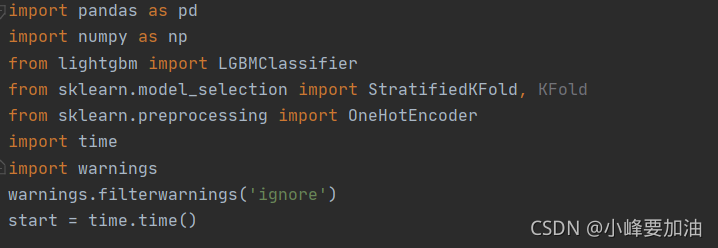
导入相关库:(加了一个测试时间的)
读写入数据:

训练训练集和测试集:

设计模型和输出验证集:
def abs_sum(y_pre, y_tru):
loss = sum(sum(abs(y_pre - y_tru)))
return loss
clf = LGBMClassifier(
learning_rate=0.1, # 0.05
n_estimators=10230,
num_leaves=31,
max_depth=7,
subsample=0.8,
colsample_bytree=0.8,
metric=None,
objective='multiclass'
)
answers = []
mean_score = 0
onehot_encoder = OneHotEncoder(sparse=False)
sk = StratifiedKFold(n_splits=10, shuffle=True, random_state=2019)
for train, testA in sk.split(train_x, target):
x_train = train_x.iloc[train]
y_train = target.iloc[train]
x_test = train_x.iloc[testA]
y_test = target.iloc[testA]
clf.fit(x_train, y_train, eval_set=[(x_test, y_test)], verbose=100,
early_stopping_rounds=100)
y_pre = clf.predict(x_test)
y_test = np.array(y_test).reshape(-1, 1)
y_test = onehot_encoder.fit_transform(y_test)
y_pre = np.array(y_pre).reshape(-1, 1)
y_pre = onehot_encoder.fit_transform(y_pre)
print('lgb验证的auc:{}'.format(abs_sum(y_test, y_pre)))
mean_score += abs_sum(y_test, y_pre) / 10
y_pred_valid = clf.predict_proba(test1)
answers.append(y_pred_valid)
print('mean valAuc:{}'.format(mean_score))
lgb_pre = sum(answers) / 10
re = pd.DataFrame(lgb_pre)
result = pd.read_csv('E:/yangben1/sample_submit.csv')
result['label_0'] = re[0]
result['label_1'] = re[1]
result['label_2'] = re[2]
result['label_3'] = re[3]
result.to_csv('E:/yangben31/submit.csv', index=False)
end = time.time()
print (end-start)总结:
此算法在心跳信号分类预测-baseline中正确率、训练时间、绝对值误差都是比较好的,在后期的优化上可以更好。(新人入坑)
版权声明:本文为weixin_50965383原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。