前言
原论文地址:Fast R-CNN
Faster R-CNN合集:
总体架构

算法流程
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 将图像输入网络得到相应的特征图,将SS(Selective Search)算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
(ROI:Region of Interest 感兴趣区域)
与R-CNN的不同
在R-CNN中,我们分别训练了SVM分类器(预测目标所属的类别)和BBox回归器(调整候选区域边界框)。而在Fast R-CNN中,将这两种功能结合到一个网络当中,这就不用单独训练分类器和回归器了。
R-CNN依次将每个候选框区域输入到卷积神经网络中得到特征(如下图),这就是需要2000次正向传播,但这2000个候选框中有大量冗余,很多区域都重叠了,计算一次就可以的事情R-CNN一直在重复地做。
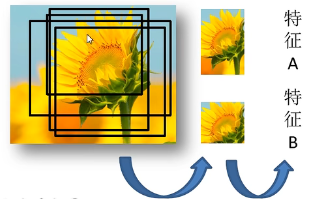
Fast R-CNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域(参考SPP Net)。这些候选区域的特征不需要再重复计算。
训练数据的采样
通过SS算法可以得到2000个候选框,但在训练时只使用一小部分就可以了。且数据分为正样本和负样本,正样本就是候选框中确实存在我们需要检测的目标,负样本就是候选框没有我们要检测的目标(可以理解成背景)。
- 为什么需要分正负样本?
- 假如我想要判别猫和狗,若全是正样本,数据集样本不平衡,猫的样本数量远大于狗,那么训练出来的网络在预测时就更偏向于判定为猫,这样肯定是不对的。放到目标检测中,若全是正样本,即便候选框中是一个背景,网络也会强行把它认为成一个我们检测的一个类别中。
在原论文中,作者提出对于每张图片,从2000个候选框中采集64个候选区域。对于每个候选区域,它与真实框(ground-truth)的 IoU 大于0.5,那么就把他划分成正样本,把与每个真实框的 IoU 的最大的值在0.1~0.5的认定为负样本。
RoI pooling

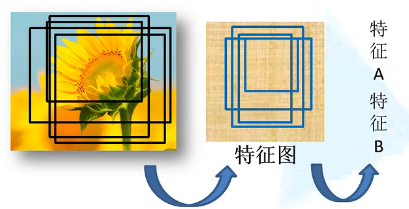
有了候选区域样本之后,使用RoI pooling将每个样本缩放成统一的尺寸。
如下图,将图片划分成7×7等分,对于每一小块区域执行最大池化(max pooling)操作,这样就得到了一个7×7的特征矩阵。无论候选区域的尺寸是多大的,都将缩放成7×7矩阵,这就不限制输入图像的尺寸(与R-CNN不同,R-CNN要求输入图像尺寸为227×227)。

分类器

输出 N+1 个类别的概率(N为检测目标的种类,1为背景)共 N+1 个结点。分类器即上图中蓝色框部分,全连接层(FC)即需要 N+1 个结点。
边界框回归器
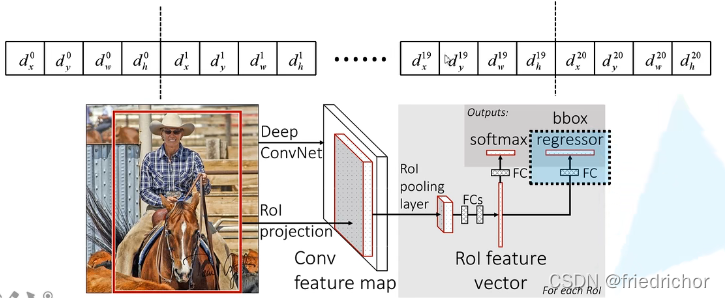
输出对应 N+1 个类别的候选边界框回归参数( d x , d y , d w , d h ) (d_x,d_y,d_w,d_h)(dx,dy,dw,dh),共 (N+1)×4 个结点。
那么怎么用回归参数来预测的呢?
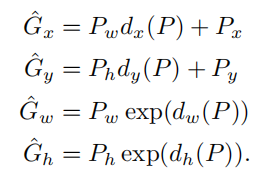 \quad\quad\quad
\quad\quad\quad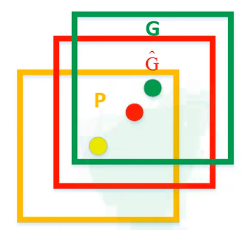
其中,P x , P y , P w , P h P_x,P_y,P_w,P_hPx,Py,Pw,Ph分别为候选框的中心x , y x,yx,y坐标以及宽高
G x ^ , G y ^ , G w ^ , G h ^ \hat{G_x},\hat{G_y},\hat{G_w},\hat{G_h}Gx^,Gy^,Gw^,Gh^分别为最终预测的边界框中心x , y x,yx,y坐标以及宽高
根据上面的公式可以看出d x , d y d_x,d_ydx,dy就是用来调整边界框中心位置的,d w , d h d_w,d_hdw,dh用来调整宽高,从而把黄色区域调整到红色区域。
Multi-task loss

