gobblin介绍
一种分布式数据集成框架,可简化大数据集成的常见方面,例如流式数据和批处理数据生态系统的数据摄取、复制、组织和生命周期管理。
Gobblin是LinkedIn公司开发的用于在Hadoop环境里统一数据抽取的框架。目前Gobblin可以建立多种pipelines,比如数据质量检查器、源数据管理、开发和其他操作。
Gobblin支持多种类型的数据源。例如数据库,Rest Api服务,FTP/SFTP,hdfs文件系统等,Gobblin对其中的数据抽取,转换和加载,包括任务调度,任务分片,错误处理,任务状态管理,数据质量检查,数据发布等。Gobblin对这些不同的数据源统一源数据管理。
Gobblin是一款集可用性,容错性,质量保证,可扩展性,处理数据模型变化的简单易用的数据抽取工具。
gobblin执行模式
Standalone
在单个盒子上作为独立应用程序运行,还支持嵌入模式
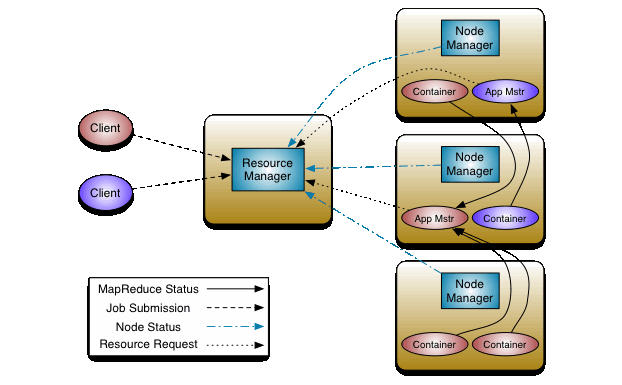
Mapreduce模式
在多个Hadoop版本上作为mapreduce应用程序运行。还支持Azkaban启动mapreduce作业

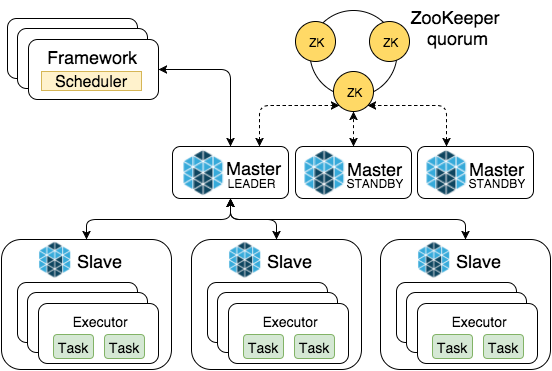
Cluster / Yarn
作为具有主节点和工作节点的独立集群运行。此模式支持高可用性,也可以在裸机上运行
Could
在公共云上作为弹性集群运行。此模式支持高可用性。
Gobblin是LinkedIn公司开发的用于在Hadoop环境里统一数据抽取的框架。目前Gobblin可以建立多种pipelines,比如数据质量检查器、源数据管理、开发和其他操作。
Gobblin支持多种类型的数据源。例如数据库,Rest Api服务,FTP/SFTP,hdfs文件系统等,Gobblin对其中的数据抽取,转换和加载,包括任务调度,任务分片,错误处理,任务状态管理,数据质量检查,数据发布等。Gobblin对这些不同的数据源统一源数据管理。
