文章目录
一、sparksql概述
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
Hive,是将Hive SQL转换成MapReduce然后提交到集群中去执行,大大简化了编写MapReduce程序的复杂性,由于MapReduce这种计算模型执行效率比较慢,所以Spark SQL应运而生,它是将Spark SQL转换成RDD,然后提交到集群中去运行,执行效率非常快!
二、sparksql四大特性
易整合- 将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作
统一的数据源访问- sparksql以相同方式访问任意数据源
- SparkSession.read.文件格式方法(对应文件格式的路径)
兼容hive- 支持hivesql的语法
标准的数据连接- 可以使用行业的jdbc和odbc来连接数据库
三、DataFrame简介
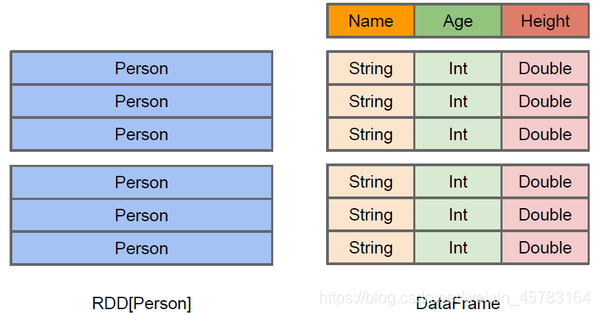
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化.
DataFrame与RDD的区别
rdd里面存放的是java对象,dataframe来说它里面存放的是Row对象,Row也就是说把每一行数据封装在一个Row对象
dataframe中除了数据之外,还包括了数据结构信息,这个结构信息,我们叫做schema(比如当前它有哪些列名称和列的类型)
DataFrame还引入了off-heap,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。
DataFrame与RDD的优缺点
1、rdd优缺点
- 优点
1、编译时类型安全
2、面向对象编程的风格 - 缺点
1、序列化和反序列化性能开销很多
2、GC性能开销:频繁的创建对象和销毁,会带来大量的GC
2、dataFrame的优缺点
dataFrame它引入schema和off-heap(使用不在jvm堆以内的内存,直接使用操作系统中的内存)
- 优点
1. 引入了schema解决了rdd的这个缺点(序列化和反序列化性能开销很多)
2. 引入了off-heap解决了rdd的这个缺点(GC性能开销很大) - 缺点
- 丢失了RDD的优点
- 不在是编译时类型安全
- 也不是面向对象编程风格
读取数据源创建DataFrame
读取文本文件创建DataFrame
(1)在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上。person.txt内容为:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
上传数据文件到HDFS上:
hdfs dfs -put person.txt /
(2)在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
先执行 spark-shell --master local[2]
val lineRDD= sc.textFile("/person.txt").map(_.split(" "))

(3)定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)

(4)将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))

(5)将RDD转换成DataFrame
val personDF = personRDD.toDF

(6)对DataFrame进行处理
personDF.show

personDF.printSchema

(7)、通过SparkSession构建DataFrame
使用spark-shell中已经初始化好的SparkSession对象spark生成DataFrame
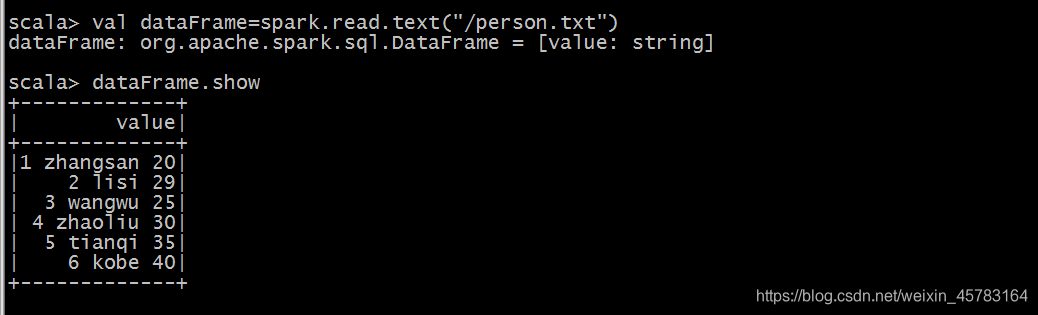
val dataFrame=spark.read.text("/person.txt")
读取json文件创建DataFrame
(1)数据文件
使用spark安装包下的
/opt/bigdata/spark/examples/src/main/resources/people.json文件
(2)在spark shell执行下面命令,读取数据
val jsonDF= spark.read.json("file:///opt/bigdata/spark/examples/src/main/resources/people.json")

