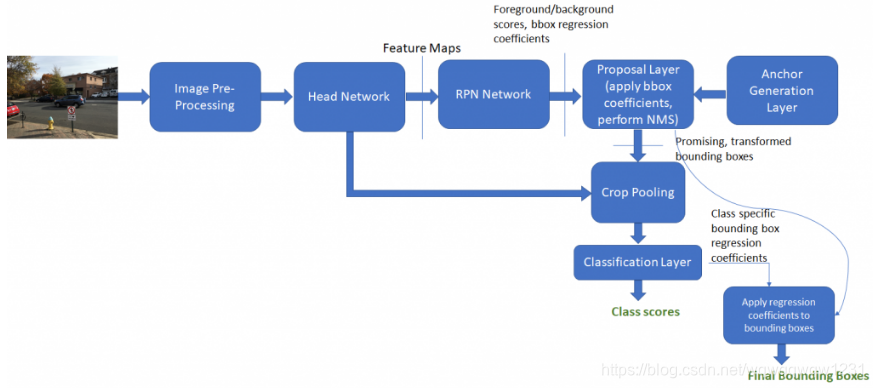
文章目录
Faster RCNN作为two stage目标检测方法的代表作,其中有很多模块非常经典,在后续的two stage的模型中有广泛的应用。而且在3D Object Detection的问题中,也是如此。这就回顾一下Faster RCNN的网络结构。
这里推荐一个博客,http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/,对faster rcnn的网络结构讲的非常详细。本博客就按照这个思路进行讲解,只是借助于代码,展现更多的细节。
Faster RCNN
整体架构如下,接下来我们就按照这个顺序依次介绍每一个模块。
Image Pro-Processing
前处理包括减均值,和归一化大小,这里没有直接resize,而是保存了图片长宽比的缩放。
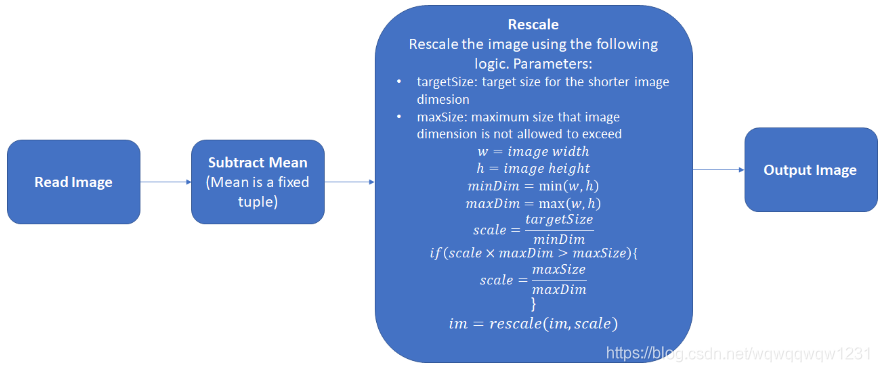
注意:下面将加入网络结构可视化,每一个小方块代表一个tensor,小方块上面的字是tensor的名字,下面的字是tensor的大小。例如43600800表示4个batch,3个通道,600800的大小。
主干网络
主干网络可以使用VGG或者ResNet,去除最后面用于分类的全连接层,用于特征提取。

Anchor Generate Layer
这一个子网络是生成37509个anchor,9代表尺度和长宽比不同的9个anchor,分别对应37*50的feature map中的feature的位置。这一块是用numpy先生成,然后转为tensor,具体不展开,比较简单,用grid函数就可以实现。