Gobblin是一款集可用性,容错性,质量保证,可扩展性,处理数据模型变化的简单易用的数据抽取工具。
gobblin架构描述
Gobblin 是围绕可扩展性的理念构建的,即用户应该很容易添加新适配器或扩展现有适配器以使用新源并开始在任何部署设置中从新源中提取数据。Gobblin 的架构体现了这一思想,如下图 1 所示:
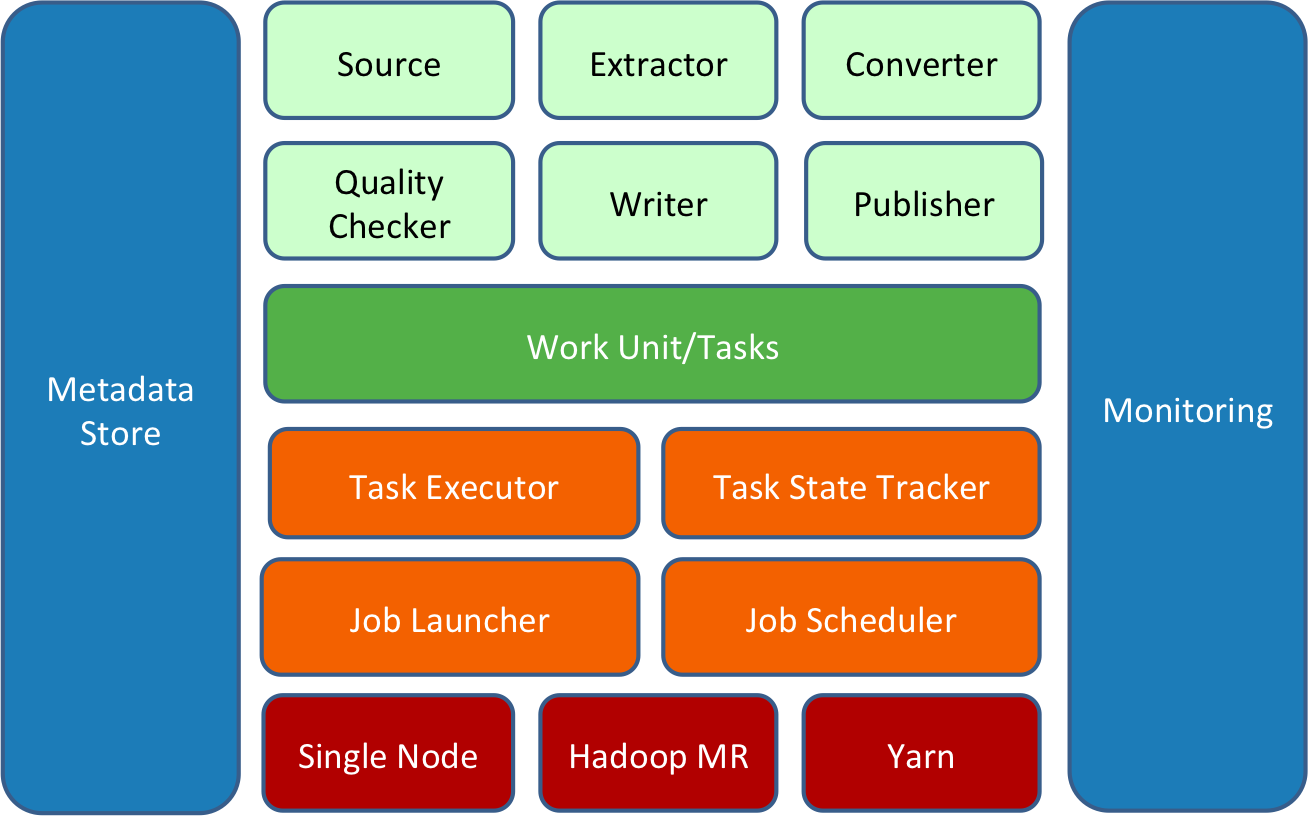
Gobblin 作业建立在一组构造之上(如上图中的浅绿色框所示),它们以某种方式协同工作并完成数据提取工作。所有的结构都可以通过作业配置插入,并且可以通过添加新的或扩展现有的实现来扩展。这些构造将在Gobblin Constructs中讨论。
一个 Gobblin 作业由一组任务组成,每个任务对应一个要完成的工作单元,并负责提取一部分数据。Gobblin 作业的任务由 Gobblin 运行时(上图中的橙色框所示)在选择的部署设置(上图中的红色框所示)上执行。
Gobblin 运行时负责在选择的部署设置上运行用户定义的 Gobblin 作业。它处理常见的任务,包括作业和任务调度、错误处理和任务重试、资源协商和管理、状态管理、数据质量检查、数据发布等。
Gobblin 目前支持两种部署模式:单节点上的独立模式和 Hadoop 集群上的 Hadoop MapReduce 模式。我们还在努力增加对在YARN上部署和运行 Gobblin 作为本机应用程序的支持。可以在Gobblin 部署中找到有关 Gobblin 部署的详细信息。
Gobblin 的运行和操作由一些组件和实用程序(如上图中的蓝色框所示)支持,这些组件和实用程序处理元数据管理、状态管理、指标收集和报告以及监控等重要事情。