(3)接下来就可以使用DataFrame的函数操作


四、DataFrame常用操作
DSL风格语法
DataFrame提供了一个领域特定语言(DSL)来操作结构化数据。
//创建rdd
val rdd1=sc.textFile("/person.txt").map(_.split(" "))
//定义样例类
case class Person(id:Int,name:String,age:Int)
//rdd于样例类关联
val rdd2=rdd1.map(x => Person(x(0).toInt,x(1),x(2).toInt))
//rdd转换成dataFrame
val personDF=rdd2.toDF
//打印schema
personDF.printSchema
//查询数据
personDF.show
//查询name字段
personDF.select("name").show
personDF.select($"name").show
personDF.select(col("name").show
//实现age字段结果加1
personDF.select($"name",$"age",$"age"+1).show
//查询age大于30的用户信息
personDF.filter($"age" >30).show
//查询age大于30的用户人数
personDF.filter($"age" >30).count
//按照age进行分组统计不同的age出现的人的次数
presonDF.groupBy("age").count.show
SQL风格语法
可以把DataFrame看成是一张关系型数据表
- 需要把dataFrame注册成一张表
presonDF.registerTempTable("t_person")
- 通过SparkSession调用sql方法,传入对应sql语句
spark.sql(sql语句)
spark.sql("select * from t_person").show
spark.sql("select * from t_person where id=1").show
spark.sql("select * from t_person order by age desc").show
六、DataSet
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎.
DataFrame、DataSet、RDD的区别
假设RDD中的两行数据长这样:
那么DataFrame中的数据长这样:
那么Dataset中的数据长这样: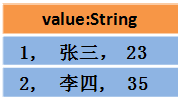
或者长这样(每行数据是个Object):
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
- DataSet可以在编译时检查类型
- 并且是面向对象的编程接口
DataFrame与DataSet互相转换
- DataFrame转换成DataSet
○ df.as[强类型] - DataSet转换成DataFrame
○ ds.toDF
创建DataSet
(1)通过spark.createDataset创建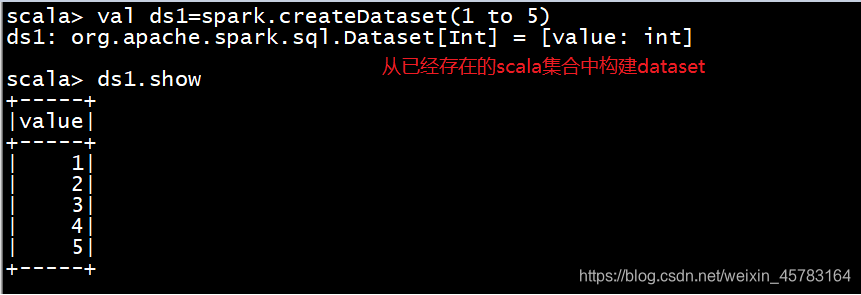
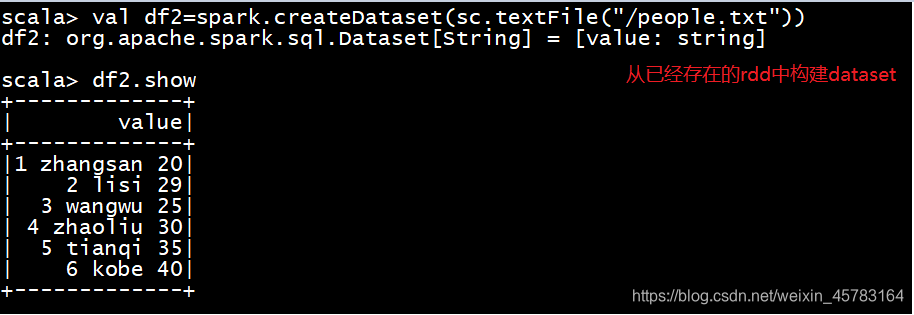
(2)通toDS方法生成DataSet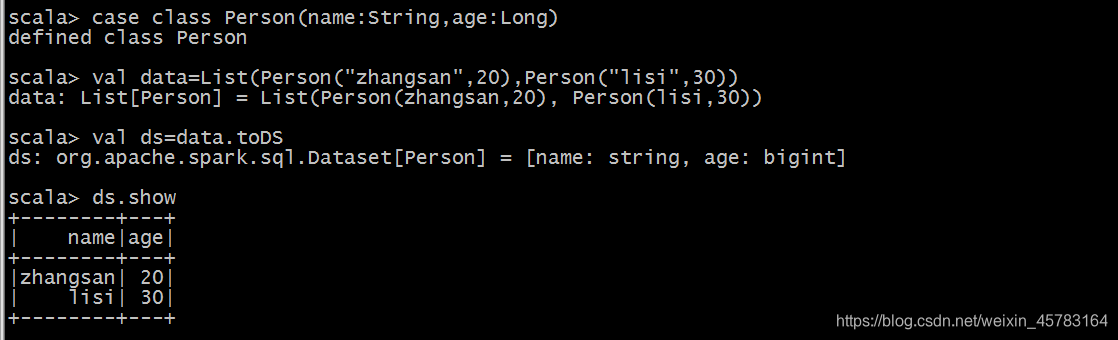
(3)通过DataFrame转化生成
使用**as[类型]**转换为DataSet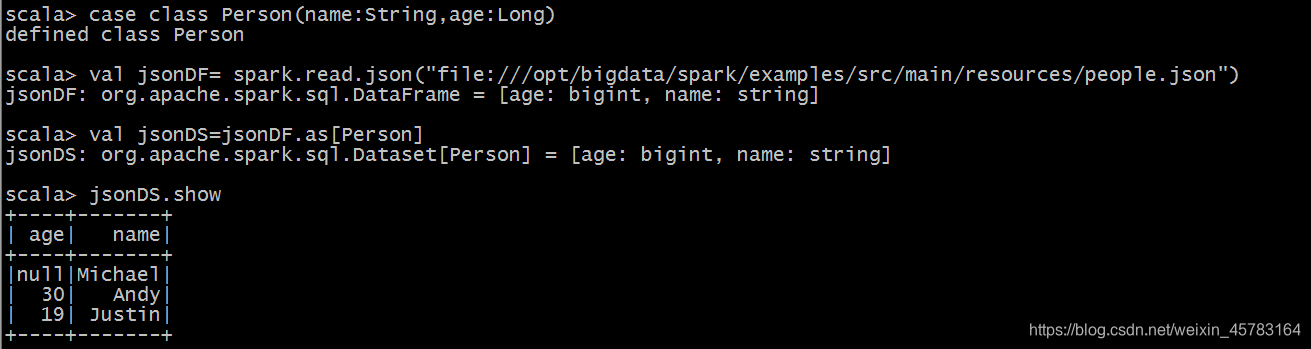
七、编程实现RDD转换成DataFrame
利用反射机制
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.0.2</version>
</dependency>
代码开发
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
//todo:需求:将rdd转换成dataFrame(利用反射机制)
case class Person(id:Int,name:String,age:Int)
object CaseClassSchema {
def main(args: Array[String]): Unit = {
//1、创建SparkSession对象
val spark: SparkSession = SparkSession.builder().appName("CaseClassSchema").master("local[2]").getOrCreate()