Region Proposal Network
这一部分是生成proposal的网络,并计算RPN的loss。
Proposal Layer
本部分网络以主干网络得到的特征作为输入,输出特定数量的RoI,也就是proposal,具体网络见下图:
首先在主干网络输出的特征之后加入分类头和回归头,分别对37509个anchor做分类和回归。分类:每个anchor都是二分类,也就是只需要分类是否为前景,所以得到的channel数为18,其实是9*2,每个anchor属于前景还是背景的分数。回归:每个anchor计算相对应的proposal需要对位置和尺度有一定的调整,回归头是就是回归每个anchor变为proposal所需要的4个参数,所以channel数量为36。
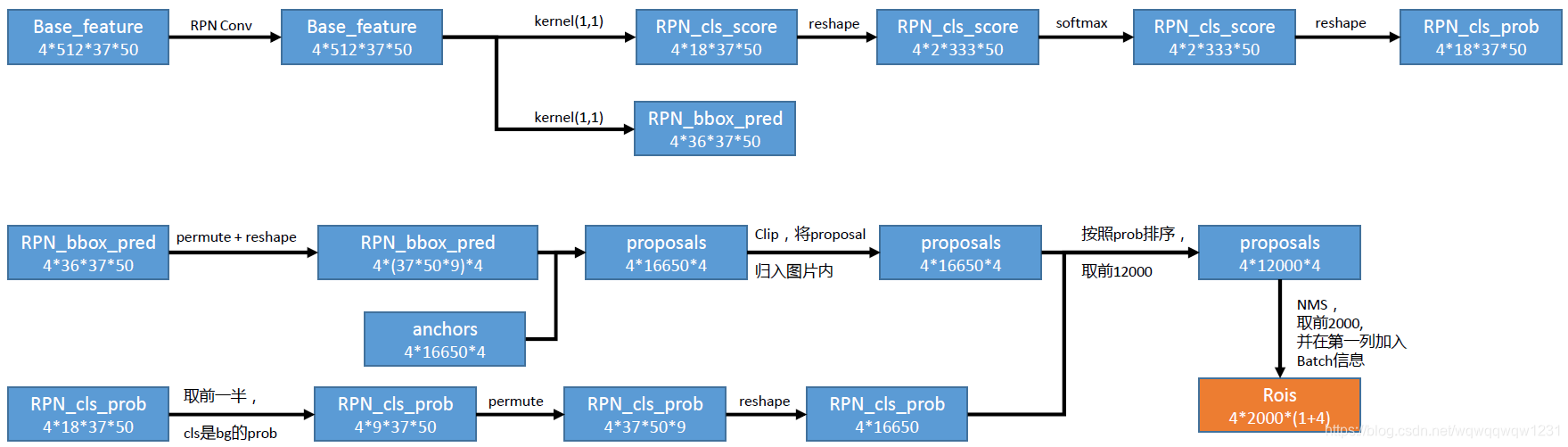
然后使用得到的回归的值,与Anchor Generate Layer生成的相对应的anchor做计算,得到proposal,然后将全部proposal clip到图片内部(例如图片边上的点的anchor有很大一部分在图片外,生成的proposal也有很大几率在图片外)。使用分类头得到的结果,取前9个值认为是每个proposal是前景的分数,以此对proposal进行排序,取前12000个 。然后进行NMS,取前2000个,加入batch信息,作为RoI。(也就是说4个batch总共取2000个)
Anchor Target Layer
这个子网络主要计算RPN的target,主要结构如下图:
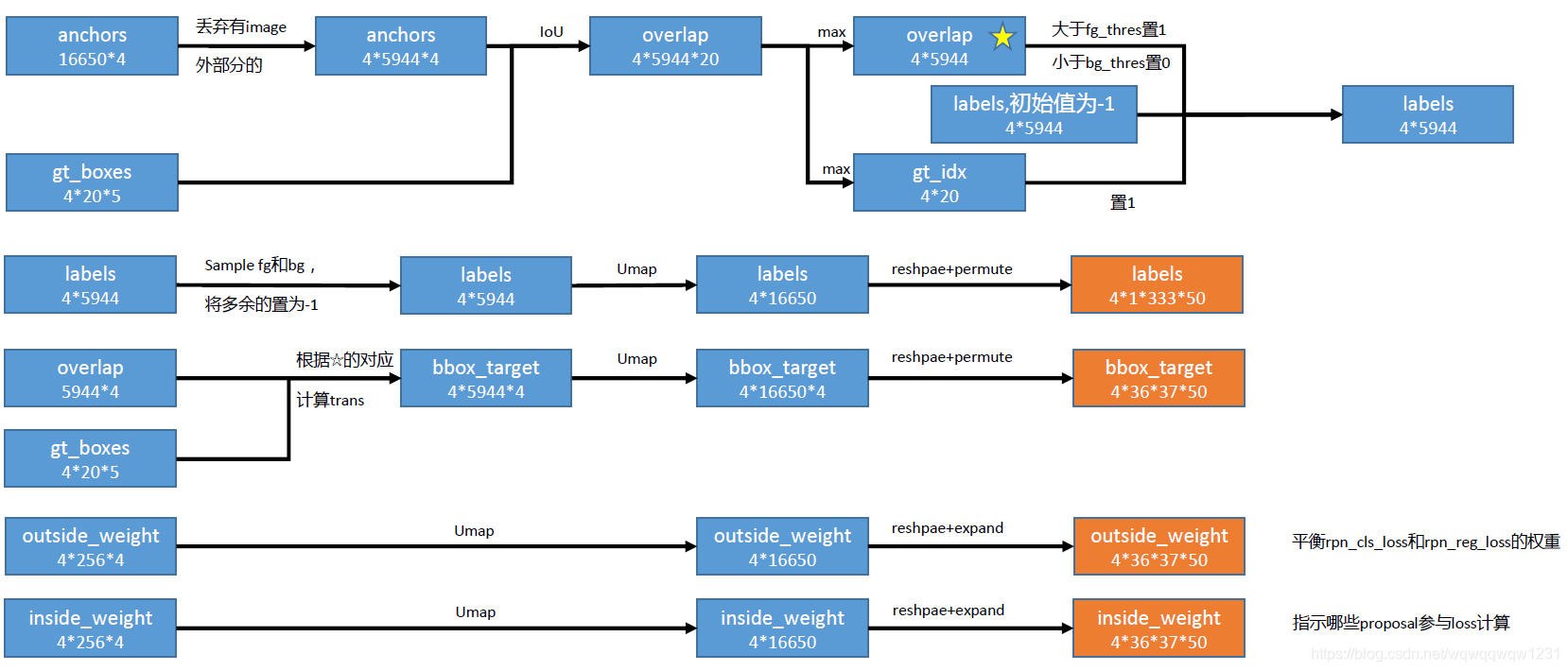
首先计算anchor和groundtruth box的IoU,通过IoU判断anchor的label。这里分为两支:
