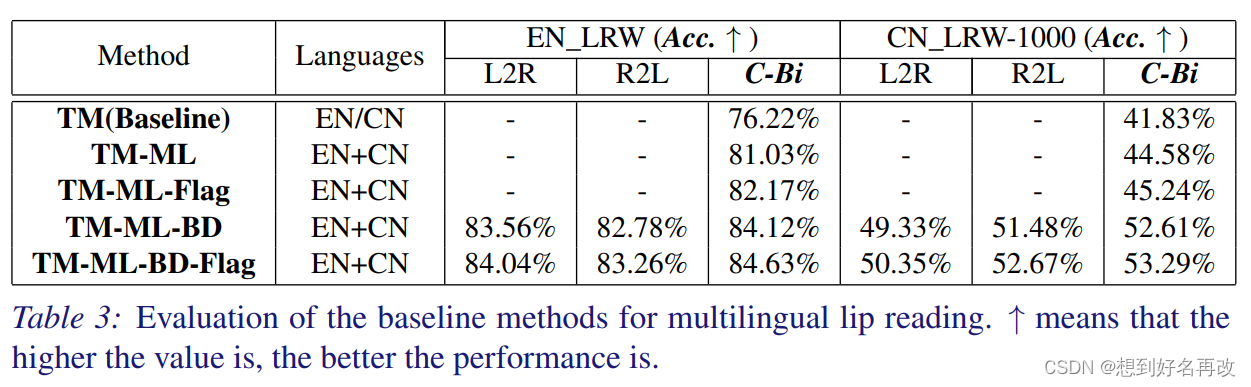
表3研究传统模型下ML,Flag,BD的精度,可见全加精度最高。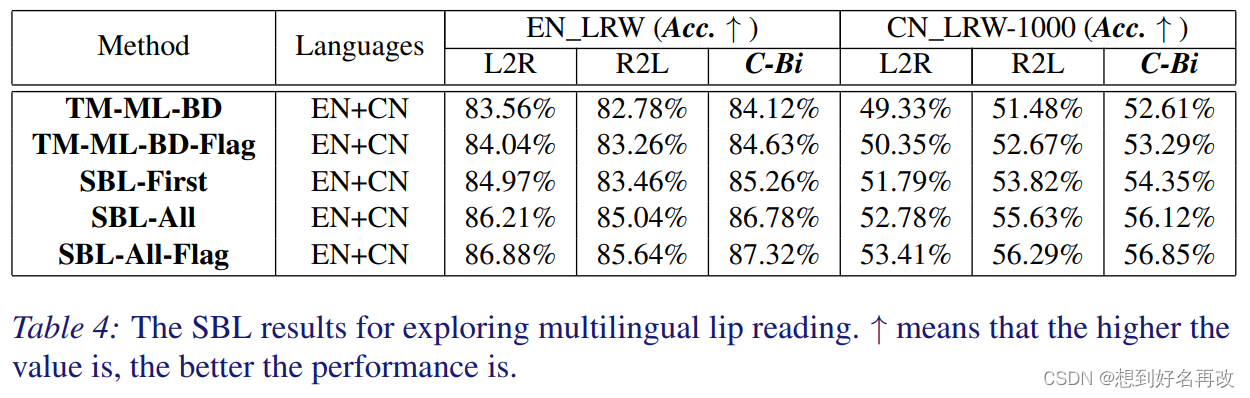
表4对比网络结构,逐步引入SB,可见全为SB精度最高。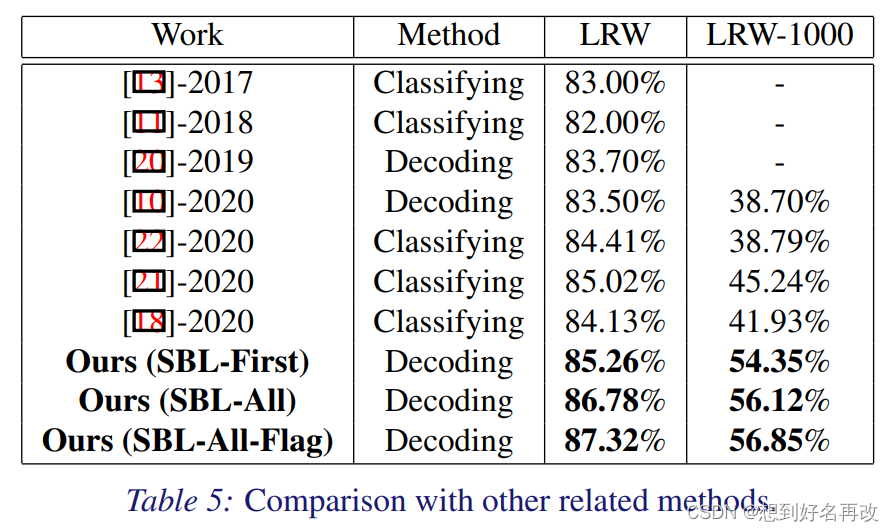
表5和其他方法对比,提升较大。
1.6结论
受多语言语音识别的启发,我们第一次研究了多语言唇语识别。效果不错。
2.相关文章
给出几篇重要的参考文献:
5.Sequence-Based Multi-Lingual Low Resource Speech Recognition
6.Connectionist temporal classification labelling unsegmented sequence data with recurrent
9.Towards zero-shot learning for automatic phonemic transcription
25.Multilingual End-to-End Speech Recognition with A Single Transformer on Low-Resource Languages