//2、获取SparkContext
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//3、读取文件
val data: RDD[Array[String]] = sc.textFile("E:\\person.txt").map(_.split(" "))
//4、将rdd与样例类关联
val personRDD: RDD[Person] = data.map(x => Person(x(0).toInt,x(1),x(2).toInt))
//5、将rdd转换成dataFrame
//手动导入隐式转换
import spark.implicits._
val personDF: DataFrame = personRDD.toDF
//------------------DSL风格语法------------start
//打印schema元信息
personDF.printSchema()
//显示数据,默认展示20条数据
personDF.show()
//展示第一条数据
println(personDF.first())
//查询name字段对应的结果数据
personDF.select("name").show()
personDF.select($"name").show()
personDF.select(new Column("name")).show()
//把age字段对应的结果加1
personDF.select($"name",$"age",$"age"+1).show()
//过滤年龄大于30的人的信息
personDF.filter($"age" >30).show()
//过滤年龄大于30的人数
println(personDF.filter($"age" >30).count())
//按照age分组统计不同年龄出现的次数
personDF.groupBy("age").count().show()
//------------------DSL风格语法------------end
//------------------SQL风格语法-------------start
personDF.createTempView("t_person")
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where id =1").show()
spark.sql("select * from t_person order by age desc").show()
//------------------SQL风格语法-------------end
//关闭sparkSession
spark.stop()
}
}
通过StructType直接指定Schema
当case class不能提前定义好时,可以通过以下三步创建DataFrame
- 将RDD转为包含Row对象的RDD
- 基于StructType类型创建schema,与第一步创建的RDD相匹配
- 通过sparkSession的createDataFrame方法对第一步的RDD应用schema创建DataFrame
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
//todo:需求:将rdd转换成dataFrame(通过StructType指定schema)
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
//1、创建SparkSession
val spark: SparkSession = SparkSession.builder().appName("SparkSqlSchema").master("local[2]").getOrCreate()
//2、创建SparkContext
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//3、读取文件数据
val data: RDD[Array[String]] = sc.textFile("e:\\person.txt").map(_.split(" "))
//4、把RDD[Array[String]] 转换成RDD[Row]
val rowRDD: RDD[Row] = data.map(x => Row(x(0).toInt,x(1),x(2).toInt))
//5、指定dataFrame的schema
val schema = StructType(
StructField("id", IntegerType, true) ::
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) :: Nil)