(1)寻找与每个anchor IoU最大的gt box,当其IoU大于一定阈值时,该anchor为前景,小于一定阈值时,该anchor为背景,其他情况在计算loss中不考虑(label为-1)。
(2)寻找与每个gt box IoU最大的anchor,将这些anchor的label置为1,因为每个gt box至少需要有一个anchor来预测。
通过上述方法,得到label为1的anchor,然后计算这些anchor变为proposal需要回归的参数。
首先采样背景anchor和前景anchor,将多余的anchor的label置-1,不考虑,然后更新anchor的label。同时,根据判断anchor的label的过程中的与gt box的对应关系,计算那些label为1的anchor所需要回归的target。
同时更新outside weight,这个是用于平衡rpn的loss中分类loss和回归loss的权重。inside weight是根据anchor的label得来,label为-1的anchor不参与loss的计算。
Compute RPN Loss
有了Proposal Layer得到的proposal和Anchor Target Layer得到的target,就可以计算RPN的loss,具体见下图
对Label的计算:Anchor Target Layer生成了每个anchor对应的target,但其实大多数的anchor的label都是-1,也就是不考虑,每个batch只有256个前景+背景,然后使用CrossEntropy计算Label的loss。
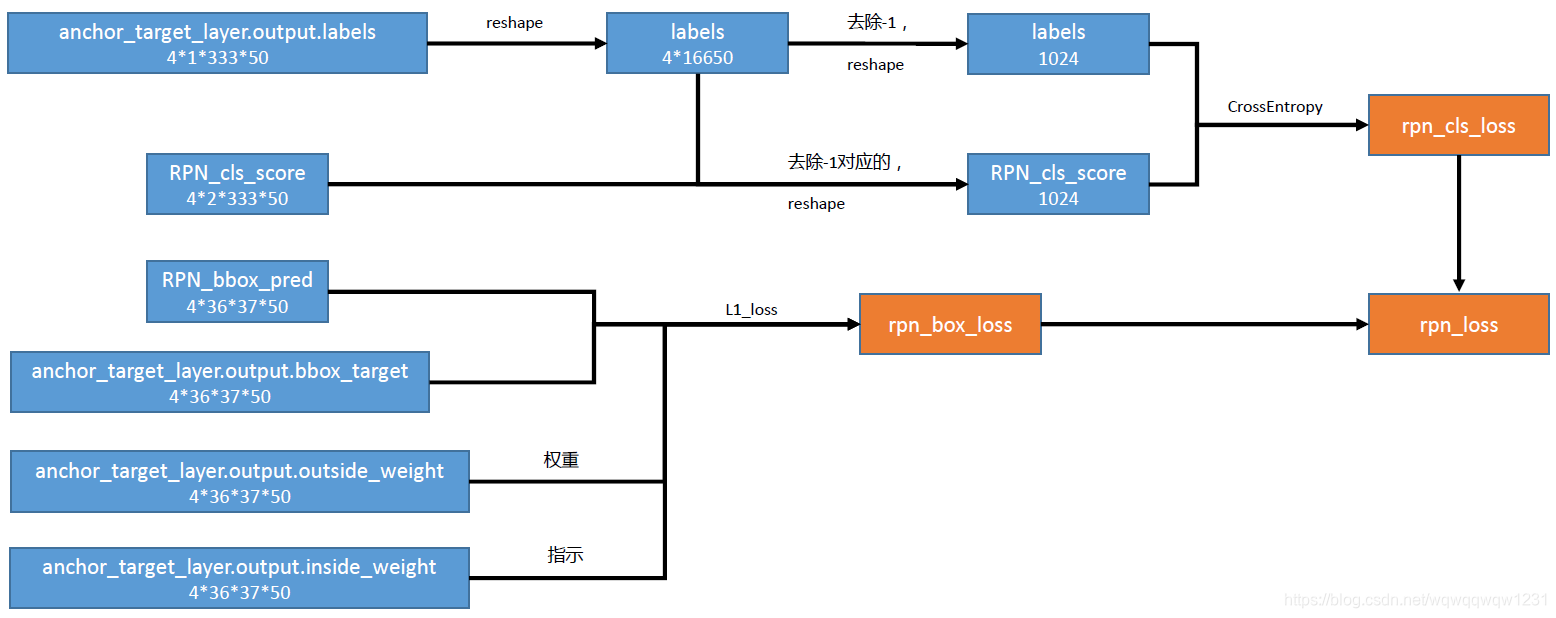
