Python爬取图虫网美女图片实战
1.前戏
本人是爬虫初学者,练手网站都是在b站上搜索爬虫,然后找的练手网站,这次也不例外.
发现一个吸引人的封面:
然后打开视频,暂停提取目标网站:https://tuchong.com/tags/美女
但是,由于技术不熟练,直接请求这个网站返回的源代码里没有东西,就又返回b站学习了下如何利用浏览器的抓包工具
找到了所需的url:
https://tuchong.com/rest/tags/%E7%BE%8E%E5%A5%B3/posts?page={u}&count=20&order=weekly&before_timestamp=
2.代码实现
所需模块
import re,requests
import bs4
import time,random
发送请求
url=’ ’
ualist=[‘一个ua池’]
#从请求池里随机获取一个请求头
headers = {
“user-agent”: random.choice(ualist),
}
resp=requests.get(url,headers)
提取图片的一级页面链接
ids=re.findall(r’“post_id”:"(.*?)",“type”’,resp.text)
imglink=[]
for imgs in ids:
imglink.append(‘https://zhudefeng.tuchong.com/’+f’{imgs}’)
提取图片的二级页面链接并保存
for link in imglink:
resp_link=requests.get(url=link,headers=headers)
exScoup = bs4.BeautifulSoup(resp_link.text, “html.parser”)
img_link = exScoup.select(‘img[class=“multi-photo-image”]’)
img = re.findall(r’src="(.*?)"/>’, str(img_link))
- 命名
link_name = exScoup.select(‘meta[name=“title”]’)
img_name = re.findall(r’content="(.*?)"’, str(link_name))
- 保存
count=0
count += 1
with open(f’D:/Users/best/{img_name[0]}{count}.jpg’, mode=‘wb’) as f:
f.write(ii.content)
time.sleep(0.2)
print(f"第{count}张下载完成")
3.代码及运行结果
完整代码
import re,requests
import bs4
import time,random
#这里page={},count= 都可以修改
for u in range(1,11):
url=f'https://tuchong.com/rest/tags/%E7%BE%8E%E5%A5%B3/posts?page={u}&count=20&order=weekly&before_timestamp='
ualist = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3872.400 QQBrowser/10.8.4455.400",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:23.0) Gecko/20131011 Firefox/23.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.90 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1623.0 Safari/537.36",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; nb-NO) AppleWebKit/533.18.1 (KHTML, like Gecko) Version/5.0.2 Safari/533.18.5",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.14 (KHTML, like Gecko) Chrome/24.0.1292.0 Safari/537.14",
"Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; Zune 4.7)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; rv:21.0) Gecko/20130326 Firefox/21.0",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.2 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130401 Firefox/21.0",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
"Mozilla/5.0 (Windows x86; rv:19.0) Gecko/20100101 Firefox/19.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1309.0 Safari/537.17",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0 Safari/605.1.15",
]
#随机选取一个请求头,简单模拟浏览器
headers = {
"user-agent": random.choice(ualist),
}
resp=requests.get(url,headers)
#提取图片主链接
ids=re.findall(r'"post_id":"(.*?)","type"',resp.text)
imglink=[]
for imgs in ids:
imglink.append('https://zhudefeng.tuchong.com/'+f'{imgs}')
#提取单个图片地址
for link in imglink:
count=0
resp_link=requests.get(url=link,headers=headers)
exScoup = bs4.BeautifulSoup(resp_link.text, "html.parser")
link_name = exScoup.select('meta[name="title"]')
#取出图片名字
img_name = re.findall(r'content="(.*?)"', str(link_name))
print(f"正在下载<{img_name}>图片合集")
img_link = exScoup.select('img[class="multi-photo-image"]')
img = re.findall(r'src="(.*?)"/>', str(img_link))
#下载图片
for i in img:
ii=requests.get(i)
try:
count += 1
with open(f'D:/Users/best/{img_name[0]}{count}.jpg', mode='wb') as f:
f.write(ii.content)
#添加睡眠时间,防止反爬
time.sleep(0.2)
print(f"第{count}张下载完成")
except:
print('下载失败!')
resp.close()
print("All over!")
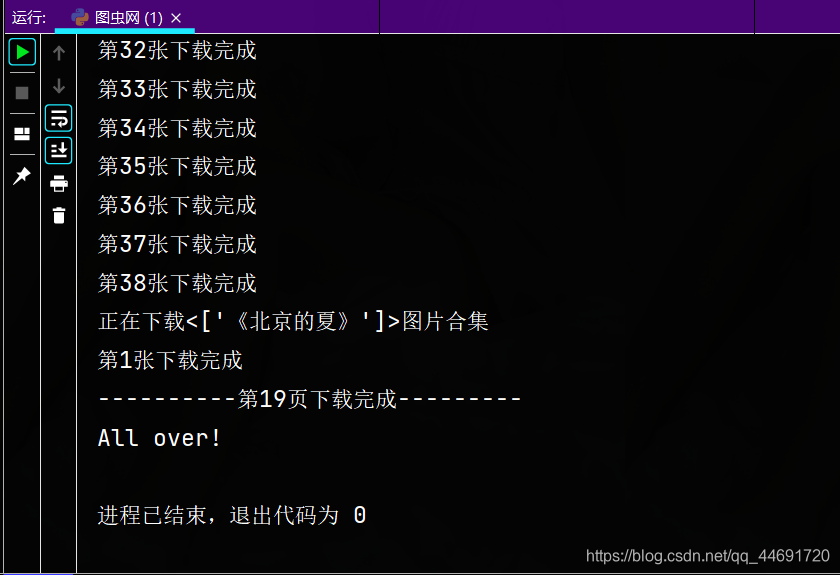
运行结果
4.成品欣赏

1200+图片,其中爬多少页也可以自己修改