val personDF: DataFrame = spark.createDataFrame(rowRDD,schema)
//打印schema
personDF.printSchema()
//打印结果数据
personDF.show()
//dataFrame注册成一张表
personDF.createTempView("t_person")
spark.sql("select * from t_person").show()
//关闭
spark.stop()
}
}
编写Spark SQL程序操作HiveContext
HiveContext是对应spark-hive这个项目,与hive有部分耦合, 支持hql,是SqlContext的子类,在Spark2.0之后,HiveContext和SqlContext在SparkSession进行了统一,可以通过操作SparkSession来操作HiveContext和SqlContext。
导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.0.2</version>
</dependency>
代码开发
import org.apache.spark.sql.SparkSession
//todo:需求:利用sparkSQL操作hivesql
object SupportHive {
def main(args: Array[String]): Unit = {
//1、创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName("SupportHive")
.master("local[2]")
.enableHiveSupport() //开启sparksql支持hivesql
.getOrCreate()
//2、可以操作hivesql
//2.1创建hive表
spark.sql("create table student(id int,name string,age int) row format delimited fields terminated by ',' ")
//2.2 加载数据到hive表中
spark.sql("load data local inpath './data/student.txt' into table student")
//2.3 查询表数据
spark.sql("select * from student").show()
//关闭sparkSession
spark.stop()
}
}
八、SparkSql从MySQL中加载数据
通过IDEA编写SparkSql代码
代码开发
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* todo:Sparksql从mysql中加载数据
*/
object DataFromMysql {
def main(args: Array[String]): Unit = {
//todo:1、创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("DataFromMysql")
.master("local[2]")
.getOrCreate()
//todo:2、创建Properties对象,设置连接mysql的用户名和密码
val properties: Properties =new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//todo:3、读取mysql中的数据
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql://192.168.200.100:3306/spark","iplocation",properties)
//todo:4、显示mysql中表的数据
mysqlDF.show()
spark.stop()
}
}
运行结果
通过spark-shell运行
(1)、启动spark-shell(必须指定mysql的连接驱动包)
spark-shell \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar
(2)、从mysql中加载数据
val mysqlDF = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.200.150:3306/spark", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "iplocation", "user" -> "root", "password" -> "123456")).load()
(3)、执行查询