对box位置的计算:inside_weight其实是与lable相关的,label不为-1对应inside_weight为1,label为-1对应inside_weight为0,inside_weight表示是否参与regression loss的计算。outside_weight都是一样的,是用于平衡rpn_cls_loss和rpn_reg_loss之间的权重。Regression Loss使用L1 Loss进行计算。
然后将rpn_cls_loss与rpn_reg_loss相加得到rpn最终的loss。
Proposal Target Layer
Proposal Target Layer主要作用是从RPN中提取一些RoI,以供后面RCNN进行优化,并计算这些RoI对应的target。具体结构见下图: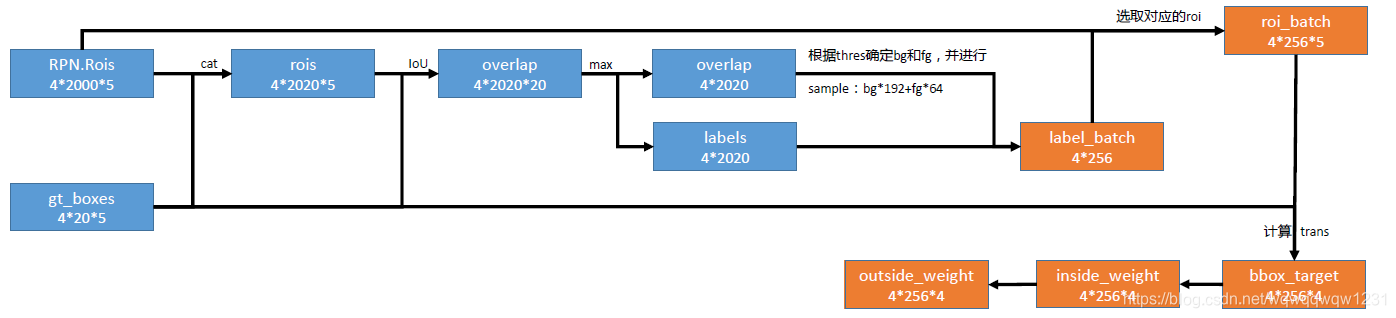
由Proposal Layer得到的2000个RoI,然后与20个gt_boxes放到一块,形成每个batch有2020个RoI。然后对着gt_boxes计算IoU,然后根据IoU的大小确定每个RoI的是属于前景还是背景,然后进行采样,采样数量是每个batch前景64个,背景192个。然后根据选出来的RoI组成roi_batch,然后对每个RoI与相对应的gt box计算要回归的target。然后根据target计算inside_weight和outside_weight,其中inside_weight也是为了平衡reg_loss与cls_loss,outside_weight表示哪些RoI参与计算。
RCNN
RCNN是对RoI进行分类,并对RoI的box进行优化,总结结构如下:
RoI Pooling