p pp是分类器预测的 softmax 概率分布p = ( p 0 , . . . , p k ) p=(p_0, ..., p_k)p=(p0,...,pk),p 0 p_0p0即是预测为背景的概率,以此类推
u uu对应目标真实类别标签
t u t^utu对应边界框回归器预测的对应类别u uu的回归参数( t x u , t y u , t w u , t h u ) (t_x^u,t_y^u,t_w^u,t_h^u)(txu,tyu,twu,thu)
v vv对应真实目标的边界框回归参数( v x , v y , v w , v h ) (v_x,v_y,v_w,v_h)(vx,vy,vw,vh)
分类损失:
使用交叉熵损失,原文使用如下公式:
p pp是分类器预测的 softmax 概率分布p = ( p 0 , . . . , p k ) p=(p_0, ..., p_k)p=(p0,...,pk),p 0 p_0p0即是预测为背景的概率,以此类推
u uu对应目标真实类别标签
交叉熵损失:
假设真实标签的one-hot编码是[0,0,…,1,…,0],预测的softmax概率为[0.1,0.3,…,0.4,…,0.1],那么L o s s = − log ( 0.4 ) Loss=-\log(0.4)Loss=−log(0.4)
边界框回归损失:
u uu对应目标真实类别标签
t u t^utu对应边界框回归器预测的对应类别u uu的回归参数( t x u , t y u , t w u , t h u ) (t_x^u,t_y^u,t_w^u,t_h^u)(txu,tyu,twu,thu)
v vv对应真实目标的边界框回归参数( v x , v y , v w , v h ) (v_x,v_y,v_w,v_h)(vx,vy,vw,vh)
其中,[ u ≥ 1 ] [u\geq1][u≥1]是艾佛森括号,当u ≥ 1 u\geq1u≥1时,这个值为1,u < 1 u<1u<1时即为0。u ≥ 1 u\geq1u≥1时,说明这是检测目标中的一个类别,这就是正样本;u < 1 u<1u<1时(即u = 0 u=0u=0),就说明是负样本,那么损失函数中就没有边界框回归损失这一项。
至于( v x , v y , v w , v h ) (v_x,v_y,v_w,v_h)(vx,vy,vw,vh)是如何计算的,同样使用到了下图。\quad\quad\quad
v x = ( G x − P x ) / P w v_x=(G_x-P_x)/P_wvx=(Gx−Px)/Pw,同理v y = ( G y − P y ) / P h v_y=(G_y-P_y)/P_hvy=(Gy−Py)/Ph
v w = ln ( G w / P w ) v_w=\ln(G_w/P_w)vw=ln(Gw/Pw),同理v h = ln ( G h / P h ) v_h=\ln(G_h/P_h)vh=ln(Gh/Ph)

展开,上式 = s m o o t h L 1 ( t x u − v x ) + s m o o t h L 1 ( t y u − v y ) + s m o o t h L 1 ( t w u − v w ) + s m o o t h L 1 ( t h u − v h ) =smooth_{L1}(t_x^u-v_x)+smooth_{L1}(t_y^u-v_y)+smooth_{L1}(t_w^u-v_w)+smooth_{L1}(t_h^u-v_h)=smoothL1(txu−vx)+smoothL1(tyu−vy)+smoothL1(twu−vw)+smoothL1(thu−vh)

关于损失函数的学习,可以参考:回归损失函数1:L1 loss, L2 loss以及Smooth L1 Loss的对比
Fast R-CNN框架

对比于R-CNN的四部分框架,Fast R-CNN只包含两部分。第一部分就是SS算法获取候选框,第二部分将特征提取、分类、BBox回归融合到一个CNN网络

参考来源:1.1Faster RCNN理论合集