九、SparkSql将数据写入MySql中
通过IDEA编写SparkSql代码
(1)编写代码
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
//todo:需求:通过sparksql把结果数据写入mysql表中
case class People(id:Int,name:String,age:Int)
object Data2Mysql {
def main(args: Array[String]): Unit = {
//1、创建SparkSession
val spark: SparkSession = SparkSession.builder().appName("Data2Mysql").master("local[2]").getOrCreate()
//2、创建SparkContext
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//3、读取数据文件
val data: RDD[Array[String]] = sc.textFile("e:\\person.txt").map(_.split(" "))
//4、rdd与样例类关联
val peopleRDD: RDD[People] = data.map(x=>People(x(0).toInt,x(1),x(2).toInt))
//5、将rdd转换成dataFrame
import spark.implicits._
val peopleDF: DataFrame = peopleRDD.toDF
//打印schema
peopleDF.printSchema()
peopleDF.show()
//注册成一张表
peopleDF.createTempView("people")
val result: DataFrame = spark.sql("select * from people where age >24")
//把结果数据写入到mysql表中
//定义url
val url="jdbc:mysql://192.168.200.100:3306/spark"
//定义table表名
val table="people"
//定义相关属性
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//mode方法:指定数据插入模式
//overwrite:表示覆盖(表不存在,事先帮你创建)
//append: 追加(表不存在,事先帮你创建)
//ignore:忽略 (只要表存在,就不进行任何操作)
//error: 默认选项,如果表存在就报错
result.write.mode("ignore").jdbc(url,table,properties)
//关闭
spark.stop()
}
}
通过spark-shell运行
(1)编写代码
只需把上面代码中的文件来源及表名当做参数传入即可
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
//todo:需求:通过sparksql把结果数据写入mysql表中
case class People(id:Int,name:String,age:Int)
object Data2Mysql {
def main(args: Array[String]): Unit = {
//1、创建SparkSession
val spark: SparkSession = SparkSession.builder().appName("Data2Mysql").getOrCreate()
//2、创建SparkContext
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//3、读取数据文件
val data: RDD[Array[String]] = sc.textFile(args(0)).map(_.split(" "))
//4、rdd与样例类关联
val peopleRDD: RDD[People] = data.map(x=>People(x(0).toInt,x(1),x(2).toInt))
//5、将rdd转换成dataFrame
import spark.implicits._
val peopleDF: DataFrame = peopleRDD.toDF
//打印schema
peopleDF.printSchema()
peopleDF.show()
//注册成一张表
peopleDF.createTempView("people")
val result: DataFrame = spark.sql("select * from people where age >24")
//把结果数据写入到mysql表中
//定义url
val url="jdbc:mysql://192.168.200.100:3306/spark"
//定义table表名
val table=args(1)
//定义相关属性
val properties = new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//mode方法:指定数据插入模式
//overwrite:表示覆盖(表不存在,事先帮你创建)
//append: 追加(表不存在,事先帮你创建)
//ignore:忽略 (只要表存在,就不进行任何操作)
//error: 默认选项,如果表存在就报错
result.write.mode("append").jdbc(url,table,properties)
//关闭
spark.stop()
}
}
(2)提交任务脚本
spark-submit --master spark://node1:7077 --class cn.itcast.sql.Data2Mysql --executor-memory 1g --total-executor-cores 2 --jars /export/servers/hive/lib/mysql-connector-java-5.1.35.jar --driver-class-path /export/servers/hive/lib/mysql-connector-java-5.1.35.jar original-spark_class07-2.0.jar /person.txt person2018
注意:应保证数据库外部访问权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY '123' WITH GRANT OPTION;
flush privileges;