RoI Pooling要做的是在不同大小的RoI中提取同一尺寸的feature map,也就是上图的align部分,在Faster RCNN中使用Crop Pooling,但在Mask RCNN中提出了使用Align Pooling,明显Align Pooling效果更好,所以后面的方法基本使用Align Pooling。在Faster RCNN中,每个RoI提取7x7的feature map,所以得到的pooled feature包括1024个roi(一个batch 4张图片,每张图片256个RoI),每个feature有512个channel。
Classification Layer
这部分主要判断每个RoI所属的类别,和对RoI进行再一次优化。将得到的pooled feature送入全连接层中,然后分成两个分支,一个分支预测RoI所属类别(20个前景类+1个背景),另一个分支预测每个RoI的回归值,然后使用Proposal Target Layer中预测的label来选择使用哪一组优化值。
Classification Loss
由Classification Layer得到了每个RoI的分类Label和回归预测值,就可以结合Proposal Target Layer中的target计算RCNN的Loss了,结构图如下: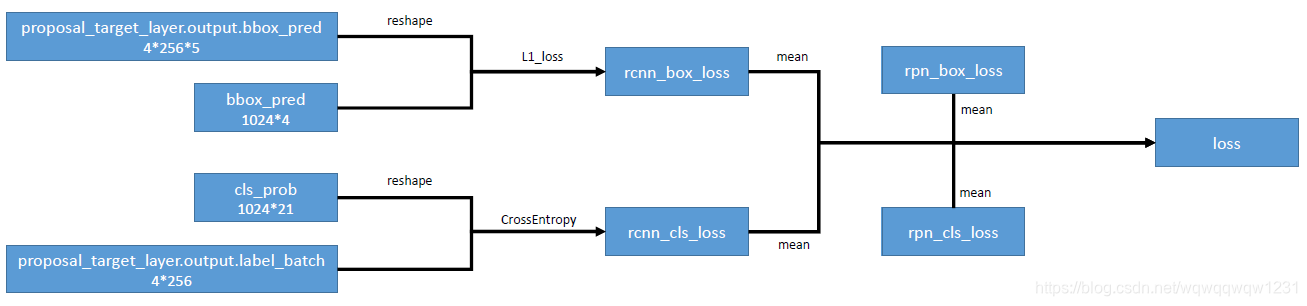
Label使用CrossEntropy Loss,Box使用L1 Loss,然后加上RPN的Loss,就是总Faster RCNN的总Loss。
Inference
推断过程如下图,其中不包括Anchor Target Layer 和 Proposal Target Layer,这两层是用来训练的。