爬虫是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化,说白了爬虫拿到的就是您网页上的html代码。
新建目录
新建grabTest目录cd grabTest
进入目录npm init
一路回车创建package.json。
安装
request(简化的HTTP客户端)、request-promise(request返回Promise使用async/ await)、cheerio(将抓取页面的html代码转为DOM,可以称之为是node版的jq)npm i request request-promise cheerio
查看package.json文件
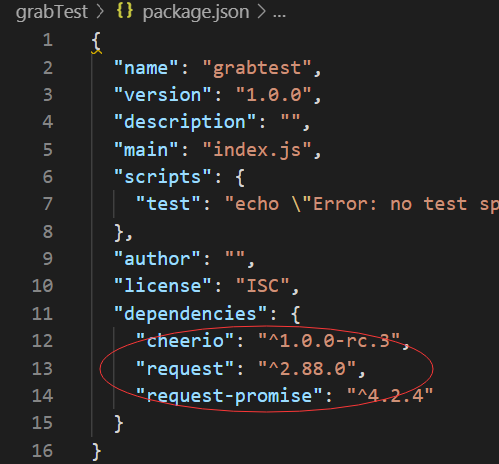
说明安装成功了。
目录下新建read.js//request-promise是让request支持了promise的语法
const rp = require('request-promise');
const cheerio = require('cheerio');
const html_encode = function(str){
var s = "";
if (str.length == 0) return "";
s = str.replace(/&/g, "&");
s = s.replace(/
s = s.replace(/>/g, ">");
s = s.replace(/ /g, " ");
s = s.replace(/\'/g, "'");
s = s.replace(/\"/g, """);
s = s.replace(/\n/g, "
");
return s;
}
const read = (url) =>{
const opts = {
url,// 目标页面
transform:body => {
// body为目标页面抓取到的html代码
// 通过cheerio.load方法可以把html代码转换成可以操作的DOM结构
return cheerio.load(body);
}
};
return rp(opts).then($=>{
let result = [];// 结果数组
//遍历列表标题a标签
$('.itemTitle a').each((index,item) => {
const ele = $(item);
const url = ele.attr('href');
const title = ele.text();
//取a标签href进入内页取文章内容,闭包异步获取
(async function(index){
const $$ = await rp({
url,
transform:body => {
// cheerio中的.html()方法默认开启转换实体编码
// decodeEntities:false关闭转换实体编码
return cheerio.load(body,{decodeEntities:false});
}
});
$$('.article-content script').remove();
$$('.article-content ins').remove();
//html_encode选择性、&等转义成实体编码
result[index].contentText = html_encode( $$('.article-content').html() );
})(index);
result.push({
title
});
console.log(title);
});
// 返回结果数组
return result;
})
};
read('https://www.xinran001.com/');
目录下执行Nodenode read.js
在控制台上就可以看到打印出的文